


17. 大数据关联查询
文件 RegisterSiteA.csv 中存储了某次考试的报名信息,数据量比较大。考生信息存储在另一个大数据文件 candidates.csv 中,存储了所有考生的 ID,NAME 以及所在的 CITY 和 STATE。文件 ExamLevel.txt 中是有关考试级别的安排,其中包含各个州中设置的考试级别,每个州最多只安排一个级别的考试。请查询,报名的第 1000~1100 名考生的报名信息,并在结果中增加 SAME 字段来判断他们是否能在本州参与所报级别的考试。
参考答案:
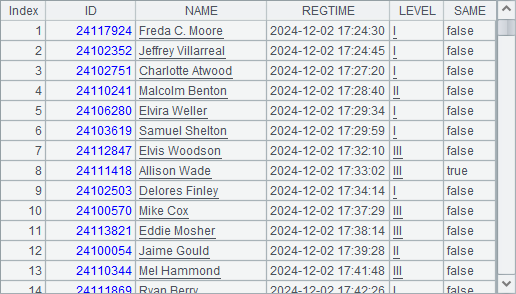
解答:
| A | B | C | |
|---|---|---|---|
| 1 | RegisterSiteA.csv | candidates.csv | ExamLevel.txt |
| 2 | =file(A1).cursor@ct().sortx(ID) | =file(B1).cursor@ct() | =T(C1).keys(STATE) |
| 3 | =B2.switch(STATE,C2) | ||
| 4 | =joinx(A2:Reg,ID;B3:Info,ID) | =A4.new(Reg.ID:ID, Reg.NAME:NAME, Reg.REGTIME:REGTIME, Reg.LEVEL: LEVEL, Reg.LEVEL == Info.STATE.LEVEL:SAME) | |
| 5 | =B4.sortx(REGTIME) | >A5.skip(1000) | =A5.fetch@x(100) |
A2 和 B2 用数据文件创建游标,由于需要将报考数据与考生信息相关联,因此需要它们的关联字段是有序的,即需要它们关于 ID 有序,其中 RegisterSiteA.csv 中的数据不满足要求。因此,A2 在生成游标后需要用 cs.sortx() 将其按 ID 排序。
C2 读出考试安排信息表,这个数据并不会是大数据,直接读为内存序表即可:
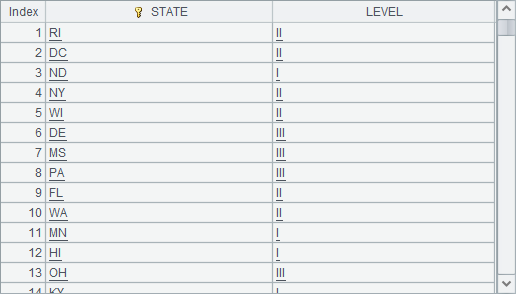
B3 将考生信息中的 STATE 与考试安排做关联,用来查询考生所在州安排的考试级别。
A4 用 joinx() 将报考数据游标,与考生信息游标做连接,报考数据为 Reg,考生信息为 Info。B4 用连接得到的游标准备所需返回的结果,其中 ID,NAME,REGTIME 和 LEVEL 从报考数据 Reg 中取得,而是否可以在本州考试,需要根据 Reg 和 Info 中的 LEVEL 是否一致来计算。
由于最终所需的结果是按报考时间排序的,因此在查询最终结果前,还需要用 cs.sortx() 根据报考时间排序。需要了解的是,A2 中排序是为了执行游标连接所需要的,而 A5 中的排序是取得结果所需要的,它们在执行时都会立即计算,而计算需要取得所有数据后,才能使用缓存去完成所需的排序,耗时也会较长。
B5 跳过前 1000 位报名最早的考生信息后,C5 中即可返回第 1001 至 1100 名报名的考生数据。
在 B3 中将游标与内存表做关联时,实际上只是需要获知考场安排表中对应的级别,因此也可以将 B3 中代码改为 =B2.join(STATE,C2,LocalLEVEL),通过连接内存表,在游标中增加本地考试级别的字段 LocalLEVEL。如果这样的话,在 B4 中生成 SAME 字段时,所需做的判断也需对应改为 Reg.LEVEL=Info.LocalLEVEL。


英文版