


15. 可变分栏显示数据
文件 RegisterSiteA.csv 中存储了某次考试的报名信息,数据量比较大。选出其中 12 月 1 日报名的人员,将他们的 ID 和 Name 展示出来,要求按给定的 cols 变量,在一行中显示多栏,如 cols=3,则每行记录 3 个人员的信息,列名分别为 ID1,NAME1,ID2,,NAME2,ID3,NAME3。
参考答案:
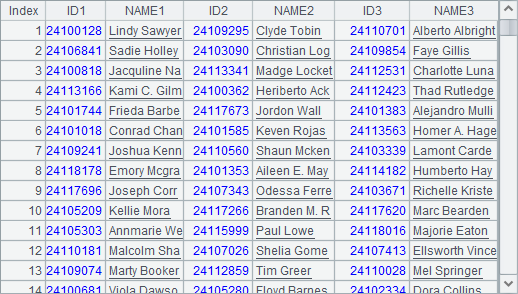
解答:
| A | B | C | |
|---|---|---|---|
| 1 | =file(“RegisterSiteA.csv”).cursor@ct(ID, NAME) | 3 | =B1*100 |
| 2 | =B1.([“ID”/#,“NAME”/#]).conj() | =create(${A2.concat@c()}) | =B1.(“B4(”/#/“).m(#B5).ID,B4(”/#/“).m(#B5).NAME”).concat@c() |
| 3 | =A1.select(string(REGTIME, “MMdd”)==“1201”) | ||
| 4 | for A3,C1 | =B1.(A4.step(B1,#)) | |
| 5 | for B4(1) | >B2.insert(0,${C2}) |
所需分栏的变量,在这里直接填入了 B1,如果需要变动可以直接修改。由于这里是处理大数据问题,因此 A1 中定义了文件游标,在 C1 中根据分栏数决定每次读入的数据条数。A2 根据所需分栏,生成结果表的标题,由于需要将数据类型不同的字符串和数值拼接为串,因此使用了字符串连接符 /,计算后结果如下:
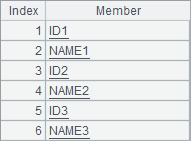
B2 中据此创建新序表,由于列名不定,这里用到了宏,即用 A2 拼成的字串拼在表达式中再解析执行。类似的,在向序表中填充数据时,也需要考虑列名不定的问题,在 C2 中预先准备了填充数据时所需的表达式部分,其中 #B5 表示 B5 循环时对应的序号。另外,由于分栏不一定能填满,所以这里从 B4 拆分的各个分栏数据中取数时,用到了 A.m(n) 而不是 A(n) 用来防止 n 超限。
A3 从游标中选出所需日期的记录,这里用 string(dt, ftm) 函数,直接从注册时间中获取月日部分来做判断。A4 从游标中循环取数,每次按 C1 中的条数获取。在 B4 中用 step 函数将结果分为 B1 栏。B5 中,循环第 1 栏的数据,在 C5 中再次通过使用宏,拼出 insert 表达式,根据所有栏的对应数据填充到序表。
执行后,可以在 B2 中看到最终结果。这里认为分栏后的数据能够在内存序表中,如果结果数据仍然是大数据,那么需要在 A4 的循环区块中,用 f.write@a() 写 出到文件。


英文版