


esProc 在结构化文本文件上用简单 SQL 查询
esProc在结构化文本文件上用简单SQL查询
结构化文本文件是指以tab分隔的TXT文件或是逗号分隔的csv文件,这类文件可以看成是数据表。使用esProc 中的简单SQL可以方便地应用到这类文件上,避免导入数据库的麻烦。
本文用文本文件举例,但同时也适用于Excel文件,假定文件第一行都是标题。
A |
B |
|
1 |
$select * from scores.txt where |
// filter |
2 |
$select avg(Chinese),max(Math),sum(English) from scores.txt |
// aggregation |
3 |
$select *,English+Chinese+Math as total_score from scores.txt |
// compute column |
4 |
$select *, case when English>=60 then 'Pass' else 'Fail' end as English_evaluation from scores.txt |
// case |
5 |
$select * from scores.txt order by CLASS,English+Chinese+Math desc |
// sort |
6 |
$select top 3 * from scores.txt order by English desc |
// top-N |
7 |
$select CLASS,min(English),max(Chinese),sum(Math) from scores.txt group by CLASS |
// group aggregation |
8 |
$select CLASS,avg(English) as avg_En from scores.txt group by CLASS having avg(English)<85 |
// group filter |
9 |
$select distinct CLASS from scores.txt |
// distinct |
10 |
$select count(distinct CLASS) from scores.txt |
// count distinct |
11 |
$select CLASS,count(distinct English) as num_de from scores.txt group by CLASS |
// group count distinct |
12 |
||
13 |
$select sum(S.quantity*P.Price) as total from sales.csv as S join product.csv as P on S.productid=P.ID where S.quantity<=50 |
// 2 files join |
14 |
$select s.ID,c.cname,p.name,s.Date,s.Quantity,p.Price,c.borth,c.state from sales.csv as s join product.csv as p on s.ProductID=p.ID join customer.txt as c on s.CustomerID=c.cid where c.borth<date("2000-01-01") |
// multiple files join |
15 |
$select s.ID,c.cname,p.name,s.Date,s.Quantity,p.Price,c.state from sales.csv as s |
// subquery |
16 |
$with A as (select cid from customer.txt where state in ('Texas','California','Florida') ) |
// with |
https://try.esproc.com/splx?35K
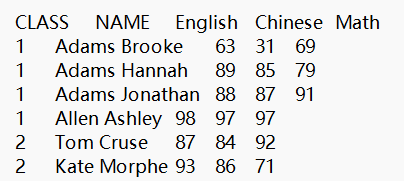
A1 从学生成绩表scores.txt中筛选出2班的学生成绩,文件中第一行是列名,第二行开始是数据,如下图所示。
A2 计算学生成绩表中全体学生的语文平均分、数学最高分、英语总分。
A3 计算学生成绩表中每位学生的总分。
A4 计算学生成绩表中每位同学的英语成绩是否及格。
A5 将学生成绩表按照班号升序、总分降序的顺序排列。
A6 查看英语成绩最高的3个同学成绩。
A7 查询各班的英语最低分、语文最高分、数学总分。
A8 找出英语平均分低于85分的班级。
A9 查询所有班级编号。
A10 统计共有多少个不同编号的班级。
A11 按班级分组,统计各班英语成绩不重复的个数。
A13 销售信息和产品信息分别存储在两个csv文件中,计算每单销售数量小于50产品的总销售额。
A14 多个文件关联查询,查询出生日期小于2000-01-01顾客的订单信息。
A15 多个文件关联查询,并用子查询结果作为过滤条件,查询最年轻顾客的订单信息。
A16 with子句,查询指定州顾客中,每种产品的订单数量、订单总金额


大佬,简单 sql 读 excel 文件,只能读默认的第一个 Sheet 吧?如果一个工作簿中有多个 Sheet 有数据,能否用简单 sql 读取指定的 Sheet?
英文版
查询 excel 文件中的其它 sheet 也是可以的,写法为:
$select * from {file(“d:/a1.xlsx”).xlsimport@t (;2)}
{} 里是 SPL 定义的表,参数 2 表示第 2 个 sheet
谢谢大佬…这样写以前在论坛文章中见到过,因为读取数据很慢,没把{file.xlsimport@t ()}这种方法当回事,彻底忘记了。
哎,只要跟 excel 扯上关系都不会快。多 sheet 的工作簿还是把工作簿当数据库来连算了,虽然也很慢。