


esProc SPL 在结构化文本文件上的常规运算
esProc SPL在结构化文本文件上的常规运算
结构化文本文件是指以tab分隔的TXT文件或是逗号分隔的csv文件,这类文件可以看成是数据表。使用esProc SPL能够很方便地对这类文件进行常见的SQL式运算。
这里假定文件第一行是字段标题。
A |
B |
|
1 |
=T("scores.txt") |
|
2 |
=A1.select(CLASS==2) |
// filter |
3 |
=A1.avg(Chinese) |
|
4 |
=A1.max(Math) |
|
5 |
=A1.sum(English) |
|
6 |
=A1.derive(English+Chinese+Math:total_score) |
// derive a total_score column |
7 |
=A1.derive(if(Chinese>=90:"A",Chinese>=80:"B",Chinese>=60:"C";"D"):Chinese_evaluation) |
// evaluate Chinese score |
8 |
=A1.sort(English) |
|
9 |
=A1.sort(CLASS,-Math) |
|
10 |
=A1.groups(CLASS;min(English),max(Chinese),avg(Math)) |
|
11 |
=A1.groups(CLASS;avg(English):avg_En).select(avg_En<85) |
|
12 |
=A1.top(-3;English) |
// Top 3 high English students |
13 |
=A1.groups(CLASS;top(3,English)) |
// Top 3 low English value in CLASS |
14 |
=A1.id(CLASS) |
// distinct CLASS |
15 |
=A1.icount(CLASS) |
// count distinct CLASS |
16 |
=A1.groups(CLASS;icount(English)) |
// count distinct English every CLASS |
17 |
||
18 |
=T("sales.csv") |
|
19 |
=T("product.csv").keys(ID) |
// ID as key |
20 |
=A18.switch(ProductID,A19:ID) |
// ProductID join ID |
21 |
=A20.derive(Quantity*ProductID.Price:amount) |
|
22 |
||
23 |
=T("sales.csv") |
|
24 |
=A23.join(ProductID,A19:ID,Name,Price) |
// import Name, Price join on ProductID=ID |
25 |
=A24.derive(Quantity*Price:amount) |
https://try.esproc.com/splx?2Xx
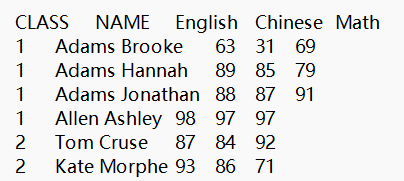
A1 读学生成绩表scores.txt数据为序表,文件中第一行是列名,第二行开始是数据,如下图所示。
A2 选出班级为2的数据记录
A3 计算语文平均分
A4 计算数学最高分
A5 计算英语总分
A6 在A1中新增一列total_score,其值为英语、语文、数学3列之和
A7 在A1中新增一列Chinese_evaluation,当语文成绩在90以上时评级为A,80以上时评级为B,60以上时评级为C,否则评级为D。
A8 按英语成绩升序排列
A9 先按班级号升序排列,班级内再按数学成绩降序排列
A10 按班级分组,计算各班英语最低分、语文最高分、数学平均分
A11 按班级分组,计算各班英语平均分,选出平均分低于85的班级
A12 按英语降序排列后,取出前3个英语成绩最高的同学成绩记录
A13 按班级分组,各班英语升序排列后,取出前3个最低的英语成绩去重和去重计数
A14 查出所有不重复的班级编号
A15 查出所有不重复的班级编号的个数
A16 按班级分组,查出各班所有不重复英语成绩的个数
A18 读销售数据表sales.csv为序表
A19 读产品数据表product.csv为序表,并设ID为主键
两表结构如下:
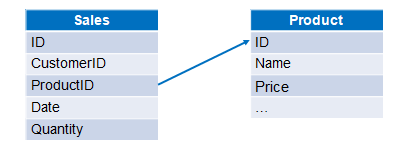
A20 用switch函数将A18中ProductID与A19中的ID进行关联(ID为主键时也可省略不写),此时ProductID列转换成了指向与它对应的产品记录。如果从A20中取出部分数据,将如下图所示
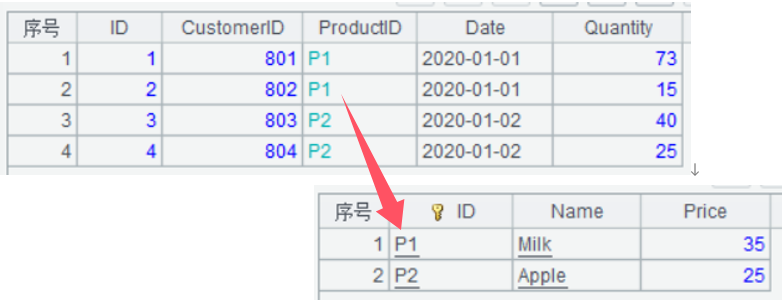
A21 A20中新增一列amount,其值为销售数量Quantity与产品价格Price的积,表达式ProductID.Price表示ProductID列指向的记录的Price列值
A23 重读销售数据表sales.csv为序表
A24 用join函数将A23中ProductID与A19中的ID进行关联(ID为主键时也可省略不写),同时引入A19中Name、Price列数据。如果取出A24中部分数据,将如下图所示

A25 A24中新增一列amount,其值为销售数量Quantity与产品价格Price的积


英文版