




功夫都在报表外,润乾报表为什么性能更好
报表性能是个重要事情,出现性能问题,会极度影响用户体验,实施方也总会被牵连,总得没完没了的安排精锐部队去救火,被拖累的苦不堪言
所以解决好性能问题,是报表的重中之重
报表的呈现周期,大致可以分为这 4 个环节
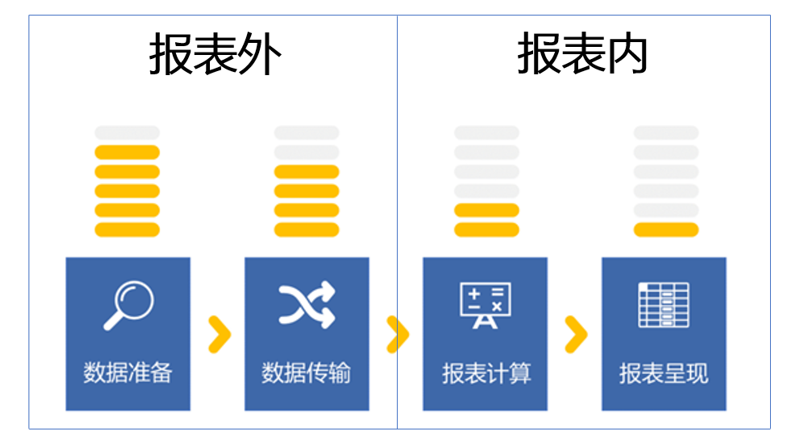
这 4 个环节都有可能造成报表的性能问题,但概率较高的是前两个环节,数据准备和数据传输
这两个环节严格意义上讲其实并不属于传统报表工具的功能范畴,而是数据源本身的问题,所以大部分报表工具也并没有去管这两个环节,然而这却是报表性能问题频出的主要原因
润乾报表,正是因为解决了报表外这两个环节的性能隐患,才让自己的性能远远优于同类产品的,当然它报表内的性能也很优秀
数据准备阶段的性能方案
报表中展现的数据大部分情况下并不是从数据来源中直接取就可以,大都需要经过计算处理加工,准备好以后,才能被报表工具来使用
这些数据准备,多数是用 SQL 或存储过程来做的,一些涉及库外数据来源和计算的,可能会用其他的高级语言去处理
当这个过程出现性能问题时,首先要做的是去优化这些数据准备的代码,比如优化 SQL, 存储过程或者 JAVA
优化后如果还不行,那可能就得给数据库升级配置,扩容,甚至是换性能更好的数据库了,但这样做成本太高,动静太大,风险也很大
而润乾报表中则提供了全新的解决方案
它用独有的数据准备层:SPL 脚本来做数据准备,SPL 是一种拥有高效算法的程序语言,相比于传统的数据准备方法,它有如下优势
1 高效算法算的更快
它在很多场景下本身就比 SQL,存储过程要算的快,用它去做数据准备,出性能问题的概率就低很多
举个简单的例子,要在 1 亿条数据中取出前 10 名,大部分数据库都有优化器来优化,不用做大排序,性能就还不错,但如果查询稍变的复杂一些,比如每个分组中取前 10 名,就需要用到窗口函数和子查询,优化器就犯晕了,又得去做大排序了,性能就会骤降
SPL 则不然,SPL 中有普遍集合的概念,TopN 这种运算被认为是和 SUM 和 COUNT 一样的聚合运算,只不过返回值是个集合,用 SPL 去做个这个计算的时候就不需要做大排序了,速度就会快出很多
这个算法例子只是冰山一角,SPL 还有很多实际的提升性能的案例
某电商的用户行为漏斗分析,用传统方法需要借助多个子查询和反复关联完成,性能低下,改用 SPL 后,在高效算法:有序计算的加持下,性能有了大幅度的提升,从原先的 3 分钟,变成了 10 秒
某保险公司团体保险明细用传统的方式查询慢,包含 1 万人的保单,返回页面需要 7.5 分钟,包含 100 万人的大保单,4 个小时页面都没出来,改用 SPL 后,用全新的延迟游标、游标有序分段取出、程序游标等机制,极大的提升了查询的性能,原来返回页面等待了 4 个小时没有出来,优化后的报表首页仅 7 秒即可展现出来,响应速度提高了 2000 倍还多
更多的性能优化案例可参考: 2 SPL 应用开发
2 高效存储不用扩容
如果用了 SPL 做计算,数据库压力依然大,依然有性能问题,那 SPL 数据准备层,还有高招,它还有高效的数据存储方式
可以把给数据库造成压力的数据放到库外去存,把占用资源的复杂计算挪到库外去算,报表涉及的数据,基本都是历史数据,把这些数据换一种更高效的方式存储,可行性很强,搬出去处理还能获得更高的 IO 性能,不仅释放了数据库资源,节省了升级配置和扩容的成本,还算的更快了
如果报表中不仅有历史数据,还需要热数据、实时数据一起算,那也没问题,SPL 支持各种混合计算,能做到历史数据和实时数据 T+0 的实时报表
3 将报表内计算移出到准备阶段
数据准备层还可以帮助报表内的计算提升性能,把一些报表内原先算的慢的,挪到数据准备层来快速算完
比如要在报表里做多源关联,我们需要写一个类似这样的表达式 ds2.select(ID==ds1.ID),表达式很简单,但是计算复杂度却是平方级的,数据量不大时,都没问题,数据量稍大时,到几千行,那性能就会急剧下降了,再好的工具处理这样的运算也会有问题
但如果把这个关联放到报表外的 SPL 数据准备层来做,就可以使用低复杂的 HASH 算法(而在报表工具中无法对多个数据源先统一处理,实现不了这种算法),那性能就会大幅度的提升了
以下是我们在数据量比较大时,用润乾报表单独运算和 SPL+ 润乾报表协同运算的性能对比,可以看出,报表内的计算性能问题,如果有外部 SPL 数据准备层协助,会有很大程度的提升
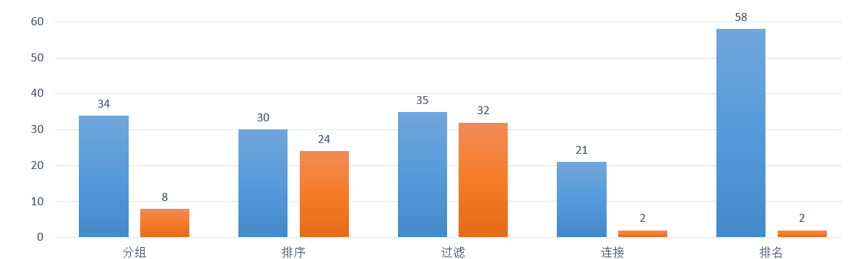
(蓝色是润乾报表单独运算的时间,橙色是 SPL+ 润乾报表协同运算的时间)
数据传输阶段的性能方案
报表项目大部分都是 JAVA 应用,基本都得通过 JDBC 来取数、做数据传输,有时候我们会发现,SQL 很简单,数据库负担也很轻,但数据传输到报表却需要很长时间,传输完成后,报表也算的很快,那就可以判定,就是有些数据库的 JDBC 取数太慢,导致了性能问题
可厂商的 JDBC 我们是没办法修改的,那就只能曲线救国,单线程取的慢,我们可以尝试多线程并行取
但并行取数涉及的数据分段方法和数据库取数语法需要较复杂代码控制,并不容易做成报表功能,所以目前的报表工具基本都不支持并行取数,那就只能眼睁睁看着它慢了
而润乾报表的 SPL 数据准备层则可以轻松支持并行计算
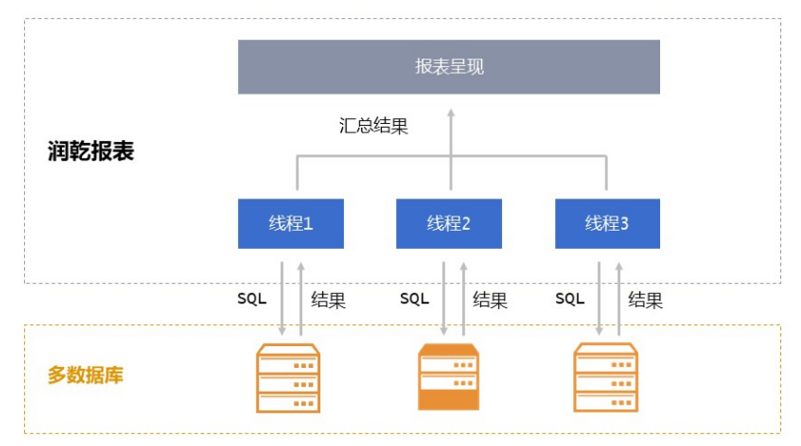
下面就是 SPL 并行取数的代码,写起来还是很简单的,也容易理解
| A | B | |
|---|---|---|
| 1 | =now() | // 记录开始时间 |
| 2 | =connect(“oracle”).query@1x(“SELECT COUNT(*) FROM CUSTOMER”) | |
| 3 | >n=12 | // 设置并行数,根据电脑的物理 CPU 核数决定 |
| 4 | =n.(range(1,A2+1,~:n)) | // 按总记录数和并行数分段,记录本段开头和下段开头数字 |
| 5 | fork A4 | =connect(“oracle”) |
| 6 | =B5.query@x(“SELECT * FROM CUSTOMER WHERE C_CUSTKEY>=? AND C_CUSTKEY<?”,A5(1),A5(2)) | |
| 7 | =A5.conj() | // 合并取数结果 |
| 8 | =interval@s(A1,now()) | // 计算运行时间 |
在数据库负担不重时,并行取数几乎可以让传输效率得到线性的提升
另外,数据传输慢,我们也可以通过数据外存的方式来解决,刚才我们已经说过,SPL 有更高效的二进制存储方式,存成文件后 IO 性能也远比数据库好,同时再配合上并行取数,那传输的速度就更快了
附上一个并行取数和单线程取数的性能测试对比,感兴趣的同学可以去看看: JDBC 取数到底有多慢
把报表外这俩环节的性能问题都解决了,占大头的 80% 的性能问题就都解决了
剩下的 20%,就看报表内的能力了
报表内的性能
报表内涉及性能的环节主要是报表计算,和报表渲染呈现,这两方面润乾积累的也非常深厚,计算引擎优化的很好,也有很大的优势
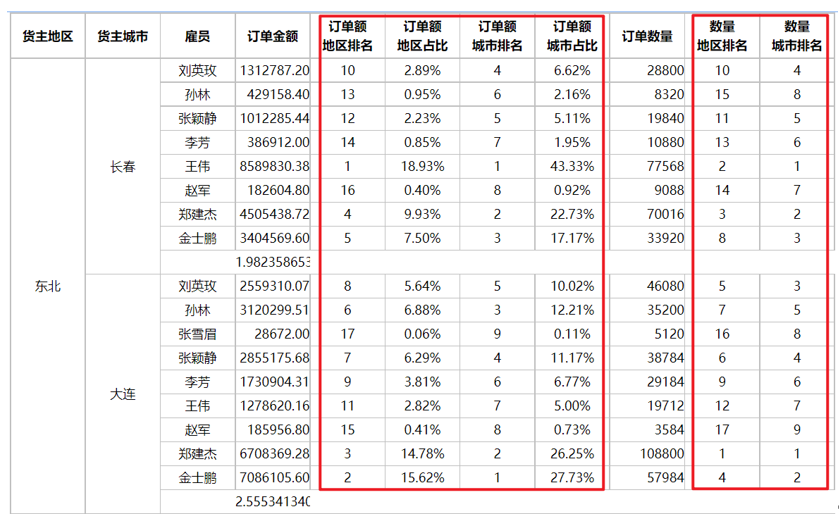
比如这个报表中的各种排名占比,就能很好的体现报表工具格间计算的能力
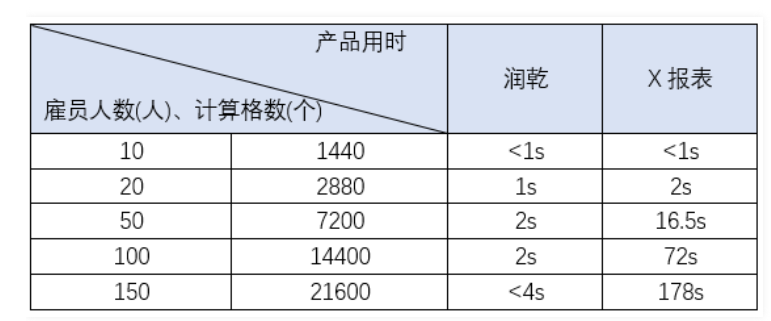
把这个报表的数据量不断加大以后,和同类产品比,润乾报表计算的优势就完全体现出来了
润乾页面呈现渲染的优势同样也很大
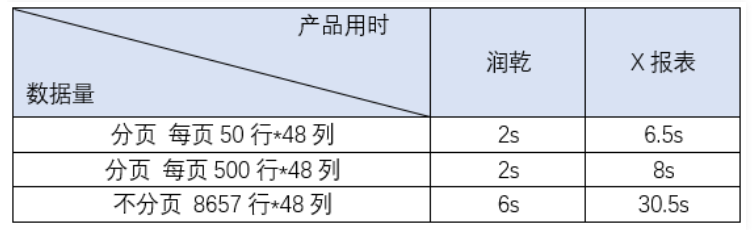
呈现的数据越多,润乾的性能越好
总结
涉及报表性能的四个环节,有两个在报表内,两个在报表外,但更容易出状况的,是报表外的两个环节,所以解决报表的性能之道,功夫大都在报表外
润乾正是把这两个环节都解决好了,再加上本身报表内的性能也很好,所以整体性能才会高出同类产品很多
性能不出问题,业务才稳定,维护成本才低,用的才踏实放心
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

