


统计单词的出现率
在一篇正规的英文文档中,单词都会以空格、逗号、句号或回车分隔,“-”符号表示连接回车符前后的字符为一个单词。
现有一篇符合上述特征的文档MobyDick.txt,请找出其中一共出现过多少个不同的单词,以及每个单词的次数,并找出出现频率最高的单词。
读取文档内容,将文档内容拆成单词序列。统计每个单词出现的次数,出现次数最多的即为出现频率最高的单词。
A |
|
1 |
MobyDick.txt |
2 |
=file(A1).read() |
3 |
=A2.words() |
4 |
=A3.groups(~:Word;count(~):Count) |
5 |
=A4.len() |
6 |
=A4.maxp(Count) |
https://try.esproc.com/splx?3p4
A2用f.read()读出文本文件中的字符串。SPL中可以用s.words()将字符串按单词拆开,如A3中结果如下:
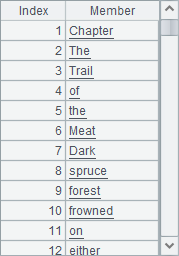
A4将单词序列按照不同的单词分组,并计算每个单词出现的次数,结果如下:
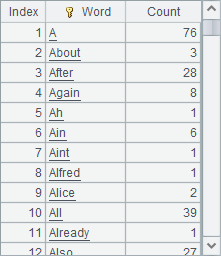
SPL中用groups能很方便地做分组统计计算,结果按分组值升序排序。这里大小写不同认为是不同的单词,如果不考虑大小写不同的情况,可以将A4中代码修改为=A3.groups(lower(~):Word;count(~):Count),即将单词全转为小写再统计。
A5用len就能获取共有多少个不同的单词:

A6用maxp就可找到哪个单词出现的频率最高,以及它的使用次数:
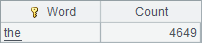
熟练之后,可以用一句代码找到出现频率最高的单词及其出现次数:=file("MobyDick.txt").read().words().groups(~:Word;count(~):Count).maxp(Count)。
如果需要统计的文档数据量比较大,或者计算机的内存比较小,无法把所有数据同时读出做统计,此时可以使用游标,将数据逐步取出,并将统计结果合并计算,如:
A |
|
1 |
MobyDick.txt |
2 |
=file(A1).cursor@i() |
3 |
=A2.(~.words()).conj() |
4 |
=A3.groups(~:Word;count(~):Count).maxp(Count) |
https://try.esproc.com/splx?3xh
A2用文件生成游标,逐步读取数据,添加@i选项,将结果返回为每行文字构成的序列。
A3将游标中每一行文字拆分为单词,并用conj将单词逐个返回。A4对游标直接用groups对游标中返回的单词做统计,并从中取出出现频率最高的单词的数据:
上面的代码同样也可以直接写为一句代码:=file("MobyDick.txt").cursor@i().(~.words()).conj().groups(~:Word;count(~):Count).maxp(Count)。


MobyDick.txt
英文版