


数据分析编程从 SQL 到 SPL:访问时长
简化后的账户表 user、访问表 view 的部分数据如下:
user:
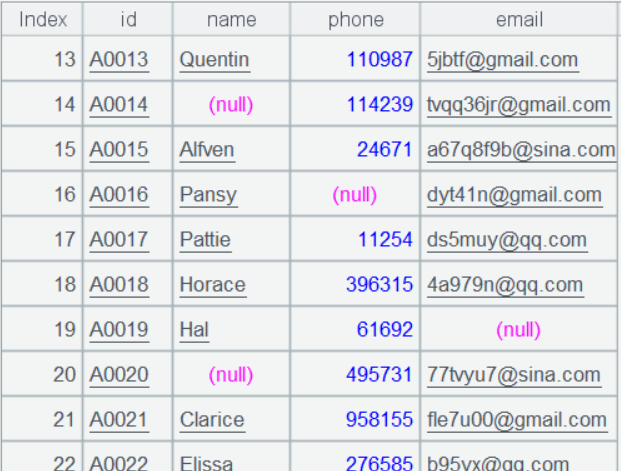
view:
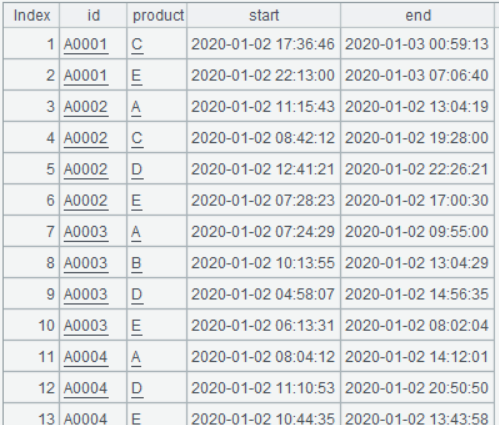
1、统计每个账号访问各个产品的分钟数
按账户 id、产品分组汇总出分钟数,结果列为:账户 id、产品、分钟数,期望把结果转置成:账户 id、产品 A 分钟数、产品 B 分钟数、产品 C 分钟数……。
SQL:
select id,
sum(if(product='A',timestampdiff(minute,start,end),0)) A,
sum(if(product='B',timestampdiff(minute,start,end),0)) B,
sum(if(product='C',timestampdiff(minute,start,end),0)) C,
sum(if(product='D',timestampdiff(minute,start,end),0)) D,
sum(if(product='E',timestampdiff(minute,start,end),0)) E
from view
group by id;
SQL 要针对各个产品独自定义汇总,有 5 个产品,汇总表达式要写 5 遍。
ORACLE 提供了转置函数:
select *
from (
select
id, product,
(extract(day from (end - start)) * 24 * 60 +
extract (hour from (end - start)) * 60 +
extract (minute from (end - start))) AS minute
from view
)
pivot (
sum(minute)
for product IN ('A', 'B', 'C', 'D', 'E')
)
ORACLE 没有 timestampdiff 函数,算两个日期的间隔时间比较麻烦;
有了 pivot 函数也不是很简单,列名不能缺省;即便只是简单选几个相关字段,也必须用一个子查询;pivot 子语中未出现的字段,自动成为分组字段,这规则比较隐晦,用起来死板。
SPL 转置写起来更简单,支持缺省列名:
A |
|
1 |
=file("view.txt").import@t() |
2 |
=A1.groups(id,product;sum(interval@s(start,end))/60.0:time) |
3 |
=A2.pivot(id;product,time) |
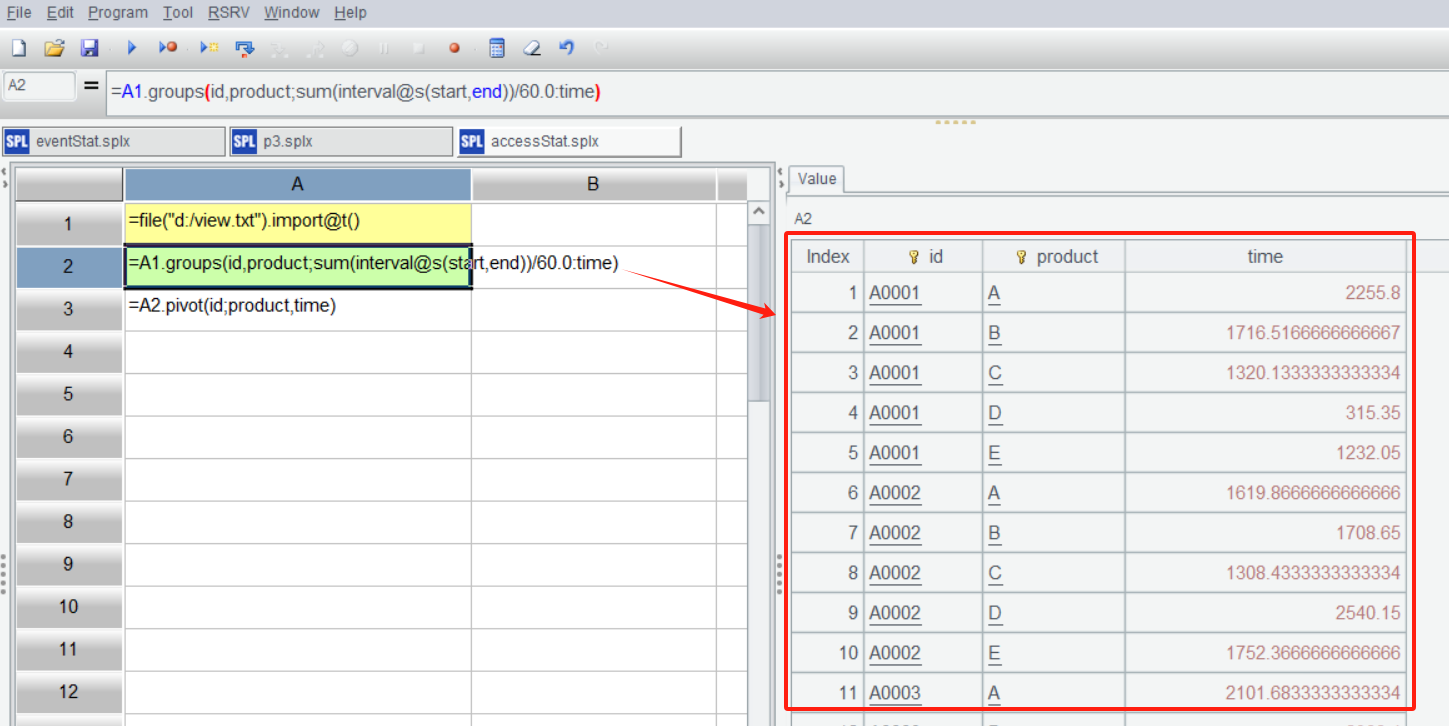
SPL IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果,点击 A2,看到汇总出了每个账户各个产品的分钟数:
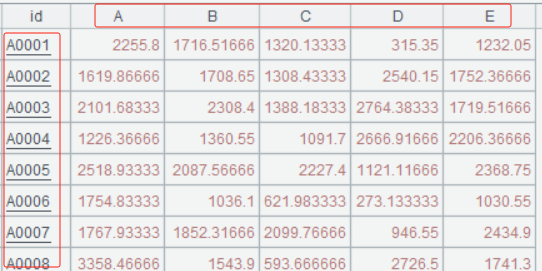
A3 针对 A2 做转置,按账户分组,把每个产品值转置成列名,列值即为各产品的分钟数:
2、统计各天访问产品 A、B 的分钟数
一次访问可能跨越多个日期,要先拆分成单日内的访问记录,再按日期,产品汇总分钟数,最后做一下转置,就得到了产品 A、产品 B 各日期的分钟数。
先看 SQL:
with recursive days(day) as(
select min(date(start)) from view
union all
select day+interval 1 day from days
where day<(select max(date(end)) from view)
),
t as (
select d.day, v.product,
greatest(v.start, d.day) start,
least(v.end, d.day+interval 1 day) end
from days d join view v
on (v.start>=d.day and v.start<d.day+interval 1 day)
or (v.end>d.day and v.end<=d.day+interval 1 day)
)
select day,
sum(if(product='A',timestampdiff(minute,start,end),0)) A,
sum(if(product='B',timestampdiff(minute,start,end),0)) B
from t
where product='A' or product='B'
group by day;
SQL 没有直接的函数生成日期序列,要用递归子查询生成;不能直观地将每个访问记录按天拆分,要用 view 表和日期序列关联;这两步理解起来比较困难。最后仍然要枚举分组值、重复定义汇总计算获得期望结果。
SPL 集合有序,针对每行计算时能按位置跨行引用数据,容易按照自然思维拆分出单日访问记录,并转置出期望的结果格式:
A |
|
1 |
=file("view.txt").import@t().select(product=="A" || product=="B") |
2 |
=A1.news(periods(start,end).to(2,);product,if(#==1,start,~[-1]):start, ~:end) |
3 |
=A2.groups(date(start):day,product;sum(interval@s(start,end))/60.0:time) |
4 |
=A3.pivot(day;product,time) |
A2 的 news 函数中针对每条访问记录计算,periods 函数返回此次访问的日期序列(含起止时间点),例如 start 为 2020-01-02 22:41:49,end 为 2020-01-04 09:32:22 时,periods(start,end) 结果为:
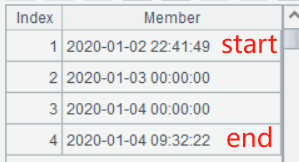
这四个时间点组成的三个时间段各自都在一天内。
用 to(2,) 选出每个时间段的结尾时间点,基于这些时间点再生成一天内的访问记录。
news 分号后的参数定义新访问记录,其中 #表示当前序号(第几个时间点),~ 表示当前时间点,~[-1] 表示上一个时间点。A2 最终拆分出所有单日内的访问记录(看到红框中跨日的访问记录被拆分了):
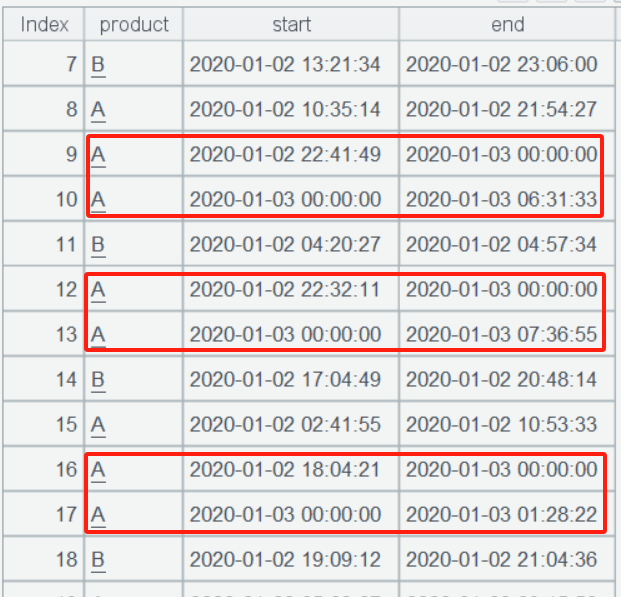
A3 按日期、产品分组汇总分钟数,最后 A4 把产品列转置即可。
3、 统一相同(phone 或 email 相同)用户的 id
phone 或 email 相同的账户,被认定为同一个自然人,现在要把同一自然人的 id 统一为首次注册 id(最小的 id)。
统一 id 前,先产生新列 orid_id,把原始 id 备份一下。
循环每个注册用户,与它后面的做对比,遇到相同 phone 或 email,把 id 统一成较小 id:
原 A0001 对比后面账户,与 A0005 和 A0007 是同一自然人,统一成 A0001;
原 A0002 对比后面账户,与 A0003 是同一自然人,统一成 A0002;
原 A0003(现 A0002) 对比后面账户,与 A0004 是同一自然人,统一成 A0002;
原 A0004(现 A0002) 对比后面账户,与 A0005(现 A0001) 是同一自然人,统一成 A0001;
原 A0006 对比后面账户,与 A0008 是同一自然人,统一成 A0006;
原 A0008(现 A0006) 对比后面账户,与 A0009 是同一自然人,统一成 A0006;
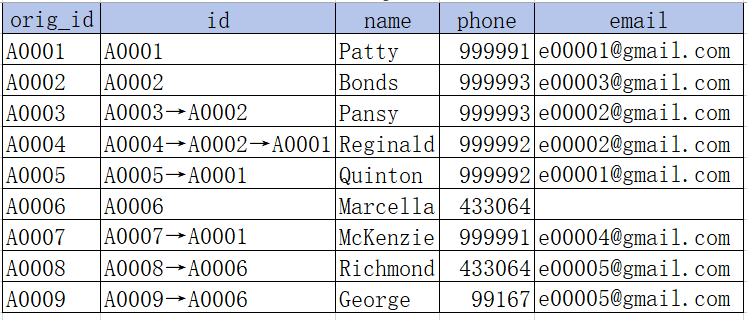
循环处理一遍后,有一些间接关联账户 (如 A0006 和 A0009) 已经统一,但也有一些间接关联账户还没处理完(如原 A0002 和 A0003 还未和 A0001 统一),所以这样循环处理操作需要重复多遍,直到找不到相同用户为止,循环第二遍时,原 A0003 统一成 A0001:
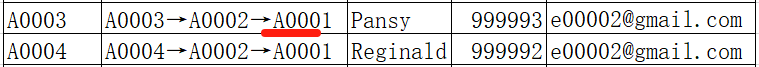
继续循环第三遍时,原 A0002 统一成 A0001:
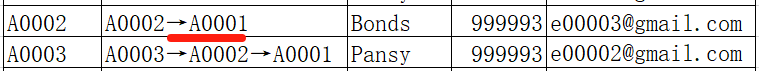
继续循环第四遍时,一个相同用户都未找到,完成统一任务。
这种依赖集合成员次序,需要按位置获取成员,还要暴力循环的需求用 SQL 不能直接实现,迂回替代方案又很难想出,就不尝试编写了。
SPL 的集合有序,能按位置获取 (多个) 成员,容易按照上面的处理思路编写出暴力循环代码:
A |
|
1 |
=file("user.txt").import@t() |
2 |
=T=A1.derive(id:orig_id) |
3 |
for T.count( |
A2 添加新列 orid_id 备份 id,然后把整个序表赋值给 T 变量。
A3 外层的 count 函数,记录某次循环,有多少个账户发生过统一处理,只要大于 0(发生过处理),就会持续做循环处理。
内层操作对象 T[1:] 是当前账户之后的所有账户集合,针对它的 count 操作,记录后面有多少账户和它做过统一。
if 函数里比对当前账户 (T) 和后续账户 (~,~ 可以省略,比如 phone 就是 ~.phone),是同一用户时,就把两个账户的 id(T.id 和 ~.id) 都设置成较小 id。
A3 里出现了三个嵌套循环,最外层的 for 为无限循环,通过循环结果判断是否要中断循环;
T.count 循环所有账户,逐个处理每个账户;
T[1:].count 循环当前账户后面的所有账户,用它们和当前账户做比对。做计算时,各层数据都可以引用。
4、 统一 id 后统计每个自然人用户访问各个产品的分钟数
对账户表统一 id 后,与访问表按照原始账户 id 关联起来,就能按照自然人统计各个产品的分钟数了。
两个计算步骤清晰明确,把上面题 1 与题 3 的 SPL 代码组合起来,中间加一个关联操作即可:
A |
|
1 |
=file("user.txt").import@t() |
2 |
=T=A1.derive(id:orig_id) |
3 |
for T.count( |
4 |
=file("view.txt").import@t() |
5 |
=A4.switch(id,A2:orig_id) |
6 |
=A5.groups(id.id,product;sum(interval@s(start,end))/60.0:time) |
7 |
=A6.pivot(id;product,time) |
A5 用 switch 函数关联两表,把访问表的 id 替换为账户表记录,组成一个二层序表。
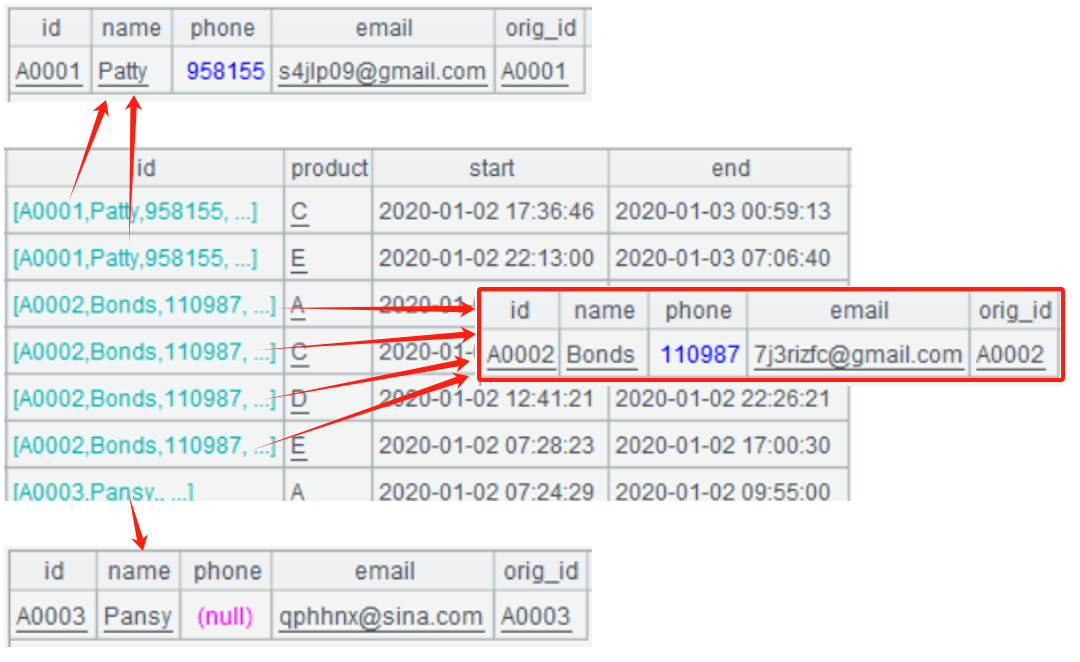
A6 针对 A5 的二层序表做汇总,id.id 就是统一后的 id(同理 id.name 是账户名、id.orig_id 是原始账户 id)。
5、去除上题汇总结果中的重叠时间
每组访问记录按起始时间排序后,要判断某次访问记录是否有重叠,先算出它之前最晚的结束时间 x,如果本次起始时间迟于 x,那就没有重叠;如果 x 在本次访问起止时间之间,那 x 到本次结束的时间不重叠;如果 x 迟于本次结束时间,那本次访问时间全部重叠。做汇总时,循环判断每条访问记录,只累加不重叠部分即可。
SPL 可以做单纯的分组操作获得分组子集,在分组子集上再定义更复杂的运算,SPL 的集合是有序的,能按照位置获取数据,容易按照上述自然思路去掉重叠时间,修改上题中的 A6 格就可以了:
A |
|
1 |
=file("user.txt").import@t() |
2 |
=T=A1.derive(id:orig_id) |
3 |
for T.count( |
4 |
=file("view.txt").import@t() |
5 |
=A4.switch(id,A2:orig_id) |
6 |
=A5.group(id.id,product; |
7 |
=A6.pivot(id;product,time) |
A6 中改用独立分组函数 group,得到每个用户每个产品的访问记录子集合 ~,先按起始时间排序,然后用 sum 函数累计不重叠的访问时间。
end[:-1] 是当前访问记录之前所有访问记录的结束时间,用 max() 找到它们中最晚的时间。
计算出 x 后,用 if() 函数判断三种不同的重叠情况,并返回不重叠时间。
区别于 SQL 的无序集合,SPL 基于有序集合定义出了很多强大计算能力的函数,容易贴合自然解题思路编写代码,像 SQL 那样要想出迂回烧脑替代方案的麻烦就避免了。


第 3 个问题统一相同的 id 有点不好搞,这样暴力循环要循环 9 万多次 (在最里层的 count 里 i+=1, 不知道这样计数对不对)
有没有循环次数少一点的写法?
外面大循环次数,应该也不太多,主要看 A 改 B,B 为 C、C 改 D…. 最大的层数,每次大循环消除一层。
这题蒋总提过用改用图的方式,可能计算量小点,但代码要复杂很多。
你有兴趣的话,继续研究研究。
谢谢大佬回复🙏 用 "图的方式",我就不会了,知识盲区😄
之前碰到过类似的计算,如下所示,但帖子中的题更综合,除了统一用户 ID,还有第 5 部分重叠区间的计算也有遍历次数少的写法。
我的做法是新开了一个空间,当成统一 ID 后的最终结果,然后遍历源数据,在这个结果集中找,好像能少一些遍历次数。
但这样满世界找,总感觉一般。
英文版