


用 SQL 做数据分析貌似是个伪命题
SQL 用于数据分析其实会很浅
SQL 被广泛用于数据分析,经常会被当成数据分析师的默认技能。的确,数据库环境下会写 SQL 是很方便,想查什么写句 SQL 似乎就能搞定。比如,查个用户分组销售额,SQL 写出来就像英语一样简单:
SELECT area, SUM(amount)
FROM sales
WHERE amount > 1000
GROUP BY area
但数据分析业务并非总是这么简单,比如,统计新用户第二天的留存率,写出 SQL 大概是这样:
with t1 as (
select userid, date(etime) edate from actions group by userid,date(etime)),
t2 as (
select userid, edate, row_number() over(partition by userid order by edate) rn
from t1
),
firstday as (
select userid, min(edate) frst from t2 group by userid),
retention as (
select fd.userid, frst, t.edate nxt
from firstday fd left join t2 t
on fd.userid=t.userid and date_add(fd.frst, interval 1 day)=t.edate
group by fd.userid, frst, nxt
)
select frst edate, count(nxt)/count(frst) rate
from retention
group by edate
order by edate;
SQL 集合无序,必须通过硬造序号的方式来标记有序事件以获取新用户,同时 SQL 无法保留分组后的成员集合,也要通过嵌套的子查询和反复关联才能计算用户是否留存,这会增大理解和编写的困难。这样的 SQL 连专业 DBA 都头疼,可能没有几个数据分析师能写出来,不少数据分析师们恐怕只能“望需兴叹”了。
如果这个任务还能咬咬牙完成,还有更难搞的:每天统计最近 7 天中连续活跃 3 天及以上的人数。
这个实际需求已经难到用 SQL 几乎写不出来了,说“几乎”是因为对于绝顶 SQL 高手爆肝两天还是有可能的,这里给出写法来感受复杂度。
with recursive edates as (
select min(date(etime)) edate from actions
union all
select date_add(edate, interval 1 day) from edates
where edate<(select max(date(etime)) from actions)
),
users as (
select distinct userid from actions
),
crox as (
select u.userid, d.edate, t.edate rdate
from edates d cross join users u
left join (select distinct userid, date(etime) edate from actions) t
on d.edate=t.edate and u.userid=t.userid
),
crox1 as (
select userid,edate, rdate, row_number() over(partition by userid order by edate) rn,
case when rdate is null or
(lag(rdate) over(partition by userid order by edate) is null and rdate is not null)
then 1 else 0 end f
from crox
),
crox2 as (
select userid, edate, rdate,
cast(rn as decimal) rn, sum(f) over(partition by userid order by edate) g
from crox1
),
crox3 as (
select t1.userid, t1.edate, t2.g, case when count(*)>=3 then 1 else 0 end active3
from crox2 t1 join crox2 t2
on t1.userid=t2.userid and t2.rn between t1.rn-6 and t1.rn
group by t1.userid,t1.edate,t2.g
),
crox4 as (
select userid, edate, max(active3) active3
from crox3
group by userid,edate
)
select edate, sum(active3) active3
from crox4
group by edate;
看完想哭的感觉有没有?!用 SQL 做数据分析真的合适吗?它到底能做些什么?
SQL 作为一种结构化查询语言,确实在很多场景下被广泛应用。对于简单的分析需求,SQL 也很简单,这当然没问题,但面对上面这种较复杂需求时,对很多数据分析师来讲,SQL 就会变得太难甚至写不出来了。也就是说,大多数人使用 SQL 做数据分析时,只能做很浅的任务,而这种任务其实常常可以被 BI 搞定,也不需要写 SQL 了。所以我们说,用 SQL 做数据分析貌似是个伪命题。
要实施更深层次的数据分析,我们需要转向更有过程性和灵活性的编程语言,从而能够处理复杂的数据计算和深度分析。
Python 也不给力
Python 是一个看起来不错的选择,也很流行。考察一下,像上面新用户第二天的留存率的计算,用 Python 来写:
df = pd.DataFrame(data)
df['etime'] = pd.to_datetime(df['etime'])
df['edate'] = df['etime'].dt.date
t1 = df.groupby(['userid', 'edate']).size().reset_index(name='count')
t1['rn'] = t1.groupby('userid')['edate'].rank(method='first', ascending=True)
firstday = t1.groupby('userid')['edate'].min().reset_index(name='frst')
retention = pd.merge(firstday, t1, on='userid', how='left')
retention['nxt'] = retention['frst'] + pd.Timedelta(days=1)
retention = retention[retention['edate'] == retention['nxt']]
retention_rate = retention.groupby('frst').apply(
lambda x: len(x) / len(t1[t1['edate'] == x['frst'].iloc[0]]))
这个代码仍然不太简单,因为 Python 也没有分组子集,也需要变通思路,只是支持分步过程后会方便一些,比 SQL 容易理解了。
还能更简单吗?
SPL 才是能做深入数据分析的程序语言
esProc SPL 是更好的选择,写得简单,交互性也强。
写得简单
直接看 SPL 实现代码。
统计新用户第二天的留存率
A |
|
1 |
=file("actions.txt").import@t() |
2 |
=A1.groups(userid,date(etime):edate) |
3 |
=A2.group(userid) |
4 |
=A3.new(userid, edate:frst, ~.select@1(edate==frst+1).edate:nxt) |
5 |
=A4.groups(frst ; count(nxt)/count(frst):rate) |
不同于 SQL 分组后要聚合,SPL 的分组可以保留分组子集,以便后续针对分组成员进行计算。像 A3 分组后的结果是这样,分组结果是集合的集合,即每个分组的成员: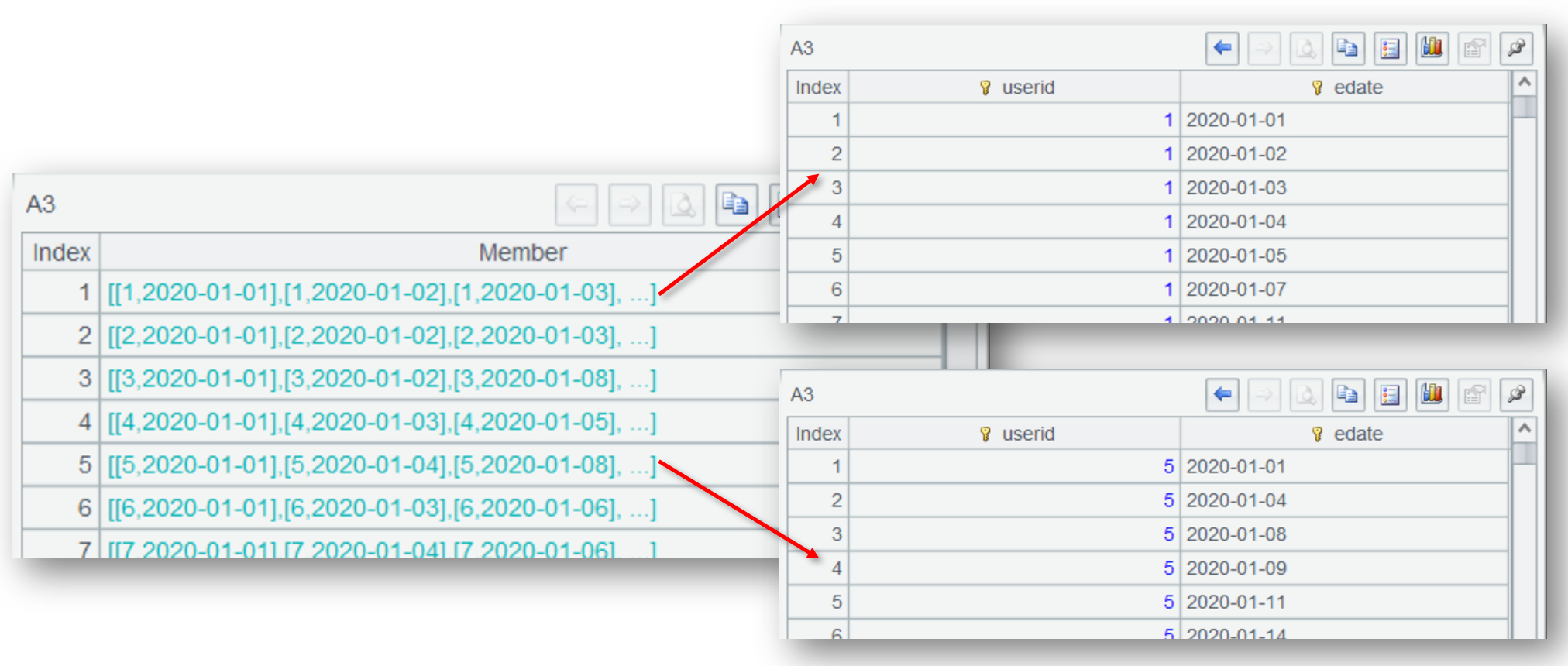
这种每步(格)实时可见的结果很方便查看,具备很强的交互性。
SPL 还支持有序计算,可以很方便完成次序相关的计算,比如 A4 中的 select@1 用来取第一条记录。下面还有对有序运算更深入的使用。
前面用 SQL 几乎写不出来的例子,每天统计最近 7 天 (含当天) 中连续活跃 3 天及以上人数,用 SPL 仍然可以比较轻松地写出来:
A |
|
1 |
=file("actions.txt").import@t() |
2 |
=periods(date(A1.min(etime)), date(A1.max(etime))) |
3 |
=A1.group(userid).(~.align(A2,date(etime))) |
4 |
=A3.(~.(~[-6:0].pselect(~&&~[-1]&&~[-2]))) |
5 |
=A2.new(~:date, A4.count(~(A2.#)):count) |
这里更深入地使用了有序计算的能力,比如 A4 中使用 [] 引用相邻位置的成员,使用 pselect 获取成员位置等。整体可以尝试读一下,就更能理解 SPL 在处理这类复杂计算时的优势和便利。
交互性也强
SPL 不仅仅写的简单,IDE 由于提供了丰富的调试功能和可视化结果面板,在交互性上也优于 Python,更远胜 SQL,适合需要探索的数据分析业务。
完善的编辑调试功能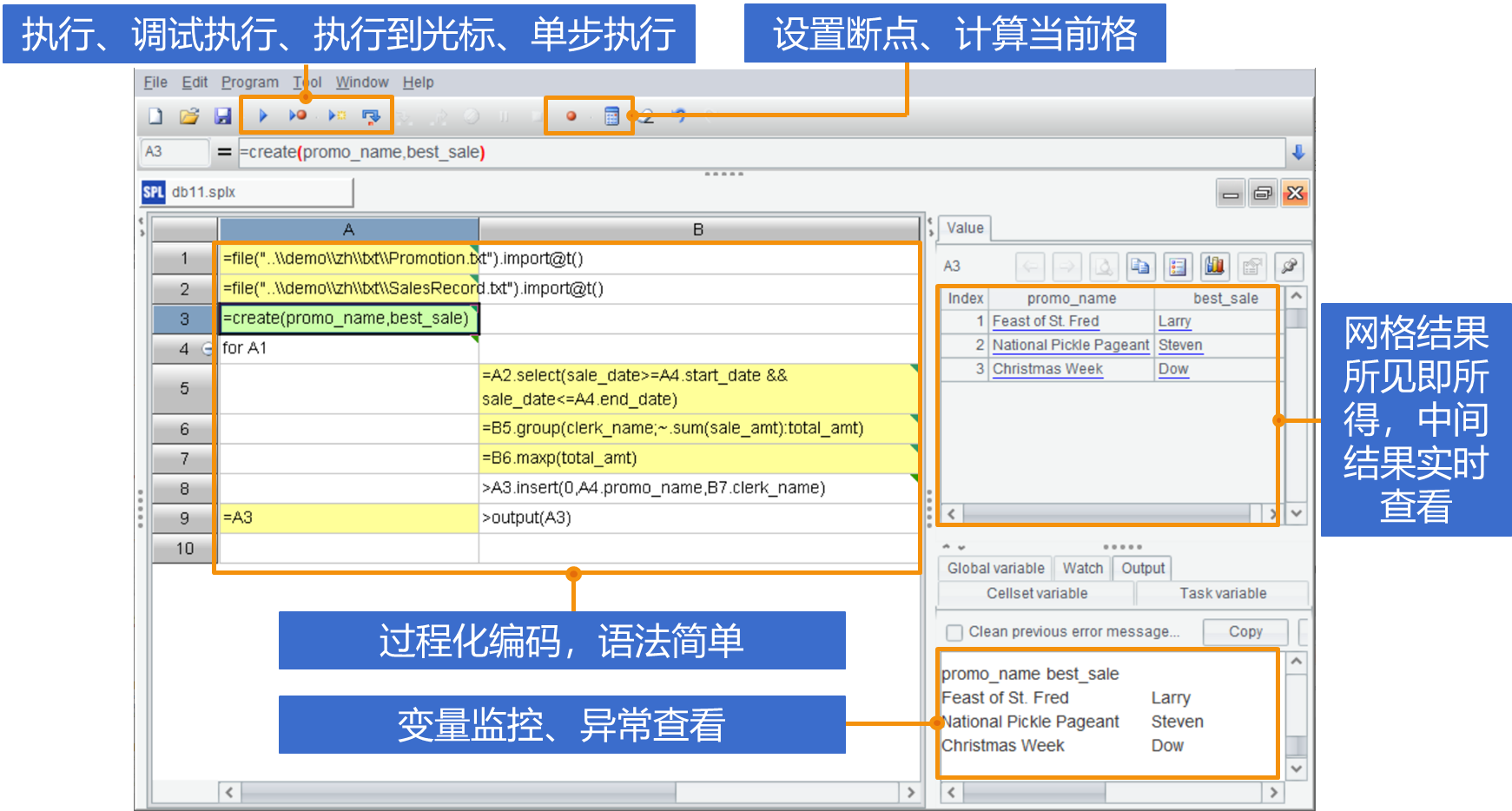
每步实时可见的运行结果,不对可以立刻调整
SQL 在处理简单查询时很方便,但面对复杂分析时局限性就很明显,做起来有点吃力;Python 更灵活,但编码复杂度仍然不低。相比之下,SPL 的语法简单,运算功能强大,而且操作起来更直观,特别适合处理那些复杂的数据分析任务,尤其是在需要频繁调整和探索分析的场景下。相比 SQL 和 Python,SPL 是一个更适合的选择。


英文版