


这可能是最轻量级的列存技术了
列式存储是提高数据分析计算性能的重要手段。如果数据表的总列数很多而计算涉及的列很少,采用列存就只读取需要的列即可,能够减少硬盘访问量,提高性能。而且,同一列数据往往是同一类型的,甚至有些情况取值都很接近,这样的一批数据连续存储,通常可以实施更高效的数据压缩。
但是,在实际应用中搭建一个列式数据仓库太复杂了。常用的轻量级数据库,比如 Mysql 都不支持列存。列式存储大都存在于大型 MPP 数据库中。Hadoop 也提供了列存文件格式,比如 parquet、orc 等,但仍要借助复杂的环境(Hadoop 或 spark)才能工作,架构过于沉重,虽然软件本身是开源免费的,但整体应用成本还是很高。
那么,有没有不需要繁复架构的轻量级列存技术?
开源计算引擎 esProc 的 ctx 文件就是一种很轻的列存技术。esProc 提供了简捷的编程语言 SPL 用于操作 ctx 文件。
用 SPL 可以把来自各种数据源的数据转成 ctx 实现列存,也可以把 ctx 转成其他数据源。以常见的 csv 和数据库为例:
A |
B |
|
1 |
/csv to ctx |
|
2 |
=T@c("orders.csv").sortx(O_ORDERKEY) |
|
3 |
=file("orders.ctx").create@y(#O_ORDERKEY,O_CUSTKEY,O_ORDERSTATUS,O_TOTALPRICE,O_ORDERDATE,O_ORDERPRIORITY,O_CLERK,O_SHIPPRIORITY,O_COMMENT) |
|
4 |
=A3.append(A2) |
=A3.close() |
5 |
/ctx to csv |
|
6 |
=file("orders_new.csv").export@tc(T@c("orders.ctx")) |
|
7 |
/DB to ctx |
|
8 |
=connect("demo") |
|
9 |
=A8.cursor("select ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE from sales order by ORDERID") |
|
10 |
=file("sales.ctx").create@y(#ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE) |
|
11 |
=A10.append(A9) |
=A10.close() |
12 |
/ctx to DB |
|
13 |
=A8.execute(T@c("sales.ctx"),"insert into sales (ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE) values(?,?,?,?,?)",#1,#2,#3,#4,#5) |
|
14 |
>A8.close() |
|
列存文件的使用相对行存文件要稍复杂些,需要事先确定数据结构并创建相应的索引区才能写入数据,但在 SPL 支持下,这些代码仍然非常简单。
列存通常用于存储较大数据量,所以这些示例代码都使用了游标,ctx 也可以很好地支持以游标方式流式读写数据。
SPL 还为 ctx 提供了强大的计算能力,支持分段并行:
A |
B |
|
1 |
=file("orders.ctx").open().cursor@m(O_ORDERKEY,O_CUSTKEY;between(O_ORDERDATE,date(1996,1,1):date(1996,1,31))) |
/过滤 |
2 |
=file("orders.ctx").open().cursor@m(O_ORDERDATE,O_TOTALPRICE).groups(O_ORDERDATE;sum(O_TOTALPRICE):all,max(sum(O_TOTALPRICE)):max) |
/分组汇总 |
3 |
=file("orders.ctx").open().cursor@m(O_CUSTKEY;[2,3,5,8].contain(O_CUSTKEY)).total(icount(O_CUSTKEY)) |
/去重计数 |
4 |
=file("orders.ctx").open().cursor@m(O_ORDERKEY,O_TOTALPRICE;![20,31,55,86].contain(O_CUSTKEY)).total(top(-10;O_TOTALPRICE)) |
/TOP N |
5 |
= T("customer.btx").keys(C_CUSTKEY) |
/外键关联 |
6 |
=file("orders.ctx").open().cursor@m(O_ORDERKEY,O_CUSTKEY,O_TOTALPRICE).switch(O_CUSTKEY,A5) |
|
7 |
=file("customer.ctx").open().cursor@m(C_CUSTKEY,C_ACCTBAL) |
/主键关联 |
8 |
=file("customer_info.ctx").open().cursor(CI_CUSTKEY,FUND;;A7) |
|
9 |
=joinx(A7:c, C_CUSTKEY;A8:ci,CI_CUSTKEY) |
|
10 |
=A9.new(c.C_ACCTBAL+ci.FUND:newValue) |
cursor 函数加上 @m 选项,就表示对 ctx 分段进行多线程并行计算,非常简单易用。
代码中文件对象 file("orders.ctx") 可以定义一次反复使用。不过游标只能计算一次,每次计算都要定义新的游标。
分段是并行计算的前提。业界普遍采用的分块列存方案,只有在总数据量很大时才有性能上的意义,一般要达到单表十亿记录、空间约在百 G 左右。规模较小的数据量就不容易获得并行计算的性能提升。ctx 采用了自创的倍增分段方案,很小的数据量且在不断追加的过程中,都可以获得良好的分段效果,保证并行计算的性能提升。
除了倍增分段,ctx 还内置了很多高性能存储方案。比如列存很难实现索引,而 ctx 使用独有的序号机制克服了这个困难。再如 ctx 利用有序存储机制,让同一列的相同值连续存放,进一步提高了列存压缩效率。
经过对比测试,ctx 读取性能几乎比 ORC 快了一倍,更是远远超过了 Parquet:
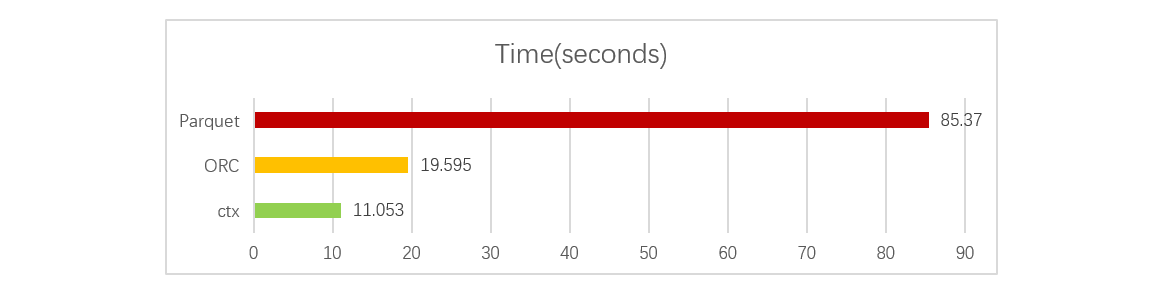
详细的测试过程和结论参见乾学院:esProc 组表,ORC,Parquet 的对比。
esProc SPL 非常轻,集成开发环境 IDE 即装即用,无需像 Hadoop 那样配置各种环境,更不需要集群:
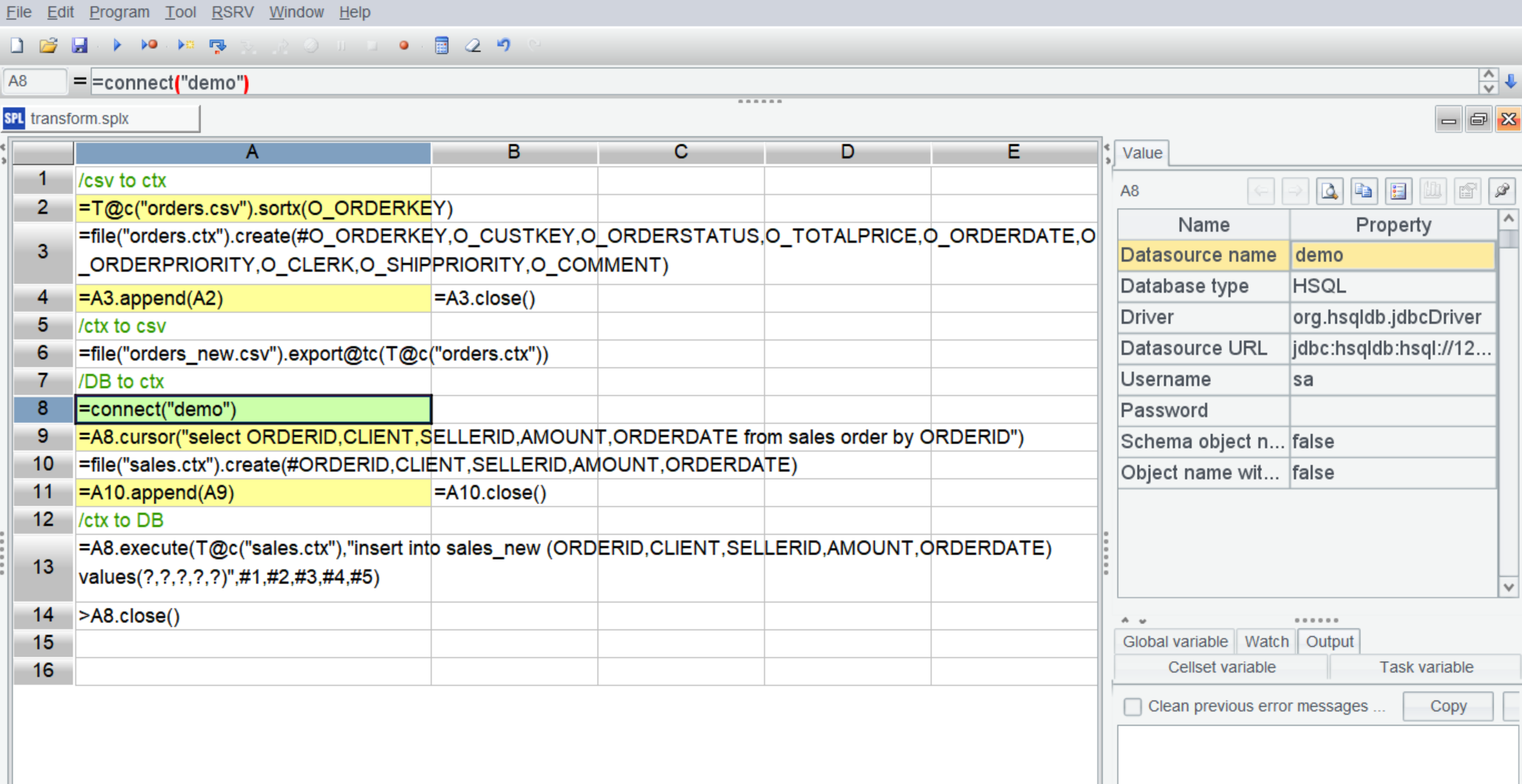
esProc 提供了标准 JDBC 驱动,使得 ctx 很容易嵌入应用,只要将 esProc 核心 jar 包和配置文件放到 Java 应用的类路径中,ctx 文件和编写好的 SPL 脚本(比如 compute.splx)放到配置好的目录就可以调用了:
…
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call computeCtx()");
st.execute();
ResultSet set = st.getResultSet();
…
对于相同的计算逻辑,SPL 代码量会比 Java 少很多。可以用 SPL 脚本实现 ctx 相关的各种复杂计算,前端应用只要接收计算结果然后展现出来就可以了。
esProc 核心 jar 包非常小,只有不到 100MB。
在报表类应用中,非常适合用 ctx 来缓存报表数据,能够获得专业列存数仓的计算性能,也不必安装配置 MPP 或 Hadoop/spark 这种重量级的产品。


英文版