


SPL 报表开发:轻量级低成本实时热数据报表方案
实时热数据报表,是指能够实时查询全量冷热数据的报表。早期业务只基于单个 TP 数据库时,这种报表并不是什么问题。但数据量大了,要拆分到专门的 AP 数据库后,就不一样了。因为冷热数据分离后,再做全量数据的实时报表,就会涉及多数据库的混合计算,而且 AP 库和 TP 库常常还是不同类型的,就更增加麻烦。
采用 HTAP 数据库融合 TP 与 AP 后,可以实现成早期单一数据库的架构,避免跨库混合运算。然而,迁移到新的 HTAP 数据库风险高、成本大,还不一定能复制原有 TP 和 AP 库的各种能力。
采用 Trino 等逻辑数仓引擎或者 Flink 等流处理引擎,再配合 kafka 传输数据,可以实现一定程度的实时同步以及多数据源混合计算。但是架构非常复杂沉重,会涉及元数据管理等诸多繁琐任务,涉及流计算的代码也不够简洁,同步实时程度较高时消耗的资源也较高,这会导致建设和应用成本都很高。
SPL 方案
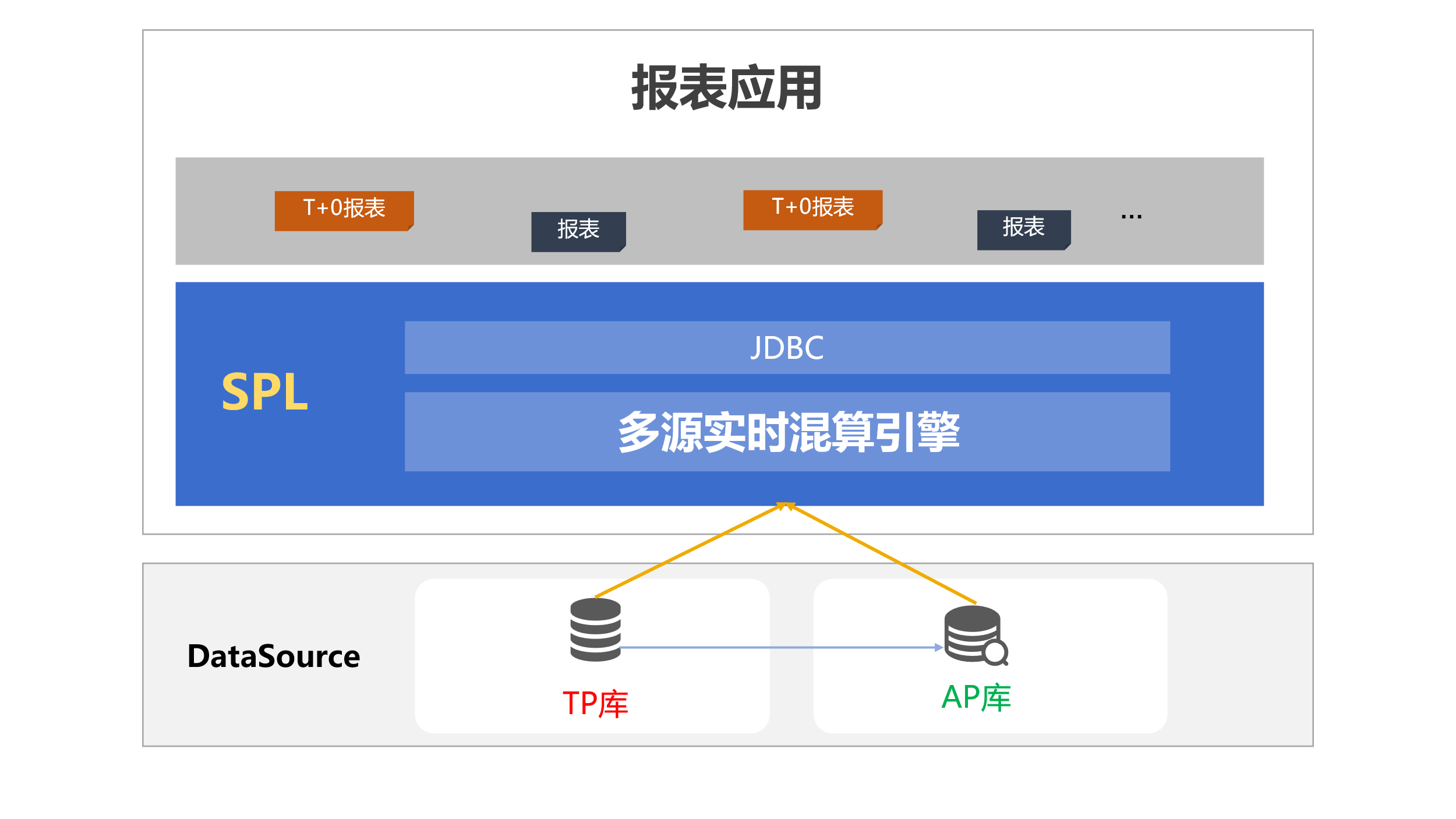
SPL 通过原生数据源接口与 TP、AP 源连接,两边的数据分别各自处理后传输给 SPL 混合再计算,为报表提供实时计算结果。
SPL 有天然的多源混算能力,无论是 AP 库还是 Kafka 等流机制,无论是何种形式的数据仓库还是大数据平台,亦或者文件或云上对象存储,SPL 都可以直接访问读取并混合计算。
更详细地多源计算内容请参考: SPL 报表开发:不依赖逻辑数仓的轻量级多数据源报表
SPL 非常轻量,原来架构几乎不用动,既不涉及数据库迁移,也无需面临复杂的架构改动,只需将 SPL 集成(无缝)到报表应用中即可享受实时查询的便利。
而且,SPL 是临时从 TP 读取热数据再混合计算,这种结构对数据转储进 AP 库的实时性要求并不高,可以从容不迫地将数据做一些整理后再同步进 AP 库,以获得 AP 库更好的计算性能。
话不多说,我们来看一下 SPL 实现 T+0 计算的示例。
举个例
1. 业务场景
某电商平台希望实时监控用户的购买行为,并生成 实时商品销售转化率报表,以辅助营销策略调整。报表需展示以下指标:
每小时内各商品的浏览量、购买量及转化率(购买量 / 浏览量)。
每种商品实时的总销售额。
2. 报表目标
生成一张实时更新的报表,内容示例如下:
商品 ID |
浏览量 |
购买量 |
转化率(%) |
总销售额(元) |
P001 |
500 |
100 |
20 |
15,000 |
P002 |
300 |
50 |
16.67 |
7,500 |
浏览量 和 购买量:通过整合 实时用户点击流数据 和 实时订单数据获取。
总销售额:从 实时订单数据 和 历史订单数据 计算。
转化率:通过实时计算购买量与浏览量的比值获得。
3. 数据来源
TP 数据库(订单数据):存储最新的订单数据,支持事务性操作,实时写入。
Kafka 流数据:记录实时的用户行为数据(如用户浏览商品、加入购物车、完成结算等行为)。Hadoop 存储(历史订单数据):存储历史订单数据,采用 ORC 格式存储
(1)TP 数据库 - orders 表(存储最新的订单数据)
order_id |
user_id |
product_id |
quantity |
total_price |
order_time |
1001 |
2001 |
3001 |
2 |
400.00 |
2024-12-19 10:15:00 |
1002 |
2002 |
3002 |
1 |
150.00 |
2024-12-19 10:20:00 |
1003 |
2001 |
3003 |
3 |
600.00 |
2024-12-19 10:25:00 |
(2)Kafka 流数据 - 用户行为数据(过去一小时)
product_id |
views |
P001 |
500 |
P002 |
300 |
(3)Hadoop 存储 - his_orders 表(历史订单数据)
order_id |
user_id |
product_id |
quantity |
total_price |
order_time |
1001 |
2001 |
3001 |
2 |
400.00 |
2023-12-01 12:10:00 |
1002 |
2002 |
3002 |
1 |
150.00 |
2023-12-01 14:00:00 |
1003 |
2001 |
3003 |
3 |
600.00 |
2023-12-01 16:30:00 |
4. 实现脚本
编写 SPL 脚本 realTimeOrder.splx(历史脚本从 Hive 中读取):
A |
||
1 |
=connect("mysqlDB") |
|
2 |
=A1.query@x("SELECT product_id, SUM(quantity) AS total_sales, SUM(total_price) AS total_revenue FROM orders WHERE order_time > now()-1h GROUP BY product_id") |
/实时订单数据 |
3 |
=kafka_open("/kafka/order.properties", "topic_order") |
|
4 |
=kafka_poll(A3).value |
/实时用户行为数据 |
5 |
=kafka_close(A3) |
|
6 |
=hive_open("hdfs://192.168.0.76:9000", "thrift://192.168.0.76:9083","default","hive") |
/连接 hive |
7 |
=hive_table@o(A6) |
/获取 ORC 表及文件 |
8 |
>hive_close(A6) |
|
9 |
=A7.select(tableName=="his_orders") |
|
10 |
=file(A9.location).hdfs_import@c() |
/历史订单数据 |
11 |
=A10.select(interval(order_time,now())<=730) |
|
12 |
=A11.groups(product_id;SUM(total_price):historical_revenue) |
|
13 |
=join(A2:o,product_id;A4:v,product_id;A12:ho,product_id) |
/关联三部分数据 |
14 |
=A13.new(o.product_id:product_id,v.views:views,o.total_sales/v.views:conversion_rate,o.total_revenue+ho.historical_revenue:total_revenue) |
|
15 |
return A14 |
历史数据可以也可以从 HDFS 中直接读取,脚本如下:
A |
||
1 |
=connect("mysqlDB") |
/TP源 |
2 |
=A1.query@x("SELECT product_id, SUM(quantity) AS total_sales, SUM(total_price) AS total_revenue FROM orders WHERE order_time > now()-1h GROUP BY product_id") |
/实时订单数据 |
3 |
=kafka_open("/kafka/order.properties", "topic_order") |
/Kafka |
4 |
=kafka_poll(A3).value |
/实时用户行为数据 |
5 |
=kafka_close(A3) |
|
6 |
=file("hdfs://localhost:9000/user/86186/orders.orc") |
/直接访问 HDFS |
7 |
=A6.hdfs_import@c() |
/历史订单数据 |
8 |
=A7.select(interval(order_time,now())<=730) |
|
9 |
=A8.groups(product_id;SUM(total_price):historical_revenue) |
|
10 |
=join(A2:o,product_id;A4:v,product_id;A9:ho,product_id) |
/关联三部分数据 |
11 |
=A10.new(o.product_id:product_id,v.views:views,o.total_sales/v.views:conversion_rate,o.total_revenue+ho.historical_revenue:total_revenue) |
|
12 |
return A11 |
整体脚本非常简单清晰。
5. 报表集成
SPL 与报表应用集成非常简单,只要将 SPL 的 esproc-bin-xxxx.jar 和 icu4j-60.3.jar 两个 jar 包引入到应用中(一般在 [安装目录]\esProc\lib 下),然后复制 raqsoftConfig.xml(也在上述路径下)到应用的类路径下即可。
raqsoftConfig.xml 是 SPL 的核心配置文件,名称不可更改。
在 raqsoftConfig.xml 中,需要配置外部库,这里用到的 Kafka:
<importLibs>
<lib>KafkaCli</lib>
</importLibs>
同时 MySQL 数据源也需要配置在这里,在 DB 节点下配置连接信息:
<DB name="mysqlDB">
<property name="url" value="jdbc:mysql://192.168.2.105:3306/raqdb?useCursorFetch=true"/>
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="type" value="10"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
…
</DB>
SPL 封装了标准 JDBC 接口,报表可以通过配置 JDBC 数据源来访问 SPL。 比如,在报表数据源处进行如下配置:
<Context>
<Resource name="jdbc/esproc"
auth="Container"
type="javax.sql.DataSource"
maxTotal="100"
maxIdle="30"
maxWaitMillis="10000"
username=""
password=" "
driverClassName=" com.esproc.jdbc.InternalDriver "
url=" jdbc:esproc:local:// "/>
</Context>
标准 JDBC,与普通数据库无异,这里不赘述。
然后在报表数据集中,使用访问存储过程的方式调用 SPL 脚本即可获得 SPL 的计算结果。调用计算实时订单的脚本 realTimeOrder.splx:
call realTimeOrder()
即可为报表输出计算后结果集。


英文版