


数据分析编程从 SQL 到 SPL:股票上涨分析
数据结构和样例数据:
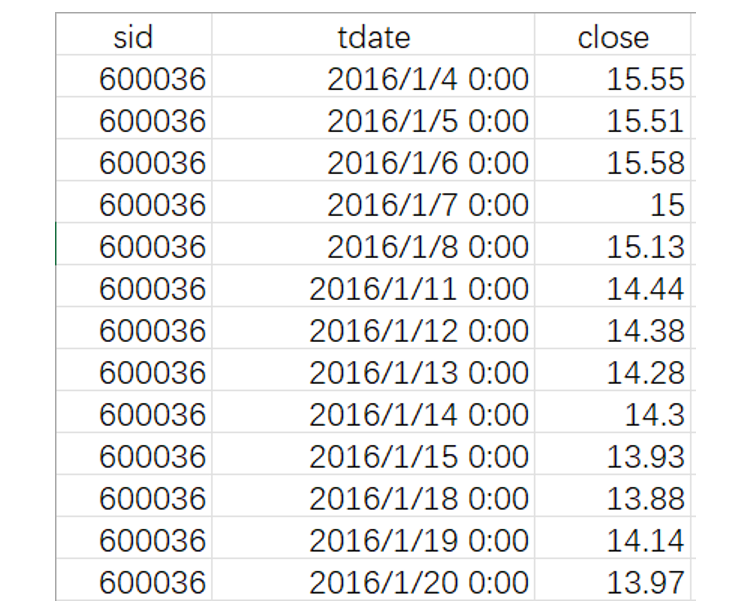
其中 sid 是股票代码,tdate 是交易日期,close 是收盘价。
1. 查找股价上穿中位数
T 日股价中位数是指从上市日收盘价到 T 日收盘价的中位数。
T 日股价上穿中位数是指 T 日收盘价大于 T 日股价中位数,T-1 日收盘价小于 T-1 日股价中位数,或者 T-1 日收盘价等于中位数但 T-2 日收盘价小于中位数,依此类推。
现在要查找 600036 这支股票满足股价上穿中位数的交易日期、收盘价和当日股价中位数。
以 Mysql 数据库为例写出 SQL:
with tbl1 as (
select *
from stock
where sid='600036'
),
tbl2 as (
select t1.*, t2.close pclose,
count(*) over(partition by t1.sid,t1.tdate) cnt,
row_number() over(partition by t1.sid,t1.tdate order by t2.close) r
from tbl1 t1 join tbl1 t2
on t1.sid=t2.sid and t1.tdate>=t2.tdate
),
tbl3 as (
select sid,tdate,max(close) close, avg(pclose) median
from tbl2
where rn=floor((cnt+1)/2) or rn=floor((cnt+2)/2)
group by sid,tdate
),
tbl4 as (
select sid,tdate, close, median,
close>median and
lag(close) over(partition by sid order by tdate)
< lag(median) over(partition by sid order by tdate) flag
from tbl3
where median!=close
)
select tdate, close, median
from tbl4
where flag=1;
Mysql 没有直接提供计算中位数的函数,只能先人为造出序号 r,在外层语句中用 r 作为条件查出中位数相关记录,SQL 非常复杂。
有些数据库(如 Oracle)提供了 median 函数,SQL 会稍简单,但也需要四层子查询配合窗口函数完成计算:
with tbl1 as (
select t1.sid,t1.tdate,t1.close,
(select median(close)
from stock
where t1.sid=sid and t1.tdate>=tdate
) median
from stock t1
where t1.sid=600036
),
tbl2 as (
select sid,tdate, close, median ,
lag(close) over(partition by sid order by tdate) as pclose,
lag(median) over(partition by sid order by tdate) as pmedian
from tbl1
where close!=median
)
select tdate, close, median
from tbl2
where close>median and pclose<pmedian;
要计算 T 日股价中位数,就要找到从上市日到 T 日收盘价的集合。无论是第一个 SQL 采用的连接计算,还是第二个 SQL 采用的子查询,都是比较绕的思路。
更自然的思路是:将这个股票的数据按交易日期排序,从第一条到 T 日(比如 2016 年 1 月 15 日)的 close 值组成的集合,就是 T 日对应的目标集合:
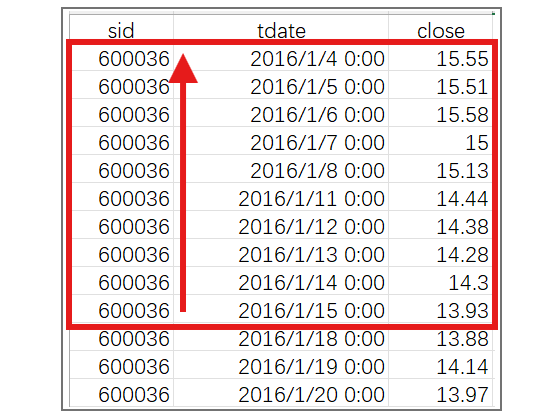
但是,SQL 的集合化不彻底,没有游离记录及其集合的表示方法,不能用原集合的成员构成新集合再进行计算,实现不了这种思路,只能用连接或者子查询来实现。
SPL 集合化更彻底,且支持有序集合,很容易实现这种思路:
A |
|
1 |
=T("stktrade.csv").select(sid==600036).sort(tdate) |
2 |
=A1.derive(close[:0].median():median) |
3 |
=A2.select(close!=median).select(close>median && close[-1]<median[-1]) |
A2:循环函数 derive 支持跨行引用,close[:0] 表示从 A1 第一行到当前行的 close 值构成的集合。这就是思路中的上市日到 T 日的全部收盘价,不需要使用连接或者子查询就可以得到。
而且,SPL 也提供了 median 函数,计算集合 close[:0] 的中位数很方便。
类似地,光标落在 A2 时,可以在右边面板中看到其计算结果:
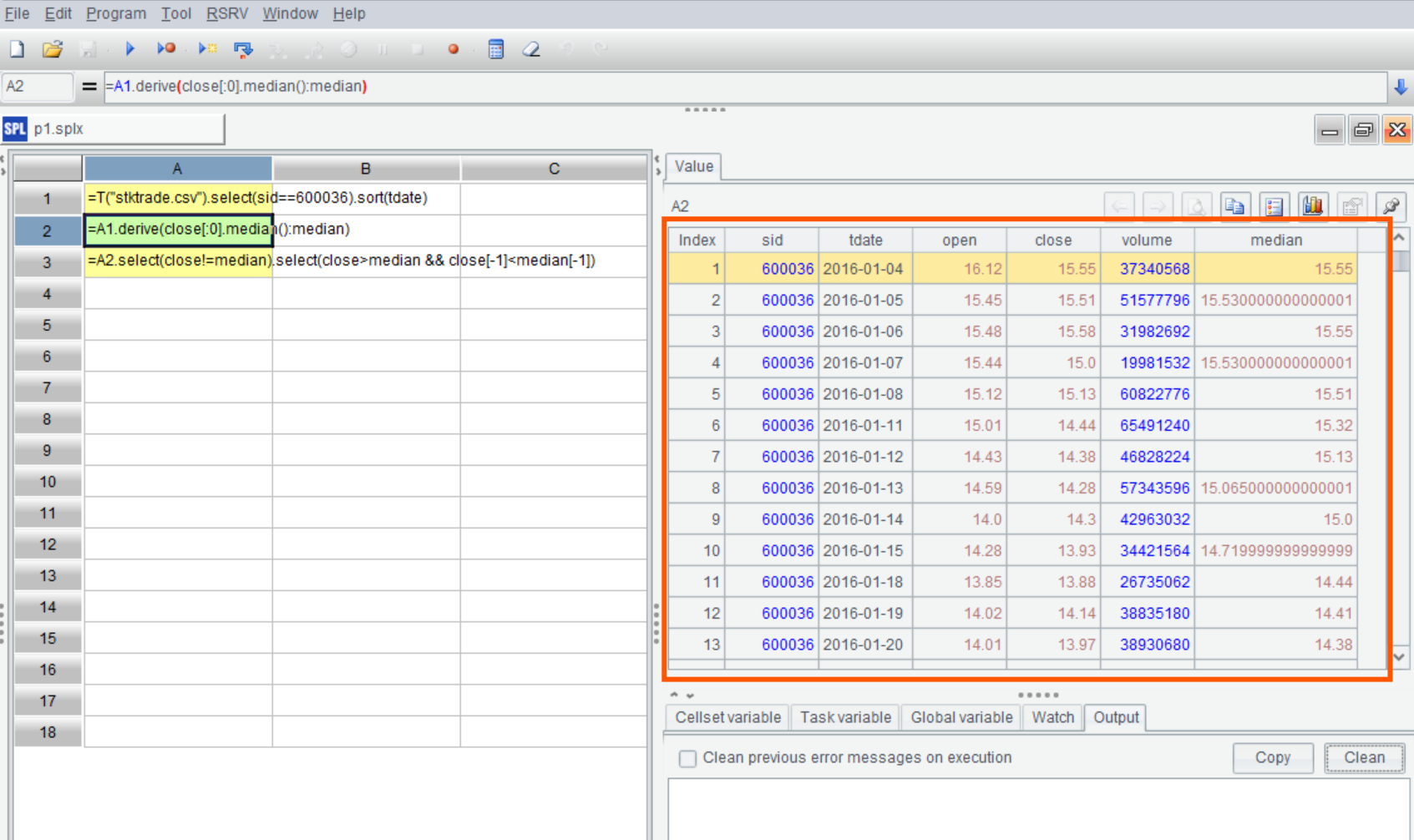
A3 先过滤掉收盘价和中位数相等的记录,然后查找上穿中位数的记录,这里也使用了跨行引用,close[-1]<median[-1] 表示上一行的收盘价小于对应的中位数。
2. 查找指定股票的上升波段
上升波段的计算需求:
输入参数是交易日的个数 W;
一个波段是指连续的多个交易日组成的区间;
某交易日是“W 个交易日新高”,是指这个交易日收盘价比前 W-1 个交易日都高。
某交易日是一个波段中的新低,是这个交易日收盘价比波段内更早日期的收盘价都低。
某交易日在 W 日内必创新高,是指这个交易日后(包括当日)W 日内,会出现至少一个“W 个交易日新高”。
上升波段须满足以下条件:
波段中至少有一个交易日在 W 个交易日内必创新高;
波段的起点价格最低,终点价格最高;
波段最短不低于 W 个交易日。
现在给定 W=5,要找出 300469 这支股票所有上升波段对应的起止日期。
这个计算要找到新高、新低、起点、终点等多个记录位置。如果用 SQL 的话,要反复造出序号再用条件选出,即使能实现,代码也会非常繁琐,这里就不写了。
查找上升波段的思路:将这支股票的数据按照交易日期排序并增加列 high1 和 high2 作为新高和必创新高的标志。第一次循环计算,如果当前交易日收盘价大于前四个交易日,就将 high1 置为 1,否则置为 0。第二次循环计算,如果当前交易日之后的 W-1 个交易日内出现 high1 为 1 的记录,则将 high2 置为 1,否则为 0。计算结果:
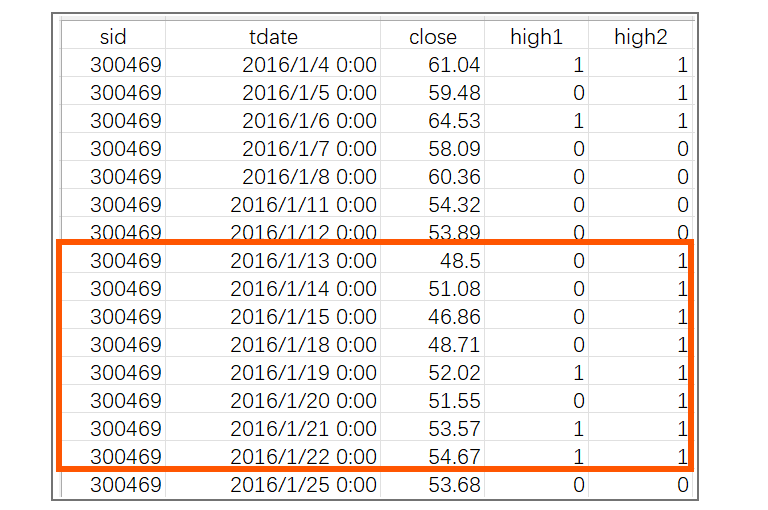
结果中 high2 连续为 1,且长度 >=W 的区间,就是 W 日内必有新高的波段,比如红框的部分。接下来就在这些波段中找目标波段。
如果其中某个波段没有出现新低,就是目标波段了。
如果波段有新低,我们可以在第一个新低之前找第一条 high1 为 1 的记录位置序号 y。如果 y>=W,那么这个波段的前 y 条记录就是目标波段。
然后用第一个新低之后的所有数据组成一个新的波段,再按照同样的方法继续寻找目标波段,以此类推。
很明显,这样的过程需要采用递归函数计算,简单的 SQL 递归语句无法实现,借助存储过程也会非常困难,这里就放弃了。
SPL 有序号定位机制,也支持函数的递归调用,很容易实现这种思路:
A |
B |
C |
|
1 |
=T("stktrade.csv") |
>W=5 |
|
2 |
=A1.select(sid==300469 && tdate>=date(2016,01,04) && tdate<=date(2018,10,18)).sort(tdate) |
||
3 |
=A2.derive(if(close[-W+1:-1].max()<close,1,0):high1).derive(high1[0:W-1].max():high2) |
||
4 |
=A3.group@o(high2).select(high2==1 && ~.len()>=W) |
=create(start,end) |
|
5 |
for A4 |
=stockFunc(A5) |
>B5.run(B4.insert(0,B5.~.tdate,B5.~.m(-1).tdate)) |
6 |
|||
7 |
func stockFunc(stockSet) |
=[] |
|
8 |
=stockSet.pselect(close<close[:-1].min()) |
||
9 |
if B9 |
>if(B9>=W,(x=stockSet.to(B9),y=x.pselect@1(high1==1),if(y>=W,B8|=[stockSet.to(y)]))) |
|
10 |
>if(stockSet.len()-B9+1>=W,B8|=stockFunc(stockSet.to(B9,))) |
||
11 |
else |
>if(stockSet && stockSet.len()>=W,B8|=[stockSet]) |
|
12 |
return B8 |
||
A3: 利用循环函数中的跨行引用机制,简单用两个表达式就能按照上述思路计算出 W 日新高的标志 high1、 W 日内有新高的标志 high2。
A4 中的 group@o 是相邻记录分组,相当于按照原来的顺序,合并 high2 相同相邻记录。然后过滤出 high2 为 1,且长度 >=W 的分组,也就是 W 日内必有新高的波段。
A5 循环处理 A4 的这些波段,调用子程序 stockFunc 继续寻找上升波段,子程序的参数是 A5 当前成员。C5 把子程序返回的结果写到 B4 的结果集中。
SPL IDE 支持进入子程序单步执行,光标在调用子程序的格子 B5 时,点击菜单栏上的“单步进入”按钮即可:
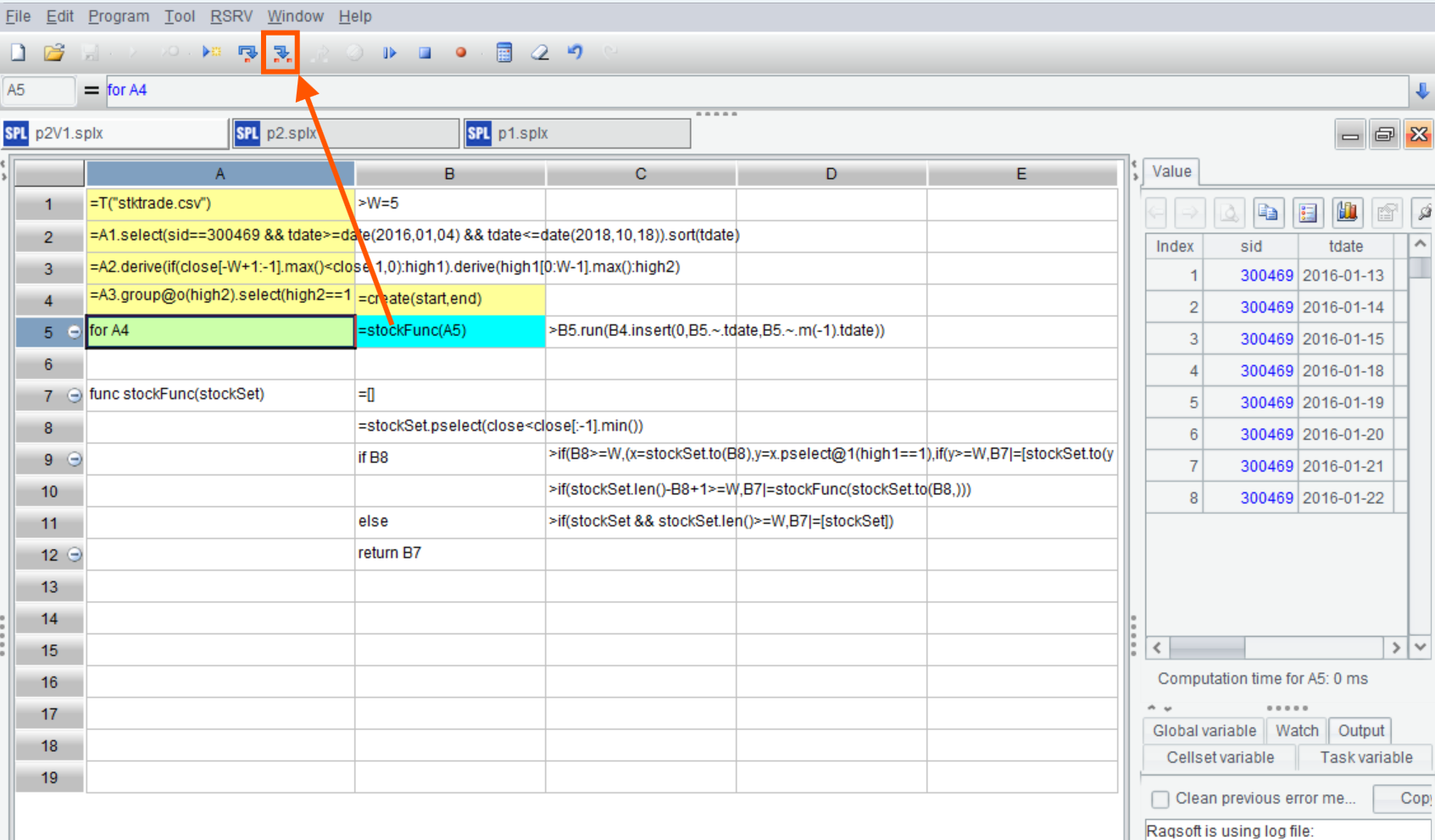
在子程序 stockFunc 中,B8 利用跨行引用机制,查找 stockSet 集合中收盘价新低的位置。
C9 中 x、y 是临时变量。x 是新低以前的记录集合(包括新低),y 是 x 中第一条 high1 为 1 的记录位置。按照前述思路,如果 y>=W,那么 stockSet 中前 y 条记录就是符合要求的波段,加入结果 B7。
子程序中同样可以在预览窗口观察计算结果:
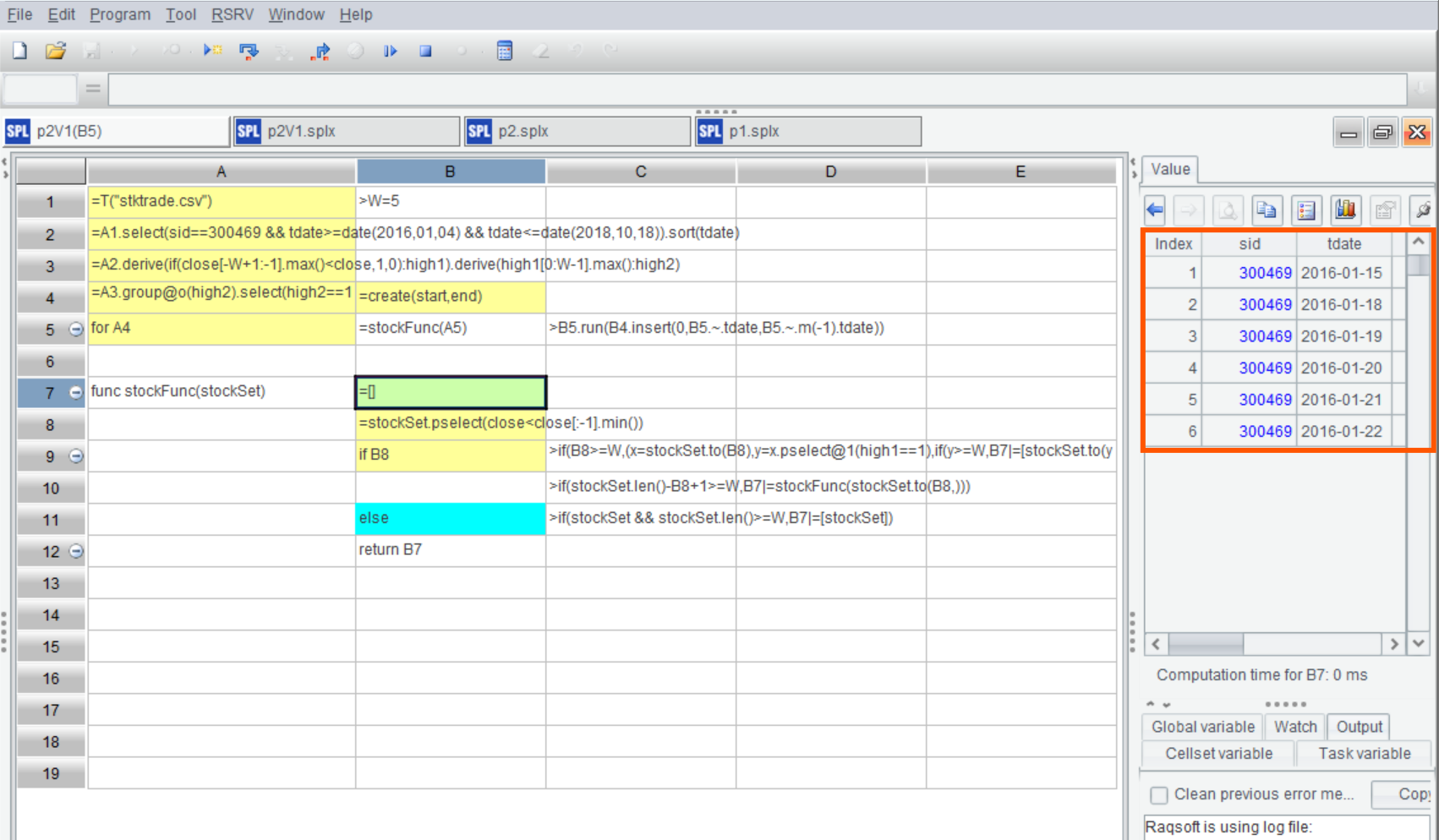
C10: 按照前述思路,用新低以后的数据组成新的波段,作为参数调用 stockFunc 继续查找目标波段。这是对 stockFunc 子程序的递归调用。
C11: 若没有新低且长度 >W,则整个集合是一个目标波段,加入结果。


点击此处下载数据文件
英文版