


数据分析编程从 SQL 到 SPL:股票指标计算
数据结构和样例数据:
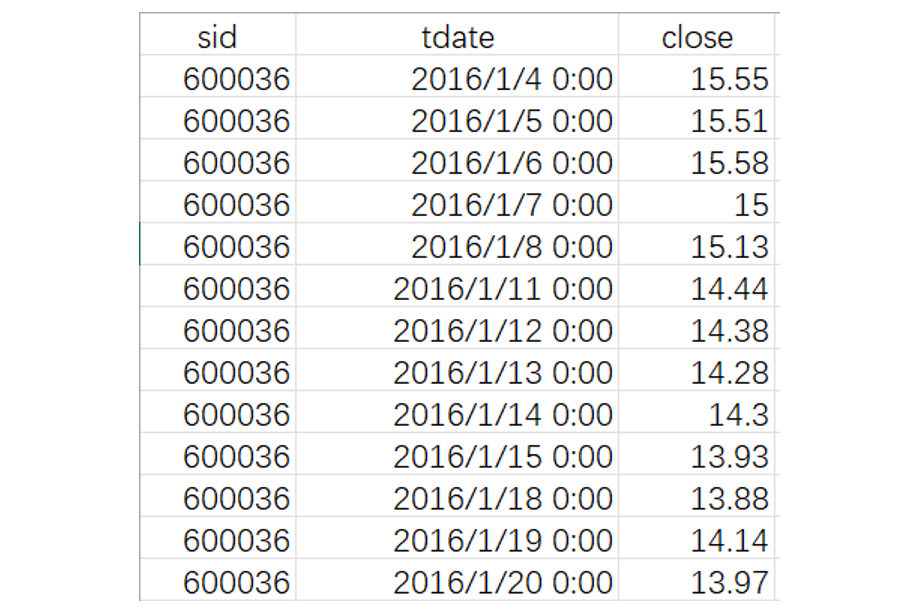
其中 sid 是股票代码,tdate 是交易日期,close 是收盘价。
1. 计算每日收盘价的 12 日 EMA
某支股票上市第 1 天的 n 日 EMA 为当日收盘价。
n 日 EMA=(前一日的 n 日 EMA*(n-1)+ 当日收盘价 *2)/(n+1)。
n 为 12 时称为 12 日 EMA,简写为 e12。
现在要计算股票 600036 每个交易日的 12 日 EMA,
写出 SQL 语句:
with recursive tbl as (
select tdate, close, row_number() over(order by tdate) rn
from stktrade where sid='600036'),
tbl2 as (
select tdate,close, cast(close as decimal(22,16)) e12, rn
from tbl where rn=1
union all
select t1.tdate, t1.close, (t1.close*2+t2.e12*11)/13, t1.rn
from tbl t1 join tbl2 t2 on t1.rn-1=t2.rn
)
select * from tbl2;
每日 e12 都要基于上一日的 e12 来计算,SQL 先使用窗口函数人为造出序号,再用递归方式计算,理解、编写以及调试的过程都很困难。
更符合自然思维的解题步骤是这样:将该股票的数据按日期排序,上一条记录就是上一个交易日的数据。增加一个计算列 e12,除第一条记录 e12 等于 close 外,循环用每条记录的收盘价和上一条记录的 e12 计算得出当前行的 e12,即可得到下面的表:
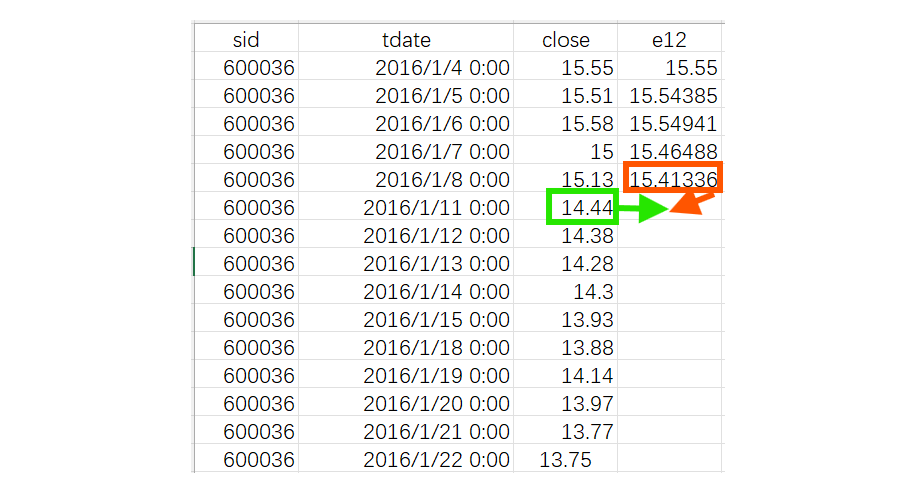
当所有记录都遍历过后,就得到期望的结果了。
可是,SQL 对过程式计算的支持力度太弱,不用存储过程很难实现这个思路。
SPL 有和常规程序语言一样的过程式计算能力,可以轻松实现上述思路:
A |
|
1 |
=T("stock.csv").select(sid==600036).sort(tdate) |
2 |
=A1.derive(if(#==1,close,(2*close+11*e12[-1])/13):e12) |
A1 从 csv 文件中读入股票数据,过滤出代码为 600036 的股票数据,按照交易日期排序。
A2 就是实现上面讲过的思路,计算出 e12 列。这里 derive 是循环函数,直接针对集合实施循环处理,不必再写 for…next 这样的多条语句块。
SPL 在循环函数中支持跨行引用,表达式中的 e12[-1] 就是上一行的计算得到的 e12 值。# 是循环计算中当前行的次序号。
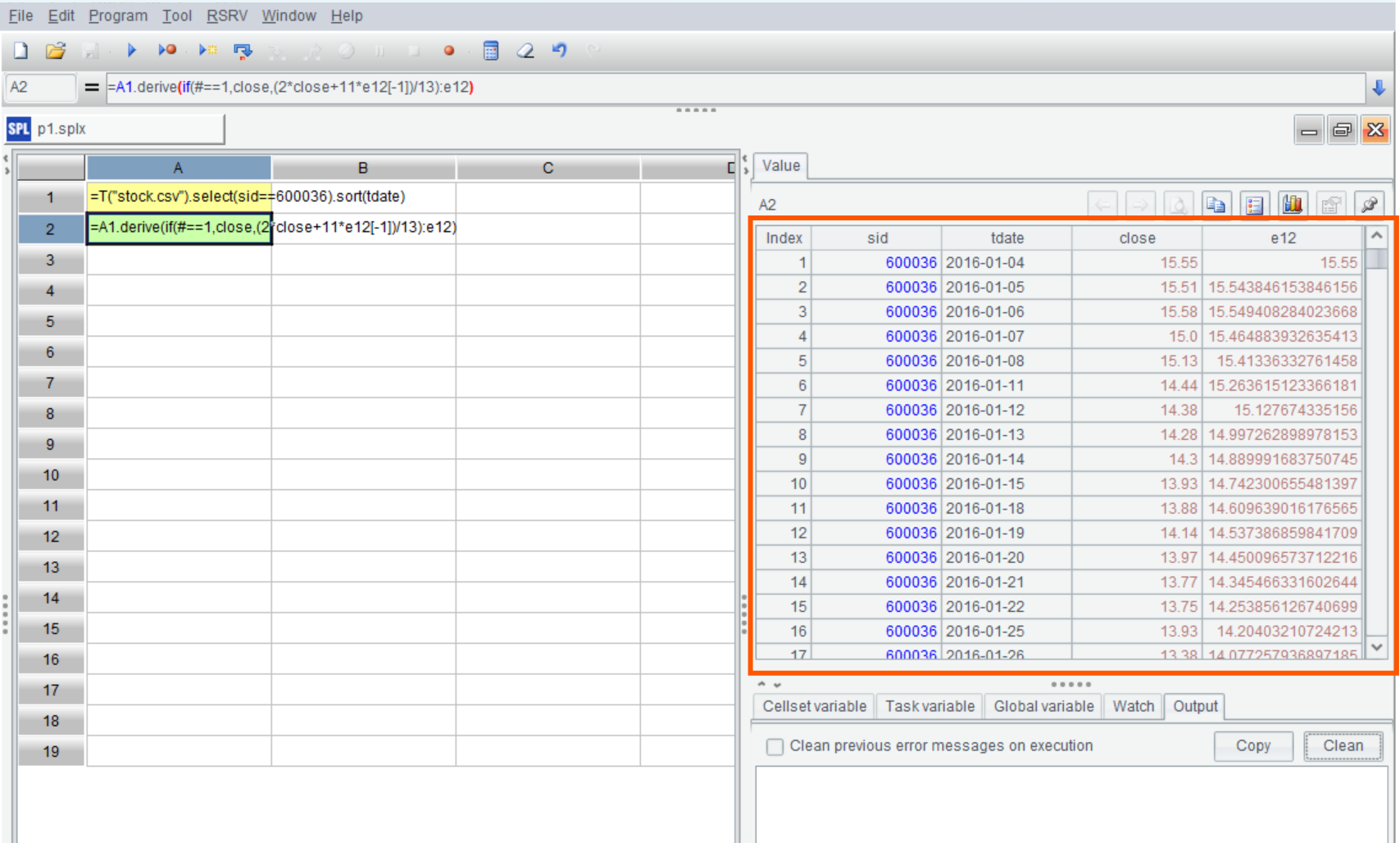
SPL 的 IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果:
2. 计算 MACD 指标
MACD 是股票分析中常见的趋势指标,相关计算公式如下 :
快线 12 日 EMA=(前一日 EMA*11+ 今日收盘价 *2)/13
慢线 26 日 EMA=(前一日 EMA*25+ 今日收盘价 *2)/27
离差 DIFF = 今日 12 日 EMA- 今日 26 日 EMA
离差均线 DEA = (前一日 DEA*8+ 今日 DIFF*2)/10
MACD = 2*(DIFF-DEA)
现在要计算 600036 股票每个交易日的 MACD 指标。
写出 SQL:
with recursive tbl as(
select tdate, close, row_number() over(order by tdate) rn
from stktrade where sid='600036'
),
tbl2 as(
select tdate,close, cast(close as decimal(22,16)) e12,
cast(close as decimal(22,16)) e26, rn
from tbl where rn=1
union all
select t1.tdate, t1.close, (t1.close*2+t2.e12*11)/13,
(t1.close*2+t2.e26*25)/27, t1.rn
from tbl t1 join tbl2 t2 on t1.rn-1=t2.rn
),
tbl3 as (
select tdate,close,e12, e26, e12-e26 diff,rn
from tbl2
),
tbl4 as (
select tdate,close,e12,e26, diff,diff dea,rn
from tbl3 where rn=1
union all
select t3.tdate, t3.close, t3.e12, t3.e26, t3.diff, (t3.diff*2+t4.dea*8)/10, t3.rn
from tbl3 t3 join tbl4 t4 on t3.rn-1=t4.rn
)
select tdate,close,e12,e26,diff,dea,2*(diff-dea) macd
from tbl4;
前面代码理解后,增加这些公式的计算并不难,但代码显得更繁琐了,而且 DEA 还要再次使用递归计算。
SPL 继续自然思路,只要在上个任务的 derive 函数中增加一些表达式并再多做一步 derive 就可以了:
A |
|
1 |
=T("stock.csv").select(sid==600036).sort(tdate) |
2 |
=A1.derive(if(#==1,close,(2*close+11*e12[-1])/13):e12,if(#==1,close,(2*close+25*e26[-1])/27):e26) |
3 |
=A2.derive(e12-e26:diff, if(#==1,diff,(2*diff+8*dea[-1])/10):dea, 2*(diff-dea):macd) |
代码复杂度几乎没有变化,还是很简单易懂。
3. 查找金叉与死叉
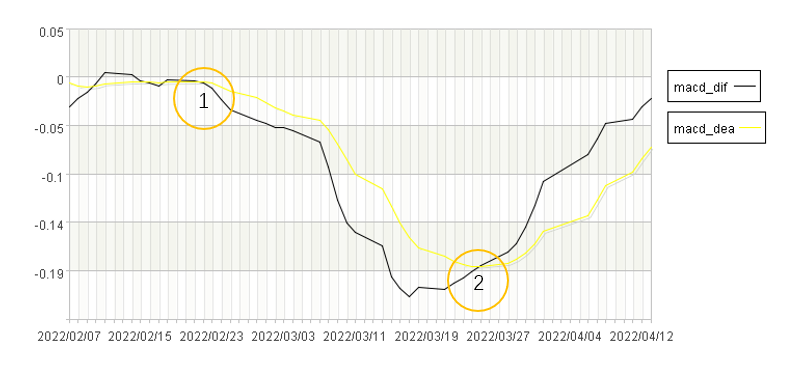
某交易日的前一日 DIFF 小于 DEA,后一日 DIFF 大于 DEA,则这个交易日称为金叉。
某交易日的前一日 DIFF 大于 DEA,后一日 DIFF 小于 DEA,则这个交易日称为死叉。
下图中 2 的位置是金叉,1 的位置是死叉:
现在要查出 600036 股票所有的金叉与死叉交易日。
SQL:
with recursive tbl as (
select tdate, close, row_number() over(order by tdate) rn
from stktrade
where sid='600036'
),
tbl2 as (
select tdate,close, cast(close as decimal(22,16)) e12,
cast(close as decimal(22,16)) e26, rn
from tbl where rn=1
union all
select t1.tdate, t1.close, (t1.close*2+t2.e12*11)/13,
(t1.close*2+t2.e26*25)/27, t1.rn
from tbl t1 join tbl2 t2 on t1.rn-1=t2.rn
),
tbl3 as (
select tdate,close,e12, e26, e12-e26 diff,rn
from tbl2
),
tbl4 as (
select tdate,close,e12,e26, diff,diff dea,rn
from tbl3 where rn=1
union all
select t3.tdate, t3.close, t3.e12, t3.e26, t3.diff, (t3.diff*2+t4.dea*8)/10, t3.rn
from tbl3 t3 join tbl4 t4 on t3.rn-1=t4.rn
),
tbl5 as (
select tdate,close,e12,e26,diff,dea,2*(diff-dea) macd,
case when rn=1 then 0
when lag(diff) over(order by rn)<lag(dea) over(order by rn) and diff>dea then 1
when lag(diff) over(order by rn)>lag(dea) over(order by rn) and diff<dea then -1
else 0 end `cross`
from tbl4
)
select * from tbl5 where `cross`<>0;
又增加了一层子查询,还要增加窗口函数,代码变得更长、更繁琐。
上个任务的 SPL 代码已经得到 DIFF 和 DEA,现在只要再多一步即可计算出金叉死叉:
A |
|
1 |
=T("stock.csv").select(sid==600036).sort(tdate) |
2 |
=A1.derive(if(#==1,close,(2*close+11*e12[-1])/13):e12,if(#==1,close,(2*close+25*e26[-1])/27):e26) |
3 |
=A2.derive(e12-e26:diff, if(#==1,diff,(2*diff+8*dea[-1])/10):dea, 2*(diff-dea):macd) |
4 |
=A3.derive(if(diff[-1]<dea[-1]&&diff>dea:1,diff[-1]>dea[-1]&&diff<dea:-1;0):cross) |
5 |
=A4.select@a(cross!=0) |
A4 在 A3 的步骤之后再进行一次循环计算得到金叉死叉标志 cross,思路清晰。
A5 用 select@a 函数,得到所有符合 cross!=0 条件的结果,也就是所有的金叉和死叉。
4. 查找 MACD 顶背离
将股票数据按照交易日顺序划分成不同区间,如果后面区间的收盘价(或其他指标)最大值大于前面相邻区间最大值,称为收盘价(或其他指标)创新高。如果小于,则称为没有创新高。
MACD 顶背离是指相邻的两个金叉到死叉区间收盘价创新高,但 DIFF 没有创新高:
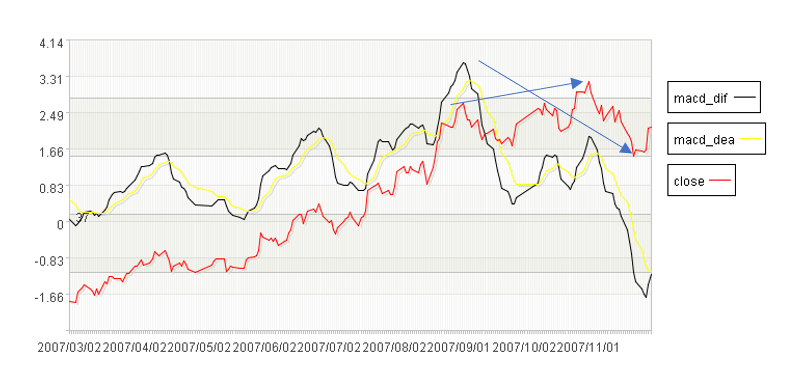
上图中箭头处,股票价格还在持续上升,但 macd 指标背离式走低,出现顶背离。
现在要查找股票 600036,所有 MACD 顶背离的两个区间中,第一个区间的最后一条记录。
SQL 实在过于复杂,不再尝试了。
SPL 上个任务已经计算出金叉和死叉的位置序号了。在此基础上,继续查找金叉到死叉的区间位置。然后再判断相邻两个区间的收盘价和 DIFF 是否创新高:
A |
|
1 |
=T("stock.csv").select(sid==600036).sort(tdate) |
2 |
=A1.derive(if(#==1,close,(2*close+11*e12[-1])/13):e12,if(#==1,close,(2*close+25*e26[-1])/27):e26) |
3 |
=A2.derive(e12-e26:diff, if(#==1,diff,(2*diff+8*dea[-1])/10):dea, 2*(diff-dea):macd) |
4 |
=A3.derive(if(diff[-1]<dea[-1]&&diff>dea:1,diff[-1]>dea[-1]&&diff<dea:-1;0):cross,0:topdev) |
5 |
=A4.pselect@a(cross==1) |
6 |
=A5.(A4.to(A5.~, A4.pselect(cross==-1,A5.~))) |
7 |
>A6.run(if(#>1&&~[-1].max(close)<~.max(close)&&~[-1].max(diff)>~.max(diff),~.m(-1).topdev=1)) |
=A4.select(topdev==1) |
A4 准备一个值为 0 的计算列 topdev,用于标记目标记录。
A5 查出所有金叉的位置序号,SPL 有丰富的位置运算能力,过滤时不仅可以返回满足条件的成员,还可以返回这些成员的位置。
A6:对 A5 中的金叉位置序号循环。A4.pselect(cross==-1,A5.~) 会得到该金叉之后的第一个死叉的位置。这样 A6 计算结果就是所有金叉到死叉区间:
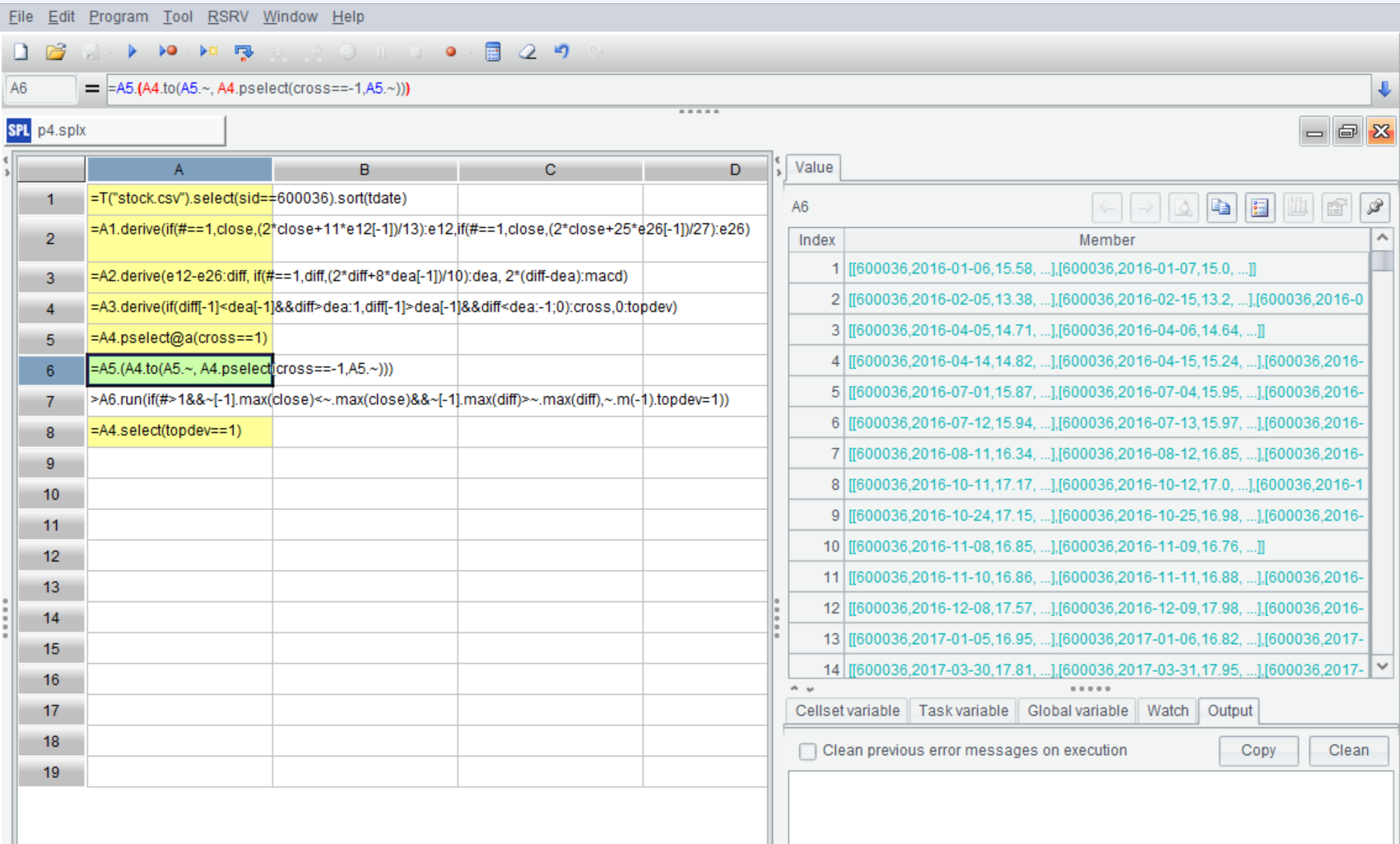
双击结果中的成员,可以查看详细情况。比如第五个成员:
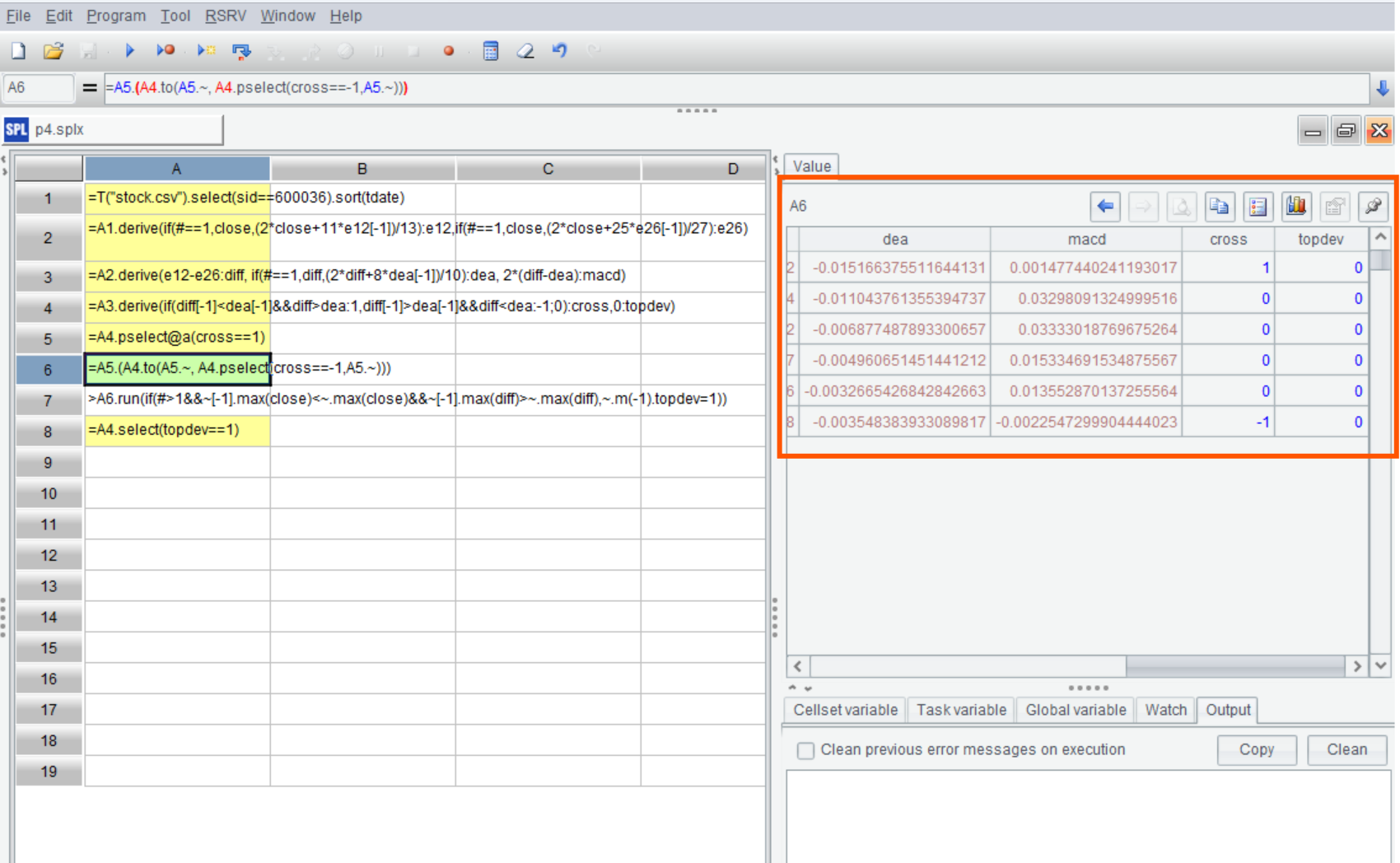
可以看到这是金叉(cross 为 1)到死叉(cross 为 -1)的区间。
A7:循环 A6,找出符合 MACD 线背离条件的相邻区间,并把其中第一个区间最后一条记录的 topdev 值赋值为 1。
A6 的成员是 A4 序表的排列,并没有产生新的序表,所以 A7 实际上是把 A4 序表目标记录的 topdev 赋值为 1。
A8 过滤 A4,得到期望的结果。


点击这里下载数据文件
英文版