


数据分析编程从 SQL 到 SPL:人口和语言分析
数据结构
国家表 world.country
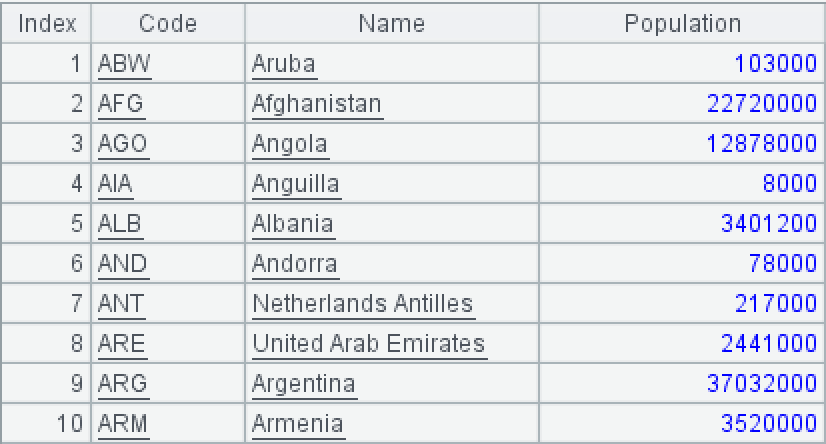
Code 是国家编码,Name 是国家名称,Population 是国家人口。
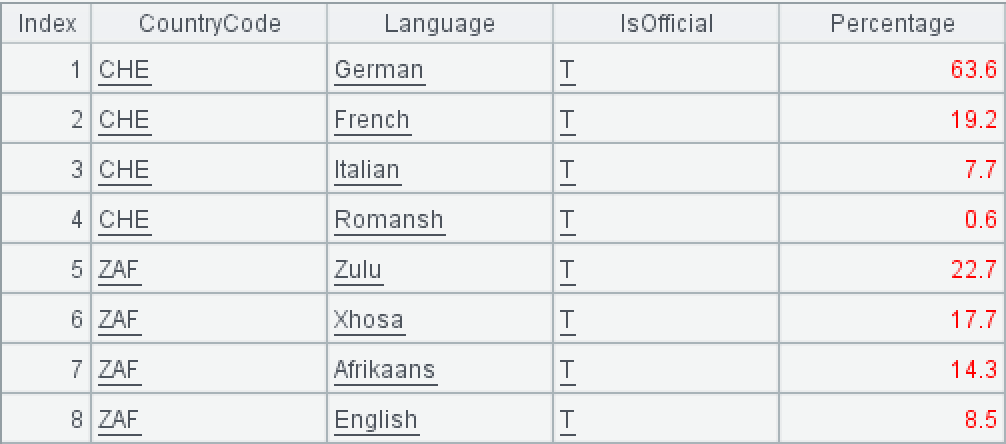
国家语言表 world.countrylanguage
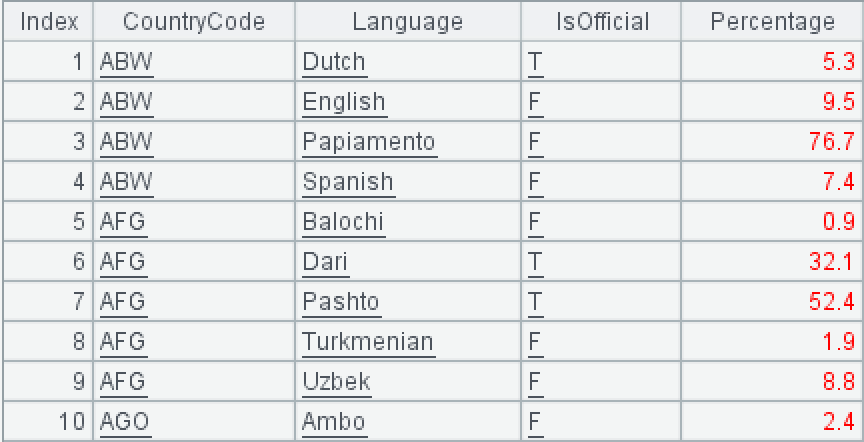
CountryCode 是国家编码,Language 是语言,IsOfficial 是否官方语言(T 代表是官方语言),Percentage 是使用该语言的人口百分比。
1. 查询官方语言最多的国家、人口及官方语言数
通过示例数据可以看到,每个国家使用的语言可能有多种,其中有官方语言也有非官方语言。
SQL 语句如下:
with t1 as (
select CountryCode, count(*) Num
from world.countrylanguage
where isOfficial='T'
group by CountryCode),
t2 as (
select *
from t1
where Num=(select Max(Num) from t1))
select Name,Population,Num
from world.country c join t2
on c.Code=t2.CountryCode;
SQL 语句在使用了窗口函数后仍要嵌套多层,比较繁琐。主要是因为 SQL 的分组功能总是和汇总同时出现,而且支持的聚合函数有限。
这个问题其实很简单,将国家语言表按照国家分组,选出语言数量最多的组的所有记录,再从国家表中找到对应的国家名称和人口数量即可。
SPL 支持独立的分组运算,这样更方便分步运算,还有更多的聚合方式。SPL 脚本如下:
A |
|
1 |
=T("country.txt") |
2 |
=T("countrylanguage.txt").select(IsOfficial=="T") |
3 |
=A2.group(CountryCode;count(~):Num).maxp@a(Num) |
4 |
=A3.switch(CountryCode,A1:Code).new(CountryCode.Name,CountryCode.Population,Num) |
A1: 读取国家表。
SPL 的 IDE 有很好的交互性,可以执行后在右边的值面板中直观地查看到每一步的结果:
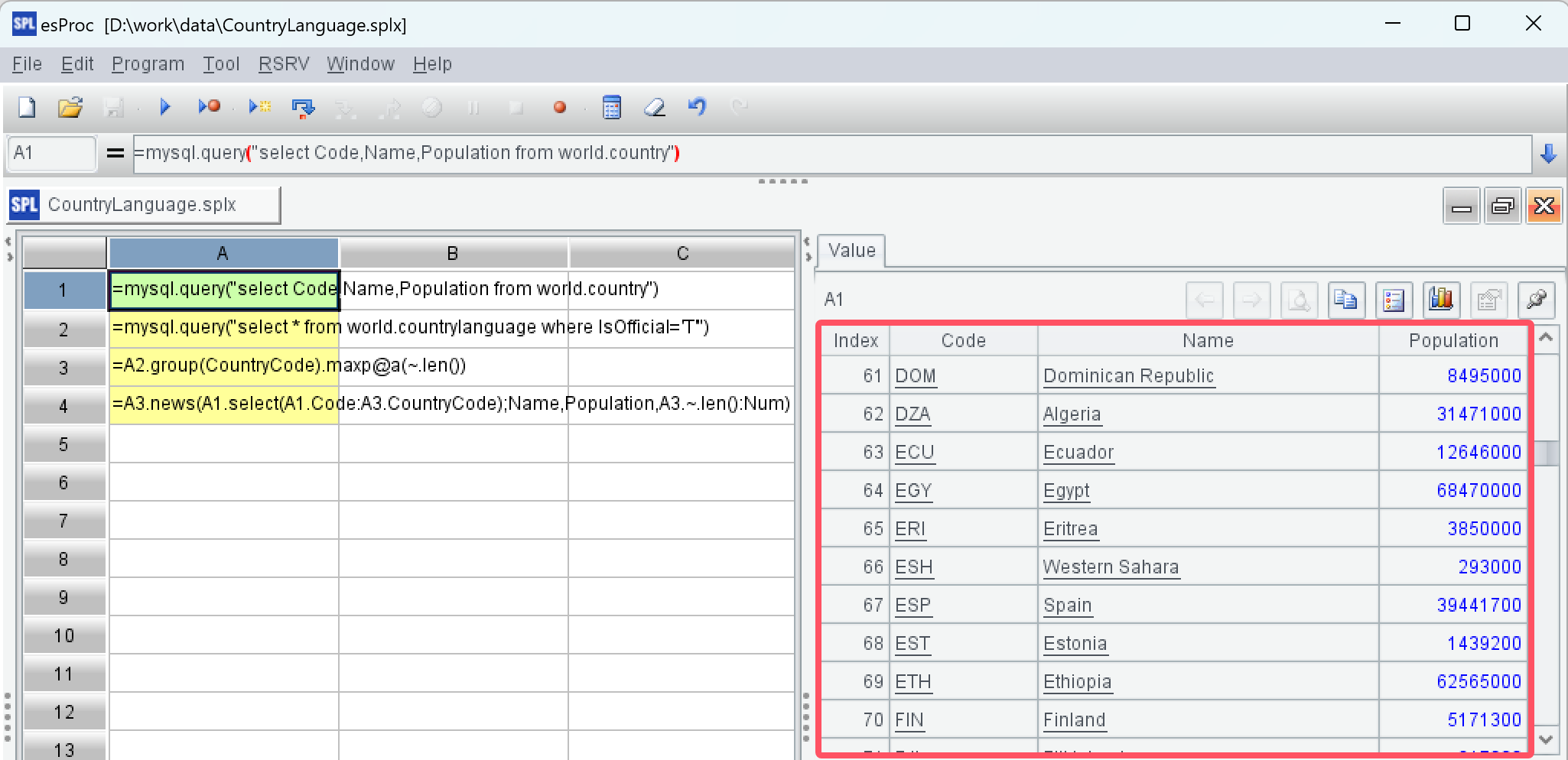
A2: 读取国家语言表,选出官方语言。
A3: 按国家编号分组,并取出成员最多的所有组的记录。官方语言数最多的国家可能有多个,这里使用了函数 maxp 的选项 @a,用于返回所有使计算表达式的值最大的成员。
在 IDE 中点击 A3 时可以看到选出了两个结果:

A4: 将 A3 的国家编号外键对象化,并构造出需要的目标结构。
首先把国家编号转换为对应的国家记录:
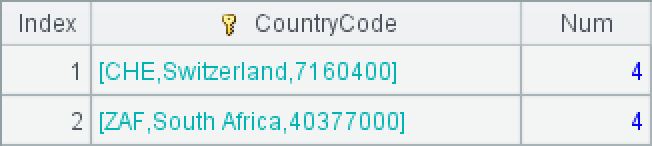
双击国家编号,可以看到对应的国家记录:

然后构造出目标结构:

2. 查询官方语言最多的国家名称、人口、使用最多的官方语言及人口比例
这个问题比问题 1 多了一步,需要选出使用最多的官方语言。
SQL 语句如下:
with t1 as (
select CountryCode, count(*) Num,
RANK()OVER (ORDER BY COUNT(*) DESC) AS rk
from world.countrylanguage
where isOfficial='T'
group by CountryCode),
t2 as (
select *
from t1
where rk=1),
t3 as (
select cl.CountryCode, Language, Percentage
from world.countrylanguage cl join t2
on cl.CountryCode=t2.CountryCode),
t4 as (
select CountryCode, max(Percentage) MaxP
from t3
group by CountryCode),
t5 as (
select t3.CountryCode, t3.Language, t3.Percentage
from t3 join t4
on t3.CountryCode=t4.CountryCode and t3.Percentage=t4.MaxP)
select c.Name,c.Population,t5.Language,t5.Percentage
from world.country c join t5
on c.Code=t5.CountryCode;
虽然只是增加了一步选出最大值,但是 SQL 语言的复杂程度却增加了很多。主要是因为 SQL 的分组功能总是和汇总同时出现,无法保留分组子集再运算。
对于 SPL,还是按自然逻辑,只要在问题 1 的基础上选出使用最多的官方语言即可:
A |
|
1 |
=T("country.txt") |
2 |
=T("countrylanguage.txt").select(IsOfficial=="T") |
3 |
=A2.group(CountryCode).maxp@a(~.len()).(~.maxp(Percentage)) |
4 |
=A3.switch(CountryCode,A1:Code).new(CountryCode.Name,CountryCode.Population,Language,Percentage) |
A1/A2: 读取国家表和国家语言表并选出官方语言。
A3: 按国家编码分组,并取出元素最多的组,然后在每组中查找比例最大的记录。

A4: 将 A3 的国家编号外键对象化,并构造出需要的目标结构。

这个 SPL 脚本相比问题 1 并没有复杂很多,这主要得益于 SPL 支持独立的分组运算,在分组后保留了分组子集。后续想要选出种类最多、使用最多的语言时,可以继续使用分组子集进行各种运算。
3. 将官方语言最多的国家的官方语言及使用比例在同一行按从大到小排列
期待的目标结果集是这样的:

可以看到,目标数据结构是由数据计算而来的,不是固定不变的。普通的 SQL 不能解决这样的问题,需要使用动态 SQL,实现起来很繁琐,这里就不再给出 SQL 的解决方案了。
SPL 解决这个问题仍不复杂,只要在问题 1 基础上,将官方语言最多的国家按照使用比例排序,再构造出目标数据结构即可:
A |
|
1 |
=T("countrylanguage.txt").select(IsOfficial=="T") |
2 |
=A1.group(CountryCode).maxp@a(~.len()).conj().sort(CountryCode,-Percentage) |
3 |
=A2.groupc(CountryCode;Language,Percentage) |
4 |
>A3.rename(${(A3.fno()\2).("#"/(2*#)/":Language"/#/",#"/(2*#+1)/":Percentage"/#).concat@c()}) |
A1: 读取国家语言表并选出官方语言。
A2: 按国家编号分组,并取出成员最多的所有组的记录。再将这些记录拼成一个序列,并按照国家编号和使用比例排序,其中使用比例降序排列。
A3:将相同国家编号及所有的语言和使用比例转到同一行。这里使用函数 groupc,对序列的序列执行行列转换计算。

A4:将 A3 第 2 列及以后的列名依次改成 Languagei和 Percentagei:
数据文件附件:


IMHO,最后一题 A4 写复杂了🙏 😄
groupc 有第 3 参数指定字段名,且多余的字段名会自动丢弃,按此特性可以用 eval@s 先构造待用字段名:
脚本看起来很简洁👍
但是 A3 这里要写个足够大又不应该特别大的常量,有点别扭。
或者可以先把 ~.len() 求出来再创建数据结构,脚本多一点效率并不会低。
谢谢大佬认可🙏 我是不自量力,在大佬面前班门弄斧了😄🙏
稍大的常量主要是不烧脑😄 要精确控制那个字段名,可以把 A2 拆成两步写,
一步分组,一步 conj()+sort(),分组那一步可以知道数量,如下:
这种写法充分利用了 groupc 函数,使用的非常好了。
英文版