


数据分析编程从 SQL 到 SPL:股票连涨分析
本文讨论股票连涨问题,为了避免歧义,这里约定:股票连涨天数包括起始的 1 天,比如连涨 5 天意味着这 5 天内股票都在上涨,实际上只有从第 2 天开始的 4 次上涨。
数据结构和样例数据:
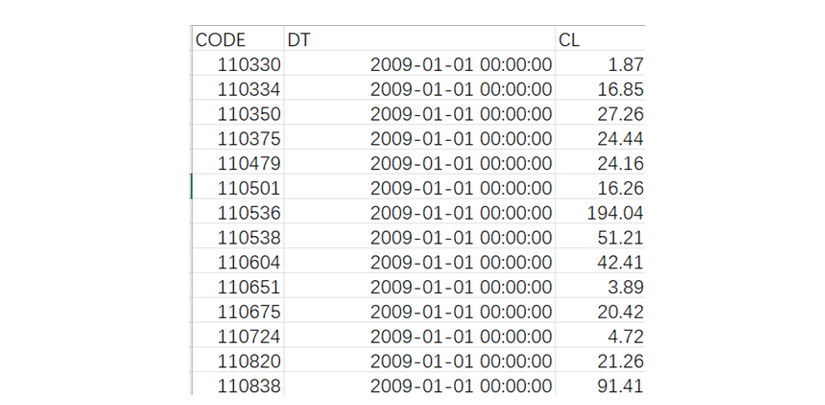
其中 CODE 是股票代码,DT 是交易日期,CL 是收盘价。
1. 某支股票最长连涨天数
以代码是 100046 的股票为例,写出 SQL 语句:
select max(ContinuousDays)
from (
select count(*) ContinuousDays
from (
select sum(UpDownTag) over (order by DT) NoRisingDays
from (
select DT,
case when CL>lag(CL) over ( order by DT) then 0
else 1 end UpDownTag
from Stock
where CODE=100046))
group by NoRisingDays )
这个语句使用窗口函数后仍然有多层嵌套,读懂都很困难,编写、调试的过程就更困难了。
其实,这个问题并不难,容易想出符合自然思维的解题步骤:将该股票的数据按日期排序,上一条记录就是上一个交易日的数据。再准备一个变量存储连涨天数,初值为 1。用每条记录的收盘价和上一条记录的收盘价比较,如果涨了则将该变量加 1,未涨则将其重置为 1。我们把每条记录对应的这个变量值记入一个新的 UP 列中,即可得到下面的表:
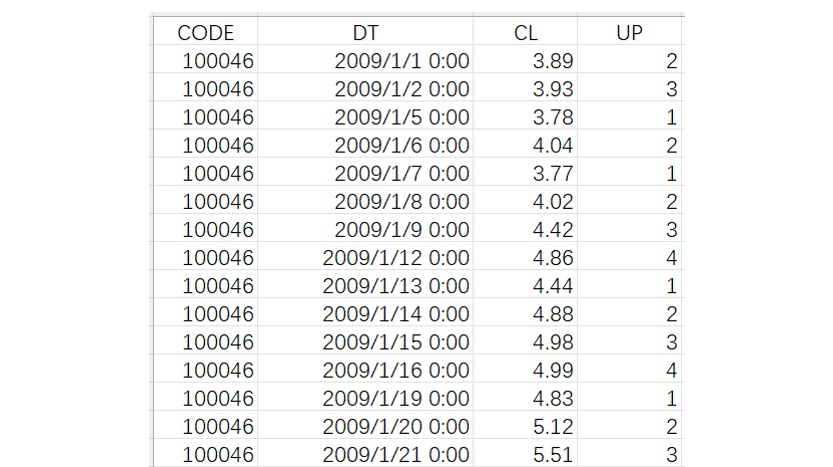
当所有记录都遍历过后,UP 列的最大值就是最长的连涨天数。
但 SQL 对过程式计算的支持力度太弱,不用存储过程很难实现这个思路。上面那句 SQL 实际上是换了一种方法:累计从初始日期到当日的未上涨天数。对于连续上涨的交易日,对应的累计未上涨天数都相同。那么按这个累计未上涨天数分组就能得到一些连续上涨的区间,再求分组计数的最大值,即可得到结果。
这个方法的关键在于把数据分组,每个组都是连涨的日期区间,但 SQL 没有直接提供有序分组,只能借助累计未上涨天数将有序分组转换成普通的等值分组,整个过程非常绕。判断上涨和计算累计值都需要窗口函数配合子查询才能实现,结果就是两个窗口函数且嵌套四层的情况,代码难写难懂。
SPL 有和常规程序语言一样的过程式计算能力,可以轻松实现前面讲的自然思路。SPL 特有的循环函数还可以避免编写多句循环结构代码:
A |
B |
|
1 |
=T("StockRecords.xlsx") |
=A1.select(CODE==100046) |
2 |
=B1.sort(DT) |
=1 |
3 |
=A2.derive(B2=if(CL>CL[-1],B2+1,1):UP) |
|
4 |
=A3.max(UP) |
A1 从 excel 文件中读入股票数据。SPL 的 IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果:
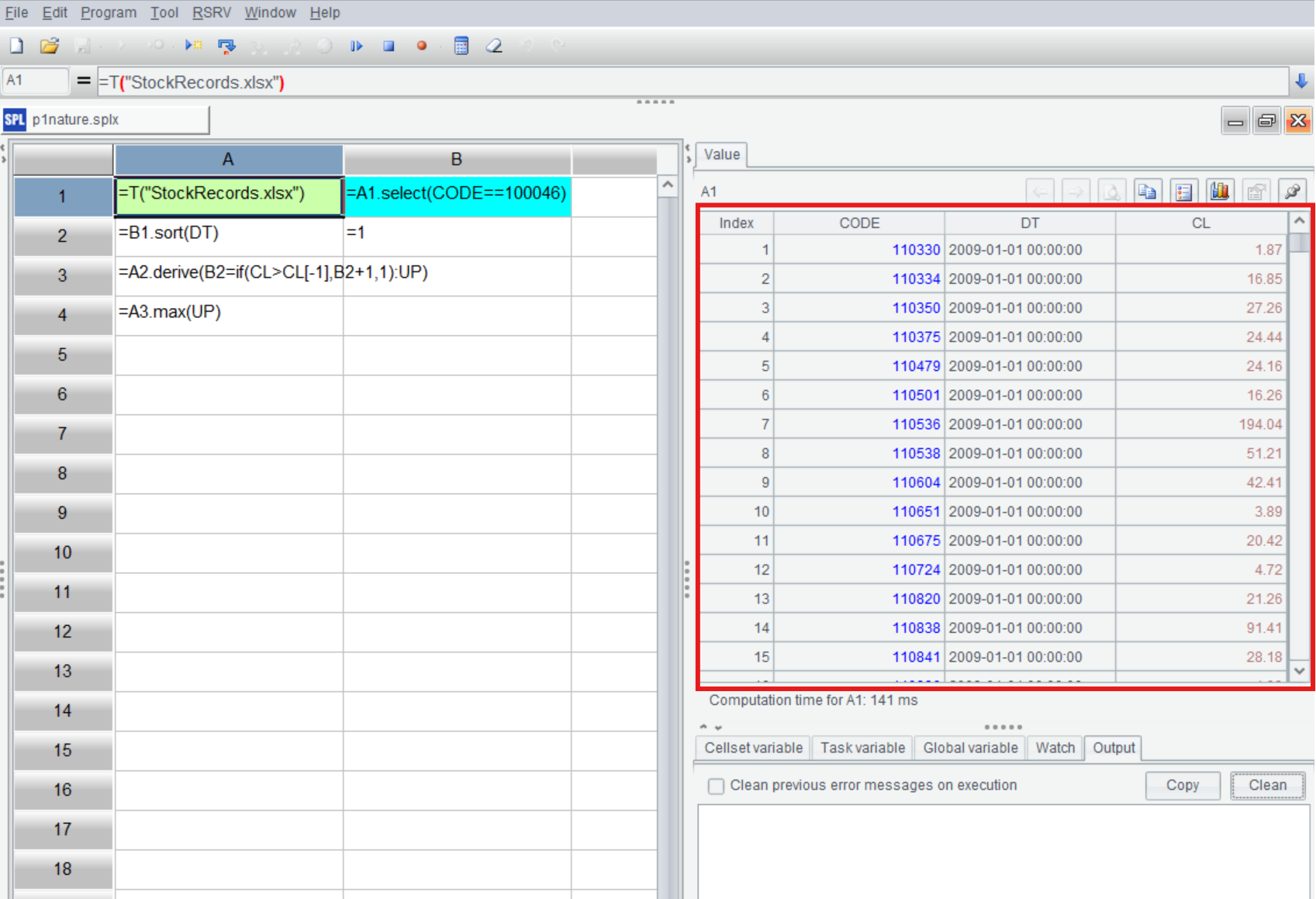
B1 过滤出代码为 100046 的股票数据,A2 按照交易日期排序,B2 用作前面说的变量,初值是 1。
A3 就是实现上面讲过的思路,计算出 UP 列。这里 derive 就是一个循环函数,直接针对集合实施循环处理,不必再写 for…next 这样的多条语句块。SPL 在循环函数中支持跨行引用,简单用 CL>CL[-1] 就可以判断出是否上涨,其中 CL[-1] 就是上一行的收盘价。
A4 计算 UP 的最大值,得到最长连涨的天数。
熟悉 SPL 编程后,可以把关键计算逻辑写到一起,省略生成 UP 列:
A |
|
1 |
=1 |
2 |
=T("StockRecords.xlsx").select(CODE==100046) |
3 |
=A2.sort(DT).max(A1=if(CL>CL[-1],A1+1,1)) |
SPL 还有很强的有序计算能力,即使实现前面那句 SQL 的思路也更简单:
A |
B |
|
1 |
=T("StockRecords.xlsx") |
=A1.select(CODE==100046) |
2 |
=B1.sort(DT) |
|
3 |
=A2.group@i(CL<=CL[-1]) |
|
4 |
=A3.max(~.len()) |
A3 中 group@i 是 SPL 特有的有序分组函数,它会在参数表达式 CL<=CL[-1] 为真时,也就是股票没有涨价的情况下,产生新的分组。可以利用日期的有序性,直接把连续上涨的记录分到同一组,避免了像 SQL 那样先算累计值,再用累计值等值分组来凑出有序分组的复杂计算。
类似地,光标落在 A3 时,可以在右边面板中看到其计算结果:
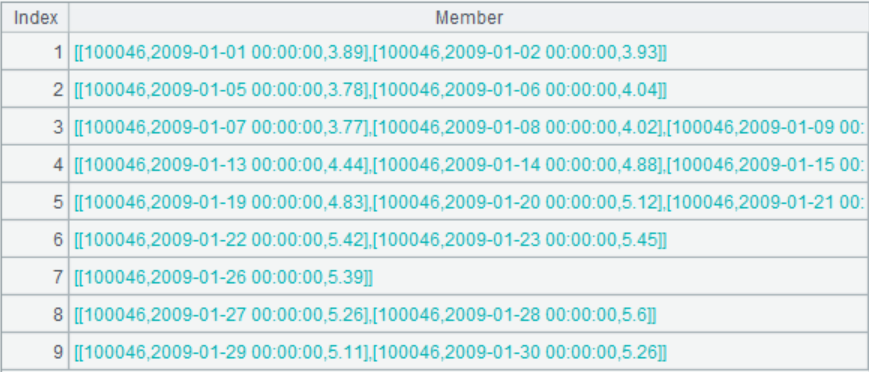
其中的成员是连涨记录构成的分组子集,比如第三个成员,双击可以查看详细情况:
A4 中计算各组的长度,求最大值即可得到最长连涨的天数,不需要用临时变量来计数了。
这些代码中的关键逻辑也可以拼成一句:
A |
|
1 |
=T("StockRecords.xlsx").select(CODE==100046).sort(DT) |
2 |
=A1.group@i(CL<=CL[-1]).max(~.len()) |
2. 某支股票最长连涨区间的起止日期
从统计连涨区间的天数改成返回区间的起止日期,看起来仅仅多了一步,但 SQL 会麻烦很多,要先计算最长连涨的天数,再找对应的起止日期:
with t1 as (
select DT, CL,
case when CL>lag(CL) over(order by DT) then 0 else 1 end UpDownTag
from stock
where CODE='100046'),
t2 as (
select DT, CL, sum(UpDownTag) over(order by DT) NoRisingDays
from t1),
t3 as (
select NoRisingDays, count(*) ContinuousDays
from t2 group by NoRisingDays),
t4 as (
select *
from t2
where NoRisingDays in (
select NoRisingDays
from t3
where ContinuousDays =(select max(ContinuousDays) from t3)
))
select min(DT) start, max(DT) end
from t4
group by NoRisingDays;
因为要复用其中的子查询,不适合再写成嵌套结构,这里改用 CTE 语法写出,代码更长了。
SQL 分组时必须强制聚合,不能保留分组子集,汇总出最长的连涨天数后,还要再重新查询出对应的明细数据,从而得到起止日期,以至于代码变得更复杂也更难懂。
SPL 能保持分组子集,在上个问题基础上简单增补就可以了:
A |
|
1 |
=T("StockRecords.xlsx").select(CODE==100046).sort(DT) |
2 |
=A1.group@i(CL<CL[-1]).maxp@a(~.len()) |
3 |
=A2.new(~(1).DT:start,~.m(-1).DT:end) |
A2 用 maxp@a 代替原来的 max,计算出所有最长连涨区间。maxp 会返回取到最大值的成员而不是最大值本身,这也是 SPL 特有而 SQL 没有的聚合函数,@a 表示如果有多个成员都能取到最大值则全部返回,SPL 到处都能体现出集合特征。
A3 用 new 生成目标结果集,其中 ~.m(1) 和 ~.m(-1) 分别取其中集合的第一个和最后一个成员,SPL 的集合都有序,可以用位置访问。
3. 找出最长连涨天数超过 5 天的股票
比任务 1 多了一步,先计算出每支股票的最长连涨天数再过滤。用 SQL 要在窗口函数中增加分区字段 CODE:
select CODE, max(ContinuousDays) as longestUpDays
from (
select CODE, count(*) as ContinuousDays
from (
select CODE, DT,
sum(UpDownTag) over (partition by CODE order by CODE, DT) as NoRisingDays
from (
select CODE, DT,
case when CL > lag(CL) over (partition by CODE order by CODE, DT) then 0
else 1 end as UpDownTag
from stock
)
)
group by CODE, NoRisingDays
)
group by CODE
having max(ContinuousDays)>5
前面代码理解后,增加这一步倒不是很难,但代码显得更繁琐了。
SPL 可以保持分组子集而不必强制在分组时聚合,只要将数据按股票代码分组后,对每组执行前面的动作就可以了:
A |
|
1 |
=T("StockRecords.xlsx").sort(DT) |
2 |
=A1.group(CODE;~.group@i(CL<=CL[-1]).max(~.len()):max_increase_days) |
3 |
=A2.select(max_increase_days>5) |
A2 按照股票代码分组,然后对每个分组子集执行前面讲过的算法,计算出这支股票连涨天数。A2 中第一个 ~ 是按 CODE 分组的子集,第二个 ~ 则是 group@i 有序分组的子集。
A3 过滤出最长连涨天数大于 5 的记录。
4. 找出所有连涨超过 5 天的区间
SQL 分组时必须强制聚合,不能保留分组子集,找到连涨 5 天的股票后,要和任务 2 重新查询出这些股票的交易数据,代码太复杂也更难懂,这里就不再写了。
SPL 能保持分组子集,很容易解决这个问题:
A |
|
1 |
=T("StockRecords.xlsx").sort(CODE,DT) |
2 |
=A1.group@i(CODE!=CODE[-1] || CL<=CL[-1]) |
3 |
=A3.select(~.len()>5).conj() |
A2 分组条件的意思是股票代码和上一条不同或价格不涨时分新组。CODE[-1] 和 CL[-1] 类似,表示上一条记录的股票代码。由于数据整体上是对 CODE 有序的,这样可以保证不同的股票不会分到同一组。
A2 只做分组,不做聚合,保留了分组子集:
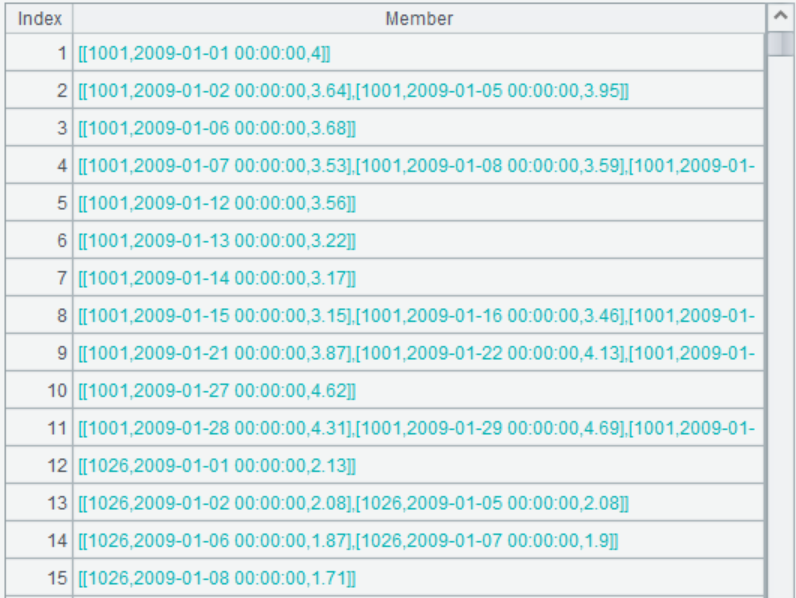
双击其中的成员,可以看到一次连涨区间内的所有记录。比如第 4 个成员:

A3 过滤出长度大于 5 的分组,再将这些分组子集合并起来,就得到了期望的结果。


英文版
点击这里下载数据文件
1、
Title: Find-Longest-Rising-Streak-for-a-Stock
URL: https://www.sqlazy.com/?4GL
Category: financial-analysis
Title: Find-Longest-Rising-Streak-for-a-Stock
URL: https://www.sqlazy.com/?4GL
Category: consecutive-trends
2、
Title: Find-When-the-Longest-Rising-Streak-Happened
URL: https://www.sqlazy.com/?4OY
Category: financial-analysis
Title: Find-When-the-Longest-Rising-Streak-Happened
URL: https://www.sqlazy.com/?4OY
Category: consecutive-trends
3、
Title: Find-Stocks-Rising-for-More-Than-3-Days
URL: https://www.sqlazy.com/?49V
Category: financial-analysis
Title: Find-Stocks-Rising-for-More-Than-3-Days
URL: https://www.sqlazy.com/?49V
Category: consecutive-trends
4、
Title: List-All-Rising-Streaks-Longer-Than-3-Days
URL: https://www.sqlazy.com/?4DR
Category: financial-analysis
Title: List-All-Rising-Streaks-Longer-Than-3-Days
URL: https://www.sqlazy.com/?4DR
Category: consecutive-trends