


这可能是最适合解决 SQL 数据分析痛点的编程语言
数据分析师的日常离不开各种数据操作,过滤、分组、汇总、排序……,面对这些基本需求,SQL 用起来确实得心应手。比如,查个用户分组销售额、筛选一批重要客户,这样的任务用 SQL 写出来就像英语一样简单,迅速搞定:
SELECT area, SUM(amount)
FROM sales
WHERE amount > 1000
GROUP BY area;
SQL 看起来像是“简单高效”的代名词,直接查询、直接返回结果——这也是它为什么成为数据分析标配工具的原因之一。但随着情况的变化,这种表面上的“简单”很快会被打破。
比如,要处理的是本地文件中的数据,而不是数据库里的表怎么办?这时 SQL 可能就不灵了,因为它本身就是“绑死”在数据库上的工具。相比之下,SPL (Structured Process Language)可以跳过“把数据装进数据库”的麻烦,从文件直接计算:
A |
|
1 |
=T("sales.txt") |
2 |
=A1.select(amount>1000) |
3 |
=A2.groups(area;sum(amount):total_amount) |
这段 SPL 代码实现了与上面 SQL 查询相同的逻辑,但更重要的是:不需要搭建数据库环境! 一个文本文件,几行代码就能直接分析。这种灵活性不仅省下了数据导入的时间,还大大降低了使用的门槛。
当然,现在也有些可以直接针对文件用 SQL 的技术了,这个麻烦还不是非常大。不过,这只是开始,面对更复杂需求时,SPL 的优势就会更突出了,尤其是当 SQL 显现出它的两大痛点——难写和难调试时,SPL 的设计思路会让这些痛点迎刃而解。
写起来不费劲,少掉三根头发
SPL:写代码如搭积木,复杂逻辑轻松搞定
我们都知道,现实中的分析需求往往不止“查个数、分个组”那么简单。以计算某支股票的最长连续上涨天数为例,复杂性来了,SPL 的代码却仍然精炼又清晰:
A |
|
1 |
=T(“StockRecords.txt”) |
2 |
=A1.sort(CODE,DT) |
2 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
第一步:从文本读取数据;
第二步:按股票和交易日排序;
第三步:按股票代码分组;并根据涨跌条件分组计算最大长度。
每一步都可以看作搭积木般的自然操作,无需写复杂的嵌套查询,SPL 的过程式语法让整个计算流程贴合分析师的思维模式。
SQL:写代码就像解数学竞赛题
再来看 SQL,为了同样的目标,它的写法堪称“脑细胞杀手”:
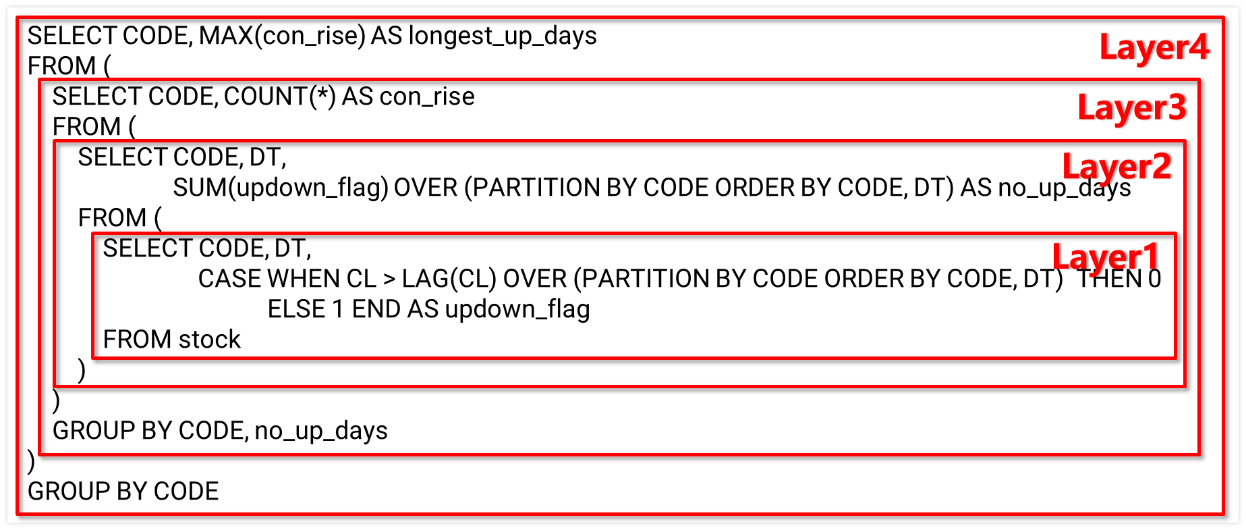
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT,
SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE;
子查询套子查询,窗口函数加条件判断,光是读懂这段代码就得靠毅力。要是需求改一下?对不起,可能得推倒重来。用 SQL 做复杂分析,感觉不是在写代码,而是参加嵌套结构奥赛。
调试起来不抓狂,每天多睡两小时
SPL:调试工具全家桶,交互分析爽到爆
调试 SQL 的时候,你是否有过这样的经历:写了个大查询,不知道哪里出错,只能把语句一块块拆开跑,拆一次改一次,简直是大型灾难片现场。SPL 怎么解决这个问题?它为数据分析师提供了一整套调试工具:
设置断点:代码执行到关键点时暂停,随时查看局部结果。
单步执行:一步步跑代码,观察中间值,排查问题一目了然。
实时查看:每一行的计算结果直接展示在右侧结果面板,再也不用猜结果对不对。
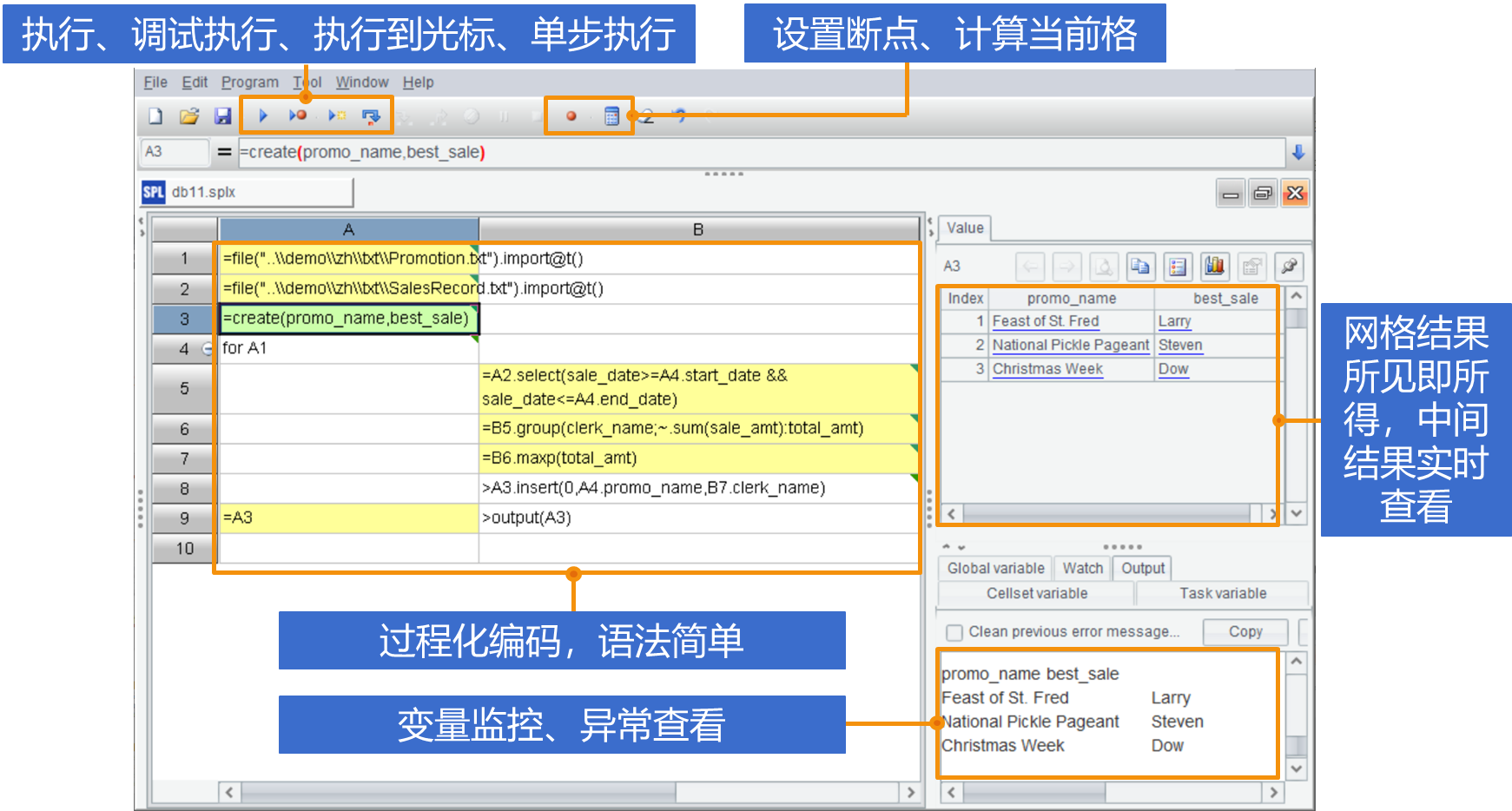
调试体验就像玩游戏开了无限金币,爽到爆!你不用再为错误结果费尽心思拆分代码,随时随地掌握全局。
有了这些丰富的调试功能,尤其是右侧所见即所得的结果面板,SPL 极大增强了数据分析的交互性。每写一步代码,都能直接看到计算结果,修改参数、调整逻辑立刻生效。分析师不再需要一口气写完大段代码后忐忑运行,而是可以像搭积木一样一步步构建分析流程,随时验证假设。
比如在股票分析中计算股票连涨区间时,SPL 就可以一步步随看随写,有新想法修改后立刻就能看到结果,交互性妥妥的。

SQL:调试功能等于“没有”
再看 SQL 的调试体验,真的令人无语。SQL 调试不支持断点,单步执行更是天方夜谭。想要调试?对不起,你得把代码一层层拆开,分段执行,每次修改都得重新运行。数据分析师的时间就这样被“硬着头皮”的调试过程白白浪费。
例如,上面那段计算股票涨幅的 SQL,如果运行结果不对,调试需要:
单独运行最内层子查询,看有没有错;
修改后再加一层跑,确保逻辑没崩;
最后检查顶层查询,可能要反复改写;
这样的工作模式,简直让人怀疑人生。
复杂分析也从容,SPL 才是数据分析的理想工具
前面计算股票连涨区间的例子用 SQL 很难写,这里直接用 SPL 来做,感受一下复杂度:
A |
|
1 |
=T("StockRecords.xlsx") |
2 |
=A1. sort(CODE,DT) |
3 |
=A2.group@i(CODE!=CODE[-1] || CL<CL[-1]) |
4 |
=A3.select(~.len()>5) |
5 |
=A4.conj() |
读入数据排序后,在 A3 中借助 SPL 对集合与有序计算的支持进行分组,将连涨的同一支股票记录分到一组,然后筛选大于 5 个成员的分组即可。整个过程很简单,符合自然思维。
还有更复杂的需求,比如电商业务中经常要计算流失率的漏斗分析,SPL 的代码仍然自然又直观:
A |
|
1 |
=["etype1","etype2","etype3"] |
2 |
=file("event.ctx").open() |
3 |
=A2.cursor(id,etime,etype;etime>=end_date-14 && etime<end_date && A1.contain(etype) ) |
4 |
=A3.group(uid) |
5 |
=A4.(~.sort(etime)).new(~.select@1(etype==A1(1)):first,~:all).select(first) |
6 |
=A5.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) |
7 |
=A6.groups(;count(~(1)):step1,count(~(2)):step2,count(~(3)):step3) |
一步步分解操作,每行代码都清晰对应分析步骤。无论是逻辑推导还是后续修改,都显得轻松无比。这段代码还能对付任意多步的漏斗,简单又通用。不仅如此,由于 SPL 对有序计算的有效支持,可以一次处理同一个用户数据,不需要 JOIN,跑得更快。
我们就费点劲把相应的 SQL 写出来看看,一堆 CTE 嵌套、无数条件组合,写到最后连自己都看不懂。
WITH e1 AS (
SELECT uid,1 AS step1, MIN(etime) AS t1
FROM events
WHERE etime>=end_date-14 AND etime<end_date AND etype='etype1'
GROUP BY uid),
e2 AS (
SELECT uid,1 AS step2, MIN(e1.t1) as t1, MIN(e2.etime) AS t2
FROM events AS e2 JOIN e1 ON e2.uid = e1.uid
WHERE e2.etime>=end_date-14 AND e2.etime<end_date AND e2.etime>t1 AND e2.etime<t1+7 AND etype='etype2'
GROUP BY uid),
e3 as (
SELECT uid,1 AS step3, MIN(e2.t1) as t1, MIN(e3.etime) AS t3
FROM events AS e3 JOIN e2 ON e3.uid = e2.uid
WHERE e3.etime>=end_date-14 AND e3.etime<end_date AND e3.etime>t2 AND e3.etime<t1+7 AND etype='etype3'
GROUP BY 1)
SELECT SUM(step1) AS step1, SUM(step2) AS step2, SUM(step3) AS step3
FROM e1 LEFT JOIN e2 ON e1.uid = e2.uid LEFT JOIN e3 ON e2.uid = e3.uid
SQL 不仅写得复杂,性能也更差。因为 SQL 缺乏离散性,不能用过程化语句写出复杂的跨行运算逻辑,就只能借助 JOIN 拼到一行来处理,即难又慢。。
SQL 的笨拙和低效,虽然广泛使用,但其实只是“看上去很美”。简单需求下显得方便,但一旦任务复杂,立刻暴露出“难写难调”的顽疾——这一点从各大论坛上充斥的“写不出 SQL”的求助帖子就能看出来。可以说,SQL 的这些缺点早已成为数据分析中挥之不去的痛点。
而 SPL 的出现,恰好解决了这些问题。
写法简单自然:再也不用面对复杂嵌套,SPL 的过程化语法让分析更轻松;调试功能强大:断点、单步、实时查看,每一步都清晰可靠,不再费时费力。
如果你已经厌倦了写 SQL 时的“挖坑填坑”,不如试试 SPL。它会让你从繁重的代码中解放出来,把更多时间花在分析业务上,而不是和代码死磕。


英文版