


求助: SPL 中动态列的选择
大佬们,周末好🙏
一直想求助 SPL 中如何动态选择列的问题,这里所指的动态包含模糊选择的意思。
对于行的选择,用 select 函数,此时可以结合函数 like,regex 或者 pos 等对字段值进行模糊查找,很方便。目前,SPL 中对于列的选择尚不能像选择行时一样直接,只能用枚举方式一一写出,此时要事先知道哪些字段名是需要参与计算的,比如:
1、file(btx,csv,txt,xlsx).import@t(字段 1, 字段 2…),或者,
2、ctx.open().cursor@( 字段 1, 字段 2…)
如果需要选出列名中具有某些共同特征的列,就要分几步:
1、导入表 A=file().import()
2、得到列名 B=A.fname()
3、选出有共同特征的列名连接成字符串 C=B.select(like/regex).concat@c()
4、执行宏,选出需要的列 D=A.new(${C})
同样的,如果要删除一些不需要的列,要么枚举写出:表.alter(; 字段 1, 字段 2…),要么用执行宏的方式来做。
所以,我想着可不可以有一种方法,在导入数据源时就能实现动态选择列,特别是在模糊选择的时候,在源头搞定,避免全表读入后再去选出。比如以下 columns() 方法:
1、file(btx,csv,txt,xlsx).import/cursor(columns( 正则表达式))
2、ctx.open().cursor(columns( 正则表达式))
3、序表.alter(;columns( 正则表达式))
4、序表.new(columns( 正则表达式))
像这样动态选择列的方法,市面上我了解到几乎很少,像微软系的 PowerQuery,Dax,或者数据库 MySQL,PostgreSQL,sqLite 等都没有这样的功能,但也有支持动态列选择的,目前了解到的有 3 个:
1、pandas 里在选择列 axis=1 的时候可以用正则表达式,
pandas.dataframe.filter(regex=‘e$’, axis=1) 选择以 e 结尾的列
pandas.dataframe.filter(regex=‘e’, axis=1) 选择包含字母 e 的列
pandas.dataframe.filter(like=‘e’, axis=1) 选择包含字母 e 的列
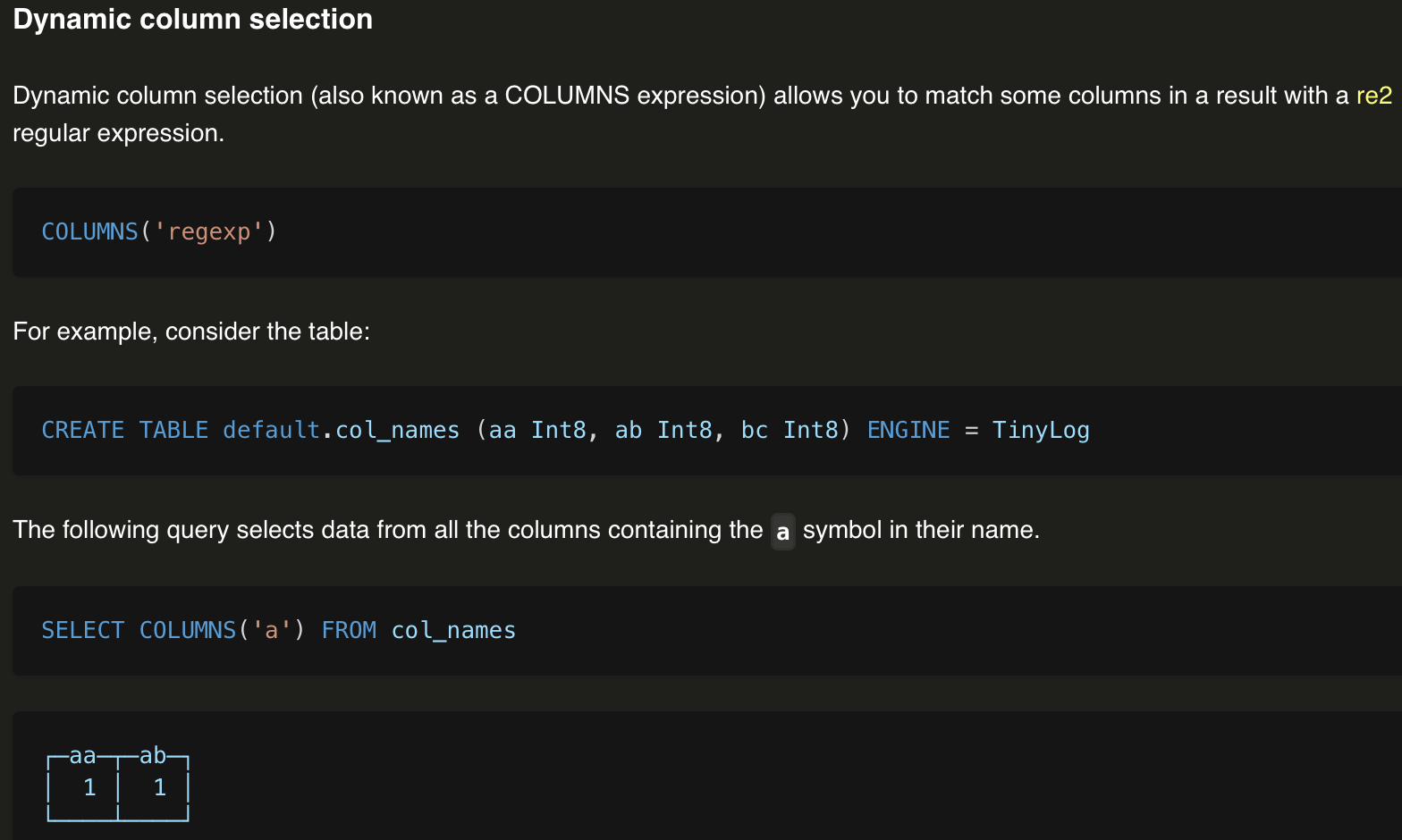
2、数据库 ClickHouse 在 select 语句中支持 COLUMNS(正则表达式) 实现动态列的选择:
https://clickhouse.com/docs/en/sql-reference/statements/select#columns-expression
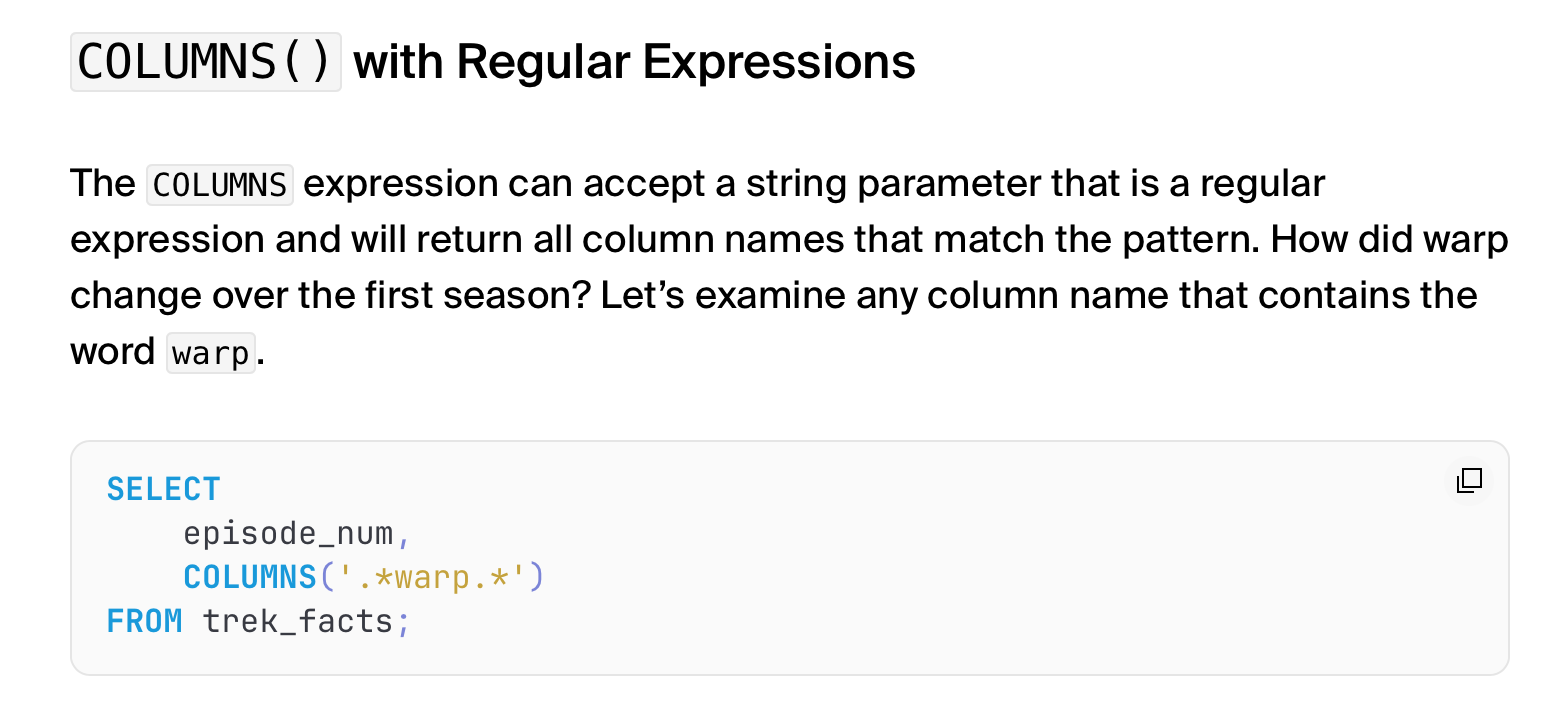
3、数据库 DuckDB 模仿了 ClickHouse 的 COLUMNS
https://duckdb.org/2023/08/23/even-friendlier-sql.html
我倒不是说别人家有的咱 SPL 就必须得有,确实是有时候在书写的过程中碰到要选出或者删除某些共同特征的列时会被卡一下,此处不是效率上的卡,是指书写节奏被卡了一下。比如以下例子中 4 个表的 join,关联后,用 derive@x() 展开,其中的关联字段 "编号" 会重复出现,现在要删除不需要的编号列,因为列有点多,不想枚举式写出,只好执行宏:
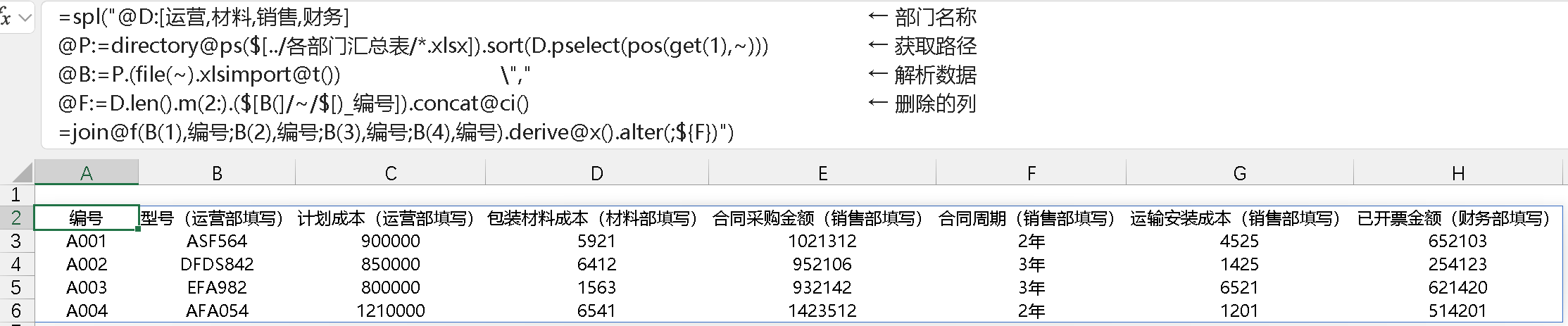
此时,如果支持对列的模糊选择,就会简洁不少,比如:
join().derive@x ().alter(;columns(‘_’))
这样就把带有下划线的列都删除了。
还是那句话,不是别人有的 SPL 就一定得有,SPL 是我目前接触过的最好用,能把简洁和高效两字一起形容的编程语言,作为狂热铁粉,心愿也很朴实,自然是希望 SPL 越来越牛,遥遥领先。
恳请大佬们得闲时帮忙看看,莫怪我多事,哈哈😄 🙏
Till good is better, but better best!


这个事没有那么简单,SPL 是语法一致的语言。import 函数并不比其它函数特殊,所有函数要采用同样一套参数语法规则。
SQL 可以随意特殊处理某个关键字并不会影响其它,而且即使这样,也存在考虑不周的(比如各种混用,以及返回次序问题)。
这个功能当然有些意义,但目前的参数体系并不容易把它塞进去。这东西也不是多常用,目前顾不上仔细想合适的方法,就先搁置起来。
谢谢老贼回复🙏
是我想简单了,我只想着图方便,没想到这是牵一发动全身的操作,昨晚做梦还想到了 group(columns()) 为啥不行,潜意识中感觉到这是个大工程,哈哈,魔怔了😄 目前用 ${} 宏的方法不能说不方便,我个人的使用感觉是,涉及到宏的操作经常会卡节奏,写着写着要倒回去另起一步拼字符串,没那么自由。
还是很眼馋这个动态列的😂 ,如果有可能,恳请 SPL 大佬们考虑把这个请求作为 first thing in the future.🙏 😄
感谢!