


易明建模实践:用历史数据做商业预测
明确目标,准备数据
首先要明确目标,知道要预测什么东西。
比如银行放贷款时,希望预测出贷款人违约的可能性,从而判定是否放贷以及贷款利率。
保险公司制定保费时,希望预测出客户的理赔风险,从而制定更灵活的保费政策。
商业营销中,希望预测出哪些用户会购买哪些产品,从而更精准的进行销售活动,等等。
只要我们手头有足够的历史数据,那么这些任务都是可以做的。
以贷款违约预测为例。历史数据可以采集近期贷款数据。例如想预测 7 月份用户的违约情况,可以采集 1-6 月份的数据来建立模型,也可以是近 1 年或者近 3 个月等等。这些由根据业务特征决定
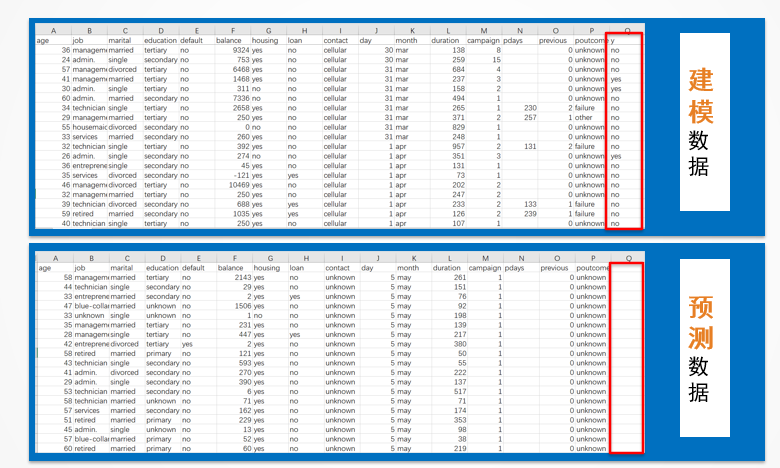
采集到的历史数据要整理成这样的一张表格,俗称宽表。
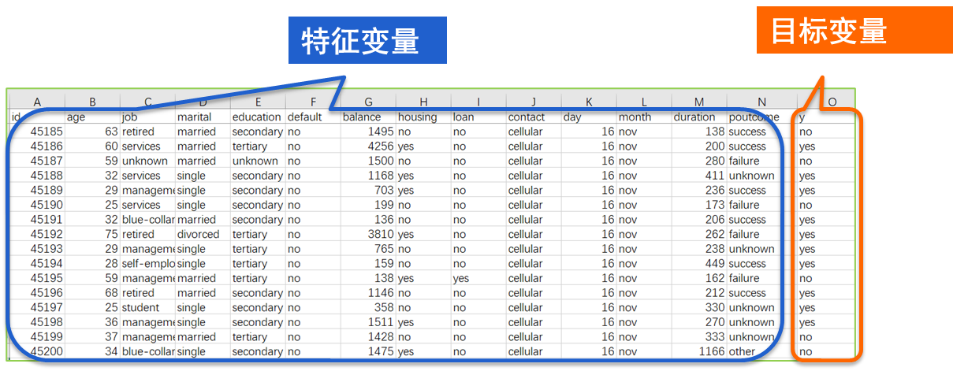
宽表中要包含特征变量和目标变量。
目标变量就是要预测的目标,比如图中的 y 变量,表示每笔贷款的违约情况。yes 违约,no 不违约。
特征变量是和预测目标可能相关的一些信息。
比如这个例子中,特征变量包括贷款人的收入水平、负债情况,贷款金额、期限、利率以及贷款人的工作职位、居住条件等等。
这种目标变量只有 yes 和 no 的问题,叫做二分类问题。这是一种很常见的预测类型。比如预测客户是否会购买某产品,平台用户是否会流失,电子邮件是否垃圾邮件等,都是二分类问题。
除此之外易明建模还可以做回归问题和多分类问题。
回归问题,目标变量是一个数值,比如预测产品的销量、售价……,。
而多分类问题一般是预测属于什么种类,比如预测产品等级是优、良、合格还是差。
宽表整理好后,可以保存成 Excel 格式,或是 csv,txt 都可以。
导入数据,一键建模
整理好的宽表就可以用来建模了。
点击“新建模型”,选择准备好的宽表,导入到易明建模。
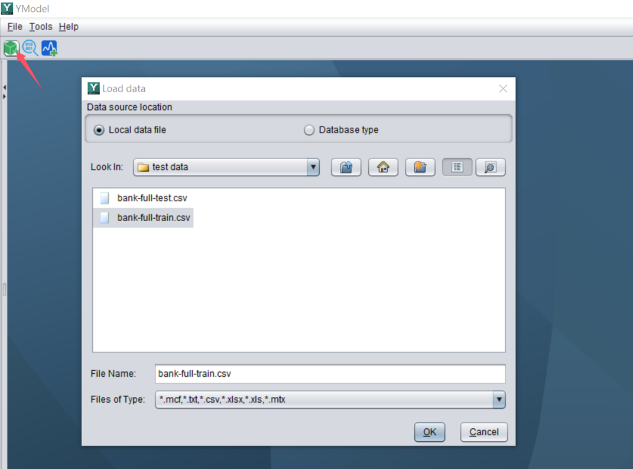
导入数据后软件会提示配置目标变量。
比如该数据中的目标变量为 y,表示用户是否违约。
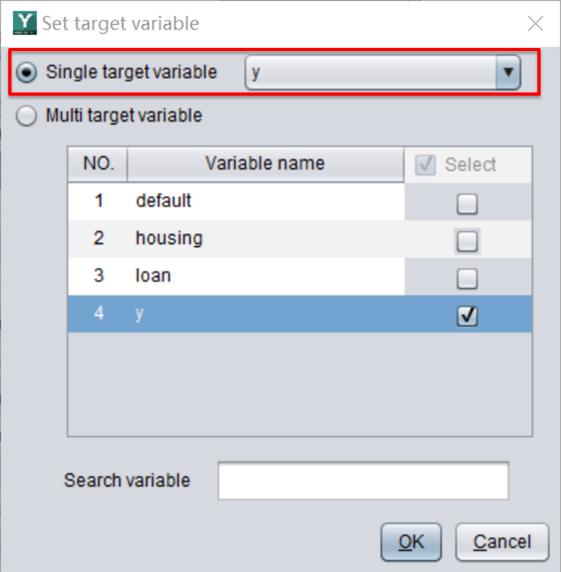
易明建模还会自动识别这些特征变量的数据类型,并绘制出分析图。
比如本例中的 education 变量,表示贷款人的受教育水平。易明建模识别出它是个分类型变量,缺失率为 0。有 4 种分类值,其中 secondary 的取值最多,对应饼图中的蓝色部分,占比约 51%。
现在点击工具栏上”建模”按钮就可以了。整个数据预处理和建模过程都是自动进行的不需要人工操作。
建模过程中会显示进度条,如下图,表示数据预处理进行到 40%。
大概几分钟到几十分钟就能完成模型建立,有时会更短,看数据量。
模型建好后,可以看到该模型的算法和对应参数。软件同时会输出一个 pcf 后缀模型文件,该文件可以用来做预测。

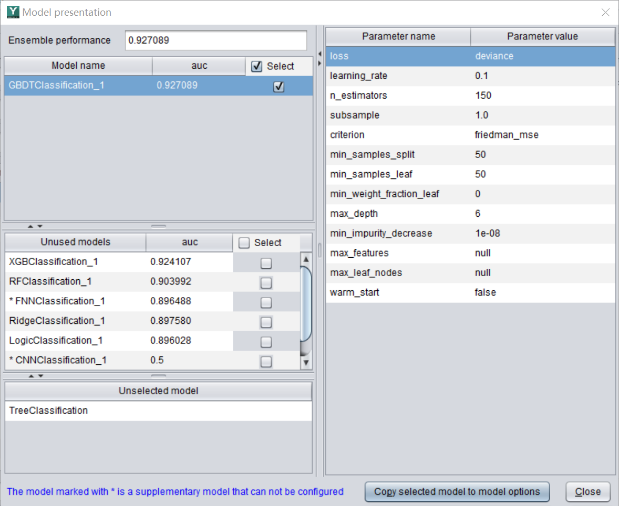
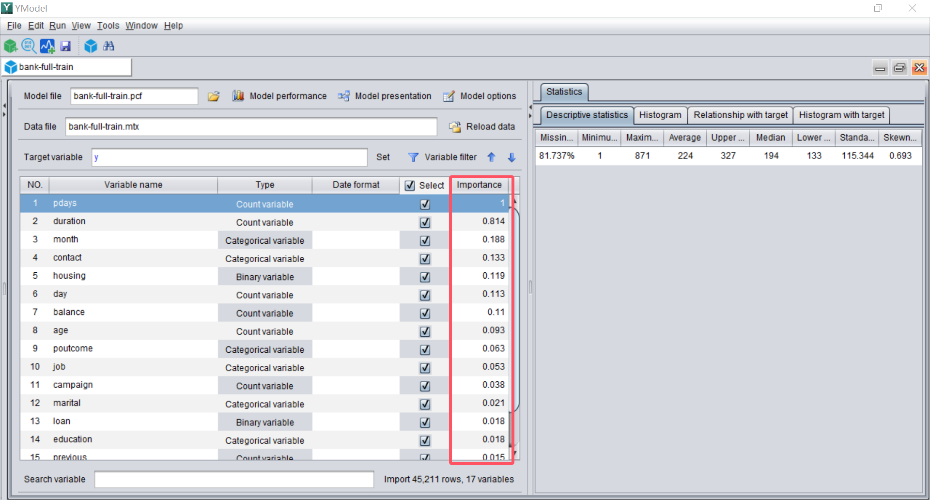
建模完成后,界面会返回每个变量的重要度。
重要度越大表示该变量越能影响预测目标。
使用该功能可以帮我们做一些业务分析,比如该数据中 pdays 变量对用户违约的影响较大。
评估模型,执行预测
模型建好后,点击“模型表现”,可以查看模型表现来评估模型。
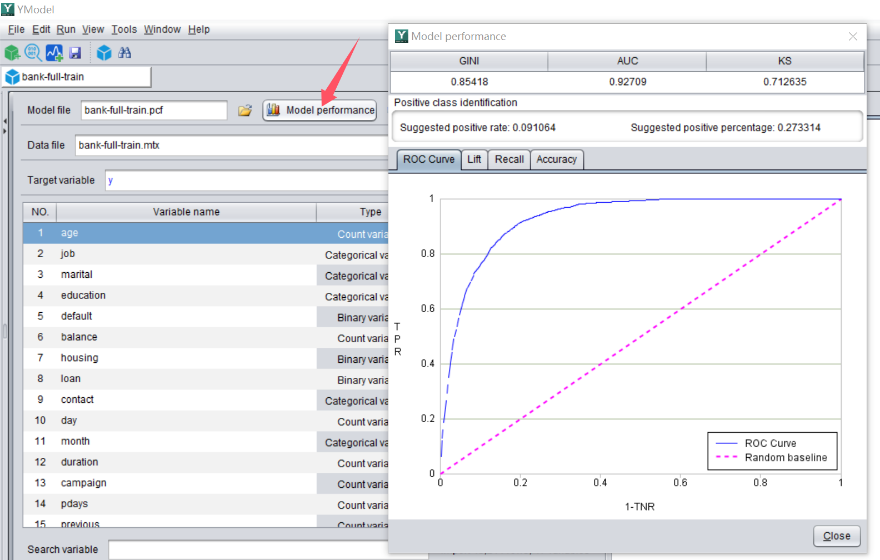
比如我们通常会看一个叫做 AUC 的指标。它的取值范围为(0.5-1),原则上越高越好。
本例中,这个模型的 AUC 是 0.927,是一个不错的模型,用这个模型去做预测,可信度很高。
模型评估合格后,就可以做预测了。
用来预测的数据也是一张宽表。预测数据中特征变量和建模用到的特征变量必须是一致的,只是不包含目标变量。
比如下图中的两张表,上面的表是建模数据,包含目标变量 y。
下面的表是预测数据,不包含目标变量 y,除此之外其他的变量名都是一样的。
打开预测界面,导入 pcf 模型文件,再导入要预测的数据集,就可以执行预测了。
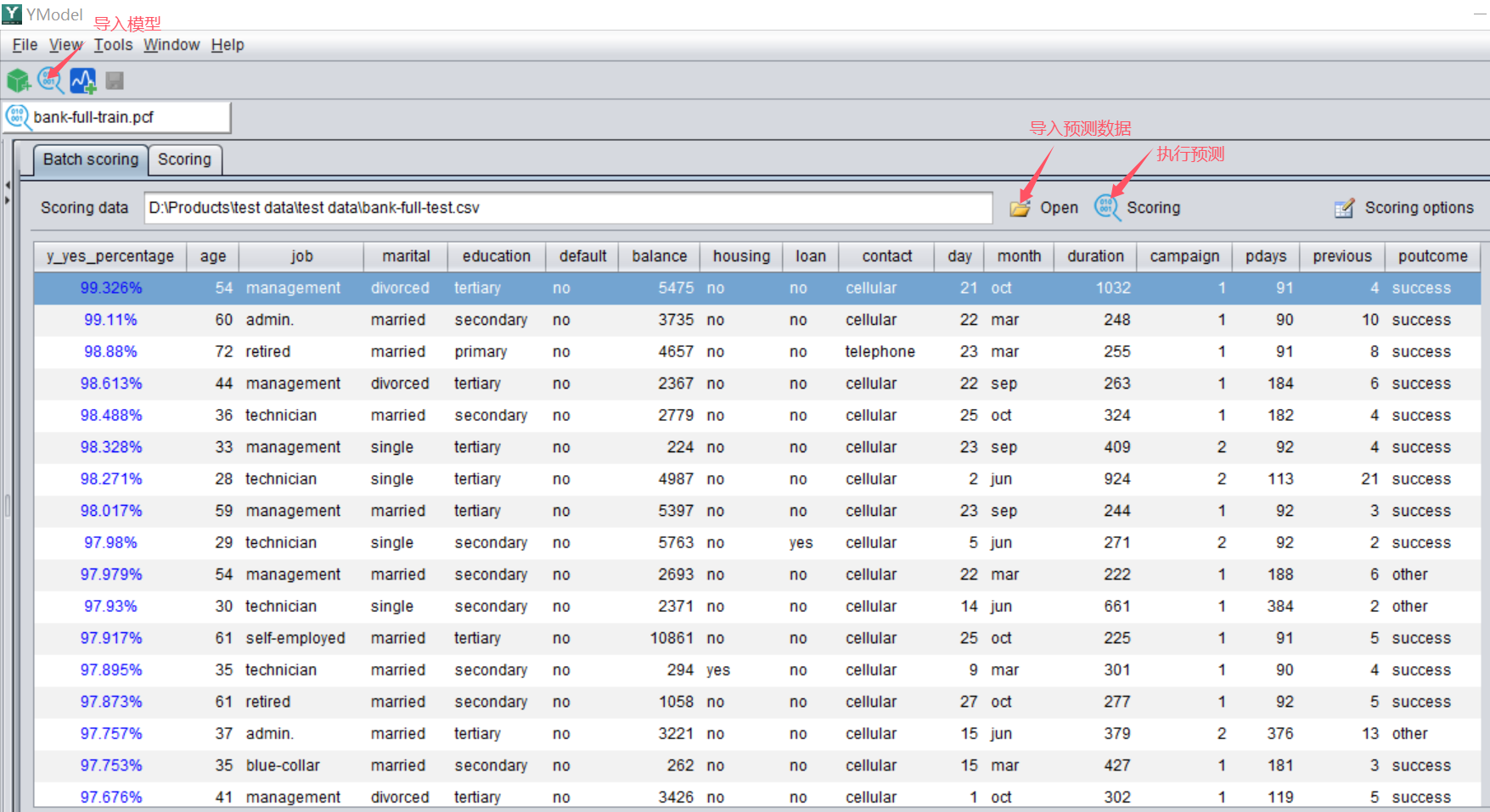
预测完成可得上图中的界面。最左侧的一列就是预测结果。在本例中百分数表示客户违约的概率,概率越大的客户违约的风险越高。
点击该列变量名,还可以对预测结果排序,筛选出高风险客户。
最后我们再来总结下使用历史数据做商业预测的流程。
1. 整理宽表。
将历史数据和待预测的数据都整理成宽表,历史数据中必须要有目标变量,待预测数据则没有。
2. 导入数据建模。
将历史数据导入到易明建模,建立模型,生成 pcf 后缀的模型文件
3. 用模型做预测。
打开 pcf 模型文件,导入待预测数据,执行预测。然后就可以根据预测出来的结果(比如违约概率)去决定商业行动了。


英文版