


8.1 外键关联
8.1.1 普通外键关联
销售记录表、城市信息表、产品信息表部分内容如下:
销售记录表 (事实表):
| recordid | product | product_city | sale_city | amount | … |
|---|---|---|---|---|---|
| sr100001 | p1006 | c105 | c103 | 603 | … |
| sr100002 | p1005 | c105 | c102 | 1230 | … |
| sr100003 | p1003 | c102 | c102 | 885 | … |
| … | … | … | … | … | … |
城市信息表(维表):
| cityid | name | state | … |
|---|---|---|---|
| c101 | New York | New York | … |
| c102 | Miami | Florida | … |
| c103 | Los Angeles | California | … |
| … | … | … | … |
产品信息表(维表):
| productid | pclass | … |
|---|---|---|
| p1001 | A | … |
| p1002 | A | … |
| p1003 | B | … |
| … | … | … |
请用以上数据完成以下计算:
1. 一事实表一维表——汇总各类产品的销售额
2. 一事实表多维表——统计各州各类产品的销售额
3. 维表复用
1) 找出产品销售地与产地在同一州的销售记录
2) 计算销售地在加利福尼亚州的销售额
3) 计算各州作为产地的总销售额
4. 多层维表——找出产品销售地与产地在同一州的销售记录
有时,产品的城市信息不在销售记录表上,而是在产品信息表上,这时的关联就是多层维表关联了。
修改后的销售记录表和产品信息表如下:
销售记录表 2:
| recordid | product | sale_city | amount | … |
|---|---|---|---|---|
| sr100001 | p1003 | c104 | 380 | … |
| sr100002 | p1005 | c103 | 400 | … |
| sr100003 | p1003 | c104 | 626 | … |
| … | … | … | … | … |
产品信息表 2:
| productid | product_city | … |
|---|---|---|
| p1001 | c104 | … |
| p1002 | c103 | … |
| p1003 | c102 | … |
| … | … | … |
SPL
| A | B | |
|---|---|---|
| 1 | =file(“SaleRecord.csv”).import@tc() | |
| 2 | =file(“Product.csv”).import@tc() | |
| 3 | =A1.switch(product,A2:productid) | /1. 一事实表一维表 |
| 4 | =A3.groups(product.pclass;sum(amount):amount) | /1. 一事实表一维表 |
| 5 | =file(“City.csv”).import@tc() | |
| 6 | =A1.switch(product,A2:productid;sale_city,A5:cityid) | /2. 一事实表多维表 |
| 7 | =A6.groups(sale_city.state,product.pclass;sum(amount):amount) | /2. 一事实表多维表 |
| 8 | =A1.switch(sale_city,A5:cityid;product_city,A5:cityid) | /3. 维表复用 |
| 9 | =A8.select(sale_city.state==product_city.state).(recordid) | /3. 维表复用 |
| 10 | =A8.select(sale_city.state==“California”).sum(amount) | / 销售地在加利福尼亚州的销售额 |
| 11 | =A8.groups(product_city.state;sum(amount):amount) | / 各州作为产地的总销售额 |
| 12 | =file(“SaleRecord2.csv”).import@tc() | |
| 13 | =file(“Product2.csv”).import@tc() | |
| 14 | =A13.switch(product_city,A5:cityid) | /4. 多层维表 |
| 15 | =A12.switch(sale_city,A5:cityid;product,A14:productid) | /4. 多层维表 |
| 16 | =A15.select(sale_city.state==product.product_city.state).(recordid) | /4. 多层维表 |
switch() 方法把外键字段转换成对应的维表记录,它只是引用维表记录,并不复制数据,而且可以同时解析多个关联关系并且复用关联关系。
注意:上述 4 个任务是相互独立,虽然代码写在一起,但执行的时候要把另外三个任务的代码注释掉再执行,否则已经 switch()后的字段不能再 switch() 了。
A3 结果如下:
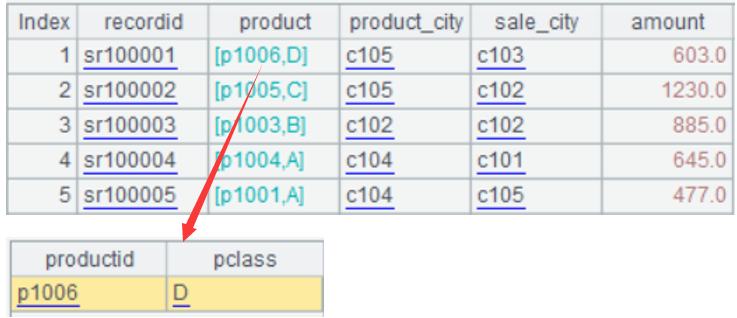
还要特别指出的是,SPL 的关联关系是直接引用到关联记录,这可以在加载数据时一次性把所有的关联关系建好,用指针方式保存关联结果,方便后续利用这种关联关系进行计算,这就是常说的预关联。比如 A8 是预关联好的数据,后续的 A9、A10、A11 直接拿来用就行了。
SQL
1. 一事实表一维表——汇总各类产品的销售额
SELECT p.pclass AS pclass, SUM(s.amount) AS amount
FROM SaleRecord s
JOIN product p ON s.product = p.productid
GROUP BY p.pclass;
2. 一事实表多维表——统计各州各类产品的销售额
SELECT c.state AS state, p.pclass AS pclass, SUM(s.amount) AS amount
FROM SaleRecord s
JOIN City c ON s.sale_city = c.cityid
JOIN Product p ON s.product = p.productid
GROUP BY c.state, p.pclass;
3. 维表复用 1——找出产品销售地与产地在同一州的销售记录
SELECT s.recordid
FROM SaleRecord s
JOIN City c1 ON s.product_city = c1.cityid
JOIN City c2 ON s.sale_city = c2.cityid
JOIN Product p ON s.product = p.productid
WHERE c1.state = c2.state;
4. 维表复用 2——计算销售地在加利福尼亚州的销售额
SELECT SUM(amount) AS amount
FROM SaleRecord s
JOIN City c ON s.sale_city=c.cityid
WHERE c.state = 'California';
5. 维表复用 3——计算各州作为产地的总销售额
SELECT c.state AS state, SUM(s.amount) AS amount
FROM SaleRecord s
JOIN City c ON s.product_city = c.cityid
GROUP BY c.state;
6. 多层维表——找出产品销售地与产地在同一州的销售记录
SELECT s.recordid
FROM SaleRecord2 s
JOIN Product2 p ON s.product = p.productid
JOIN city c ON s.sale_city=c.cityid
JOIN city c2 ON p.product_city=c2.cityid
WHERE c.state=c2.state
ORDER BY s.recordid;
Python
record1=pd.read_csv("../SaleRecord.csv")
product1=pd.read_csv("../Product.csv")
r_pt=pd.merge(record1,product1,left_on="product",right_on="productid") #1.一事实表一维表
pclass_sale=r_pt.groupby('pclass',as_index=False).amount.sum()
ct1=pd.read_csv("../City.csv")
r_ct=pd.merge(record1,ct1,left_on="sale_city",right_on="cityid") #2.一事实表多维表
r_ct_pdt=pd.merge(r_ct,product1,left_on="product",right_on="productid") #2.一事实表多维表
ct_pdt_sale=r_ct_pdt.groupby(['state','pclass'],as_index=False).amount.sum()
r_ct2=pd.merge(record1,ct1,left_on="sale_city",right_on="cityid") #3.维表复用
r_ct_ct=pd.merge(r_ct2,ct1,left_on="product_city",right_on="cityid",suffixes=('_s', '_p')) #3.维表复用
r_ct_p_ct= r_ct_ct[r_ct_ct['state_s']==r_ct_ct['state_p']].recordid.values.tolist()
#销售地在加利福尼亚州的销售额
hlj_sale_amount=r_ct_ct[r_ct_ct['state_s']=="California"].amount.sum()
#各州作为产地的总销售额
state_product_amount=r_ct_ct.groupby(['state_p']).amount.sum()
record2=pd.read_csv("../SaleRecord2.csv")
product2=pd.read_csv("../Product2.csv")
pdt_ct=pd.merge(product2,ct1,left_on="product_city",right_on="cityid")
r_pdt_ct=pd.merge(record2,pdt_ct,left_on="product",right_on="productid") #4.多层维表
r_pdt_ct_ct=pd.merge(r_pdt_ct,ct1,left_on="sale_city",right_on="cityid",suffixes=('_s', '_p')) #4.多层维表
r_ct_p_ct2=r_pdt_ct_ct[r_pdt_ct_ct['state_s']==r_pdt_ct_ct['state_p']].recordid.values.tolist()
Python 关联后形成一张宽表,完全复制两表的数据,比如 r_pt 结果如下;
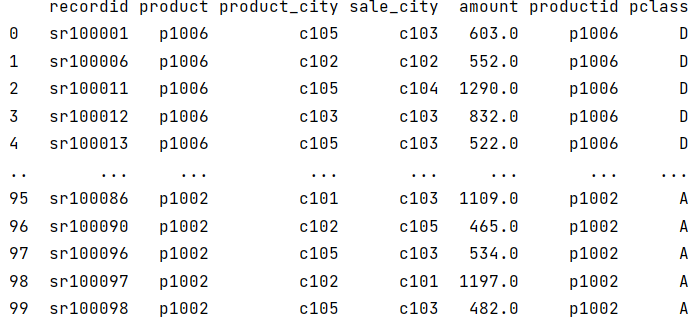
Python 的关联关系建好也可以认为是预关联,比如维表复用时的 r_ct_ct 就可以看作预关联结果,只不过 Python 是建立了一张大宽表,把所有的关联字段都放到了这张表里。
8.1.2 循环关联
员工信息表和部门信息表如下:
员工信息表:
| empid | name | dept | state | partner | … |
|---|---|---|---|---|---|
| 1 | FORD | 6 | New York | 12 | … |
| 2 | SCOTT | 2 | Florida | 12 | … |
| 3 | JAMES | 7 | California | 11 | … |
| … | … | … | … | … | … |
部门信息表:
| deptid | name | manager | … |
|---|---|---|---|
| 1 | Administration | 20 | … |
| 2 | Finance | 2 | … |
| 3 | HR | 162 | … |
| … | … | … | … |
根据以上数据完成下述计算:
1. 自关联——列出所有员工及其合作者的姓名
2. 环状关联——找出佛罗里达州经理的佛罗里达州员工
SPL
| A | B | |
|---|---|---|
| 1 | =file(“Employee_1.csv”).import@tc() | |
| 2 | =A1.switch(partner,A1:empid) | /1. 自关联 |
| 3 | =A2.new(name,partner.name:name_p) | |
| 4 | =file(“Department2.csv”).import@tc() | |
| 5 | =A4.switch(manager,A1:empid) | |
| 6 | =A1.switch(dept,A5:deptid) | /2. 环状关联 |
| 7 | =A6.select(state==“Florida”&&dept.manager.state==“Florida”).(name) | /2. 环状关联 |
SQL
1. 自关联——列出所有员工及其合作者的姓名
SELECT e.name AS name, p.name AS partner
FROM Employee_1 e
LEFT JOIN Employee_1 p ON e.partner = p.empid;
2. 环状关联——找出佛罗里达州经理的佛罗里达州员工
SELECT e.name AS employee_name
FROM Employee_1 e
JOIN Department2 d ON e.dept = d.deptid
JOIN Employee_1 m ON d.manager = m.empid
WHERE e.state = 'Florida' AND m.state = 'Florida';
Python
emp=pd.read_csv("../Employee_1.csv")
emp_s=pd.merge(emp,emp,left_on="partner",right_on="empid",suffixes=('', '_p'),how="left")
#1.自关联
emp_s_name=emp_s[['name','name_p']]
dept2=pd.read_csv("../Department2.csv")
d_emp=pd.merge(dept2,emp,left_on="manager",right_on="empid")
#2.环状关联
emp_d_emp=pd.merge(emp,d_emp,left_on="dept",right_on="deptid",suffixes=('', '_m'))
#2.环状关联
Florida_emp_m=emp_d_emp[(emp_d_emp['state']=="Florida") & (emp_d_emp['state_m']=="Florida")].name.tolist()

