


比 SQL 快出数量级的大数据计算技术
SQL 经常跑得很慢
SQL 是最常用的大数据计算语言,但是,SQL 经常跑得很慢,严重浪费硬件资源。
某银行的反洗钱准备计算,36 亿行,11 节点的 Vertica 集群跑了 1.5 小时。
某电商漏斗运算,3 亿行,Snow Flake 的 Medium 型 4 节点集群超过 3 分钟没算出来。
某时空碰撞任务,250 亿行,Click House 5 节点集群跑了 1800 秒。
这些案例的数据量不算很大,小的只有几 GB,大的也就几百 GB,表现出来的性能却不如人意。
是不是这些任务过于复杂,就只能这么慢呢?并不是,这些任务用 SPL 改写后,性能都有大幅改观。
反洗钱准备计算,SPL 单机只要 26 秒,快了 208 倍,竟然把跑批任务跑成了实时查询!
漏斗运算,SPL 单机 10 秒完成。
时空碰撞任务,SPL 单机只要 350 秒,快了 5 倍。
换用 SPL 后,不仅计算性能快出了数量级,而且硬件还更少了,集群变单机。事实上,连代码也更短了。
为什么 SQL 就跑不出这个性能呢?
由 TOP N 问题探究 SQL 慢的原因
SQL 会跑这么慢,是因为写不出低复杂度的算法。
举个例子,从一亿条数据中取前十名。SQL 写出来有个 order by 字样:
SELECT TOP 10 * FROM Orders ORDER BY Amount DESC
这意味着要排序。如果真做一亿条记录的大排序,那计算量就大了去了。
其实,只要保持一个十条记录的小集合,遍历一亿条数据的时候不断比较、替换小集合中的记录,就可以得到前十名了,计算量比大排序小了 8 倍!遗憾的是,SQL 没有显式的集合数据类型,无法描述这样的计算过程,只能写成 order by,然后指望数据库去优化。还好,几乎所有数据库都会优化,采用更高效的算法,不会傻到真去做大排序。
但是,情况稍复杂些呢?比如我们把需求改成计算分组内的前 10 名,SQL 写出来是这样的。
SELECT * FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rn
FROM Orders )
WHERE rn<=10
这和前面全量数据取前 10 名的写法相差很大,要借助窗口函数造个组内序号,再用子查询过滤出符合条件的记录,有点“绕”了。
无论如何,SQL 中还是有 ORDER BY,运算逻辑还是排序。实测发现,同样的数据量,Oracle 计算组内前 10 名比全集前 10 名慢出几十倍,按说多个分组应该只慢一点点才对。Oracle 很可能做了排序,甚至是外存排序。
数据库优化引擎面对稍复杂的情况就晕了,只能老老实实按 SQL 的逻辑去执行,常常是个高复杂度的运算逻辑,所以性能就会非常差。
当然,也许哪天数据库又进化了,碰到这种情况也会优化了。但总有更复杂的情况,而数据库优化引擎的进化速度是很慢的。
更复杂的对象事件问题
用 TOP N 来举例,是因为它比较简单易于理解,事实上在现实中并不经常要做这种运算。而且,对于 TOP N 这样的简单问题,即使复杂化到分组 TOP N 的情况,SQL 优化器经过一些改良,也还是能对付的。
但实际情况中的计算常常要远比 TOP N 复杂,前面提到的案例,业务需求都有一定的复杂性,数据量不算大但计算量大。SQL 写不出好算法,只能依靠数据库的优化引擎,而优化引擎却常常靠不住。
比如典型的对象事件问题。这里的对象可以是电商系统用户、银行账号、游戏玩家、手机、车辆等等,通常会有个唯一的 ID,对象涉及的事件都记录在这个 ID 下,例如电商系统操作事件、银行账号的交易记录、手机的通话记录、用户的操作日志等。
对象事件问题的实际计算任务也很多,比如电商系统指定操作步骤的用户流失率,银行账号的交易额超过 1 万元的交易次数、节假日发生的交易额,计算每张信用卡是否连续三天都有超过 1000 元的交易,游戏用户购买某类装备的金额,新注册的游戏用户下次登录时刻的间隔天数,手机通话时间不超过 3 秒的次数,…。
这类问题非常普遍,可以说占了数据分析业务中一半以上的场景。这都是有业务意义的数据分析了,其中有相当一部分会涉及有序运算,用 SQL 都会非常难写,不仅代码繁琐,而且运算效率低下。
下面通过电商漏斗分析这个典型的事件对象问题,继续探究 SQL 慢的原因。
对象事件问题的任务
对象事件问题的任务是针对每个 ID 中符合一定条件的事件,计算出某种聚合值,然后再做 ID 的整体统计。
具体到漏斗分析,就是找出每个用户在一个较短的时间范围,按照次序完成一个给定步骤序列的最多步数。
比如给定三个步骤:浏览商品、查看详情、确认下单,要计算的聚合值是:每个用户在 3 天内按次序最多完成这三个步骤中的几步。有了每一个用户的最多步数,只要简单计数,就可以整体统计出,走到每个步骤的用户数量,进而分析哪一步的用户流失率最严重了。
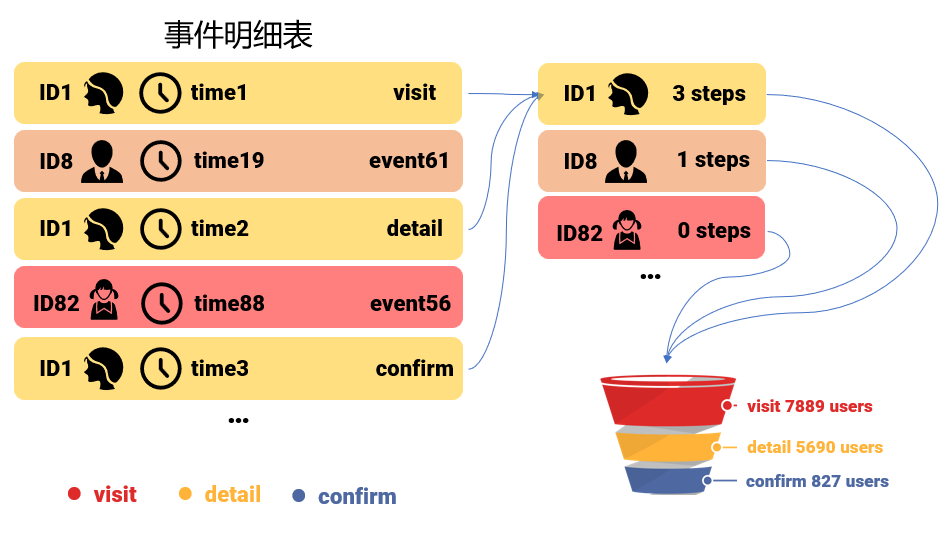
对象事件计算的特征
要弄清楚 SQL 解决这个问题的难点,先看对象事件计算的几个特征:
一,ID 数量非常多,几千万到几十亿;
二,同一 ID 的事件数并不多,几条到几千条;
三,针对事件的计算复杂,步骤多;
四,计算时 ID 之间无关。
SQL 实现对象事件问题导致大表 JOIN
对象事件之间的复杂关联计算会涉及多条互相依赖的事件记录。
SQL 对跨行运算的支持很弱,要用 JOIN 把多行记录拼到一行中才能进一步运算。而且,参与运算的事件都有条件,一般要先用子查询选出来再 JOIN。计算中涉及的事件越多,参与 JOIN 的子查询越多。
比如下图中的三步漏斗,就涉及 ID1 的多条记录,先用多个子查询筛选合适的事件记录,把多行记录 JOIN 到一行中,才能做进一步运算。
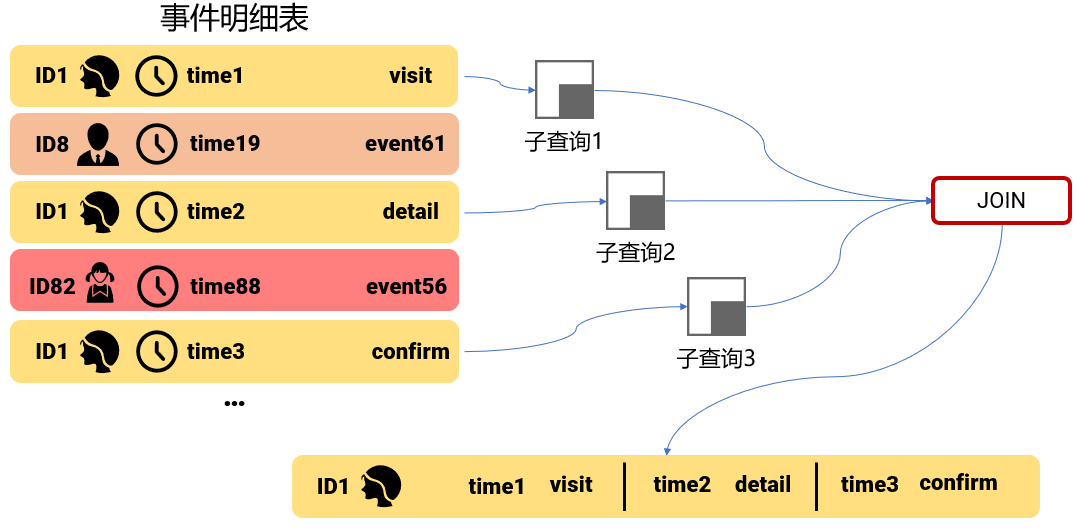
这些子查询还会有依赖性,比如第 2 步事件要在第一步事件的基础上寻找,子查询本身也要用 JOIN 计算。
这些子查询都会基于巨大的事件表,大表 JOIN 本来就很难做,这里还要反复多次 JOIN,跑得慢就不奇怪了,跑崩也很正常。
SQL 实现对象事件问题涉及大结果集 GROUP BY
用 SQL 计算最后聚合值时,又会涉及大结果集的 GROUP BY。
因为期望的结果中,每个 ID 对应一套聚合值,JOIN 的结果并没有这个特征,同一个 ID 可能会 JOIN 出很多条记录。这时候,还要针对 ID 再做一次 GROUP BY。ID 数量非常多,这种大结果集的分组性能非常差,并行计算效果也不好。
有时,计算目标是对 ID 计数,GROUP BY 会退化成 COUNT DISTINCT,但复杂度数量级并没有变。
SQL 实现对象事件问题的脚本
这是一个 SQL 写的三步漏斗分析,其中有多个和 ID 相关的大表 JOIN、GROUP BY 以及 COUNT DISTINCT。
WITH e1 AS (
SELECT userid, visittime AS step1_time, MIN(sessionid) AS sessionid, 1 AS step1
FROM events e1 JOIN eventgroup ON eventgroup.id = e1.eventgroup
WHERE visittime >= DATE_ADD(arg_date,INTERVAL -14 day) AND visittime < arg_date AND eventgroup.name = 'SiteVisit'
GROUP BY userid,visittime
), e2 AS (
SELECT e2.userid, MIN(e2.sessionid) AS sessionid, 1 AS step2, MIN(visittime) AS step2_time, MIN(e1.step1_time) AS step1_time
FROM events e2 JOIN e1 ON e1.sessionid = e2.sessionid AND visittime > step1_time JOIN eventgroup ON eventgroup.id = e2.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND eventgroup.name = 'ProductDetailPage'
GROUP BY e2.userid
), e3 AS (
SELECT e3.userid, MIN(e3.sessionid) AS sessionid, 1 AS step3, MIN(visittime) AS step3_time, MIN(e2.step1_time) AS step1_time
FROM events e3 JOIN e2 ON e2.sessionid = e3.sessionid AND visittime > step2_time JOIN eventgroup ON eventgroup.id = e3.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND (eventgroup.name = 'OrderConfirmationType1')
GROUP BY e3.userid
)
SELECT s.devicetype AS devicetype,
COUNT(DISTINCT CASE WHEN fc.step1 IS NOT NULL THEN fc.step1_userid ELSE NULL END) AS step1_count,
COUNT(DISTINCT CASE WHEN fc.step2 IS NOT NULL THEN fc.step2_userid ELSE NULL END) AS step2_count,
COUNT(DISTINCT CASE WHEN fc.step3 IS NOT NULL THEN fc.step3_userid ELSE NULL END) AS step3_count,
FROM (
SELECT e1.step1_time AS step1_time, e1.userid AS userid, e1.userid AS step1_userid, e2.userid AS step2_userid,e3.userid AS step3_userid,
e1.sessionid AS step1_sessionid, step1, step2, step3
FROM e1 LEFT JOIN e2 ON e1.userid=e2.userid LEFT JOIN e3 ON e2.userid=e3.userid ) fc
LEFT JOIN sessions s ON fc.step1_sessionid = s.id
GROUP BY s.devicetype
解决对象事件问题的正确思路
其实,只要利用前面说的特征,解决对象事件问题并不难。
我们可以把事件按 ID 排序,每个 ID 的事件不多,每次把一个 ID 的所有事件读入内存。在内存中,使用过程化的语言实现这种复杂计算就很容易了。
因为 ID 之间无关,所以内存关联运算仅在一个 ID 的事件范围内进行,不会有大表 JOIN。每次都会完成一个 ID 聚合值的计算,后续不需要 GROUP BY ID,COUNT DISTINCT 也会变成简单的 COUNT。这个算法不仅计算量少,而且占用内存小,很容易并行。
可惜,用 SQL 无法实现这样的高效算法。这主要是因为 SQL 缺乏离散性,无法实现过程化的复杂跨行运算,只能借助 JOIN。而且,SQL 的集合无序,即使刻意有序存储也无法利用。
SPL 如何计算 Top N
SQL 没有显式的集合数据类型,无法描述前面说的那种低复杂度的算法,只能指望数据库去优化。而 SPL 则可以从算法层面解决这些问题。
SPL 把 Top N 理解为,与 SUM、MAX 一样的聚合运算,只不过返回值是一个集合而已。这样就相当于实现了前面提到的高效算法,代码写出来是这样的:
Orders.groups(;top(10;-Amount))
Orders.groups(Area;top(10;-Amount))
这个语句中没有 order by 字样,也就不会做大排序,而采用小集合的算法了。而且,这里分组前 10 名和全集前 10 名的写法基本一样,只是多了分组键。
SPL 解决对象事件问题
再看对象事件问题,用 SPL 就很容易实现前面说的高效算法。
SPL 的集合有序,能够刻意保证存储的次序,且提供有序游标,可以一次读入一个 ID 的事件数据。SPL 语法中强化了离散性,可以很方便按自然思维写出多步骤跨行运算的代码。
这是 SPL 实现同样漏斗分析的代码:
A |
|
1 |
=eventgroup=file("eventgroup.btx").import@b() |
2 |
=st=long(elapse(arg_date,-14)),et=long(arg_date),eet=long(arg_date+1) |
3 |
=A1.(case(NAME,"SiteVisit":1,"ProductDetailPage":2,"OrderConfirmationType1":3;null)) |
4 |
=file("events.ctx").open() |
5 |
=A4.cursor@m(USERID,SESSIONID,VISITTIME,EVENTGROUP;VISITTIME>=st && VISITTIME<eet,EVENTGROUP:A3:#) |
6 |
=file("sessions.ctx").open().cursor@m(USERID,ID,DEVICETYPE;;A5) |
7 |
=A5.joinx@m(USERID:SESSIONID,A6:USERID:ID,DEVICETYPE) |
8 |
=A7.group(USERID) |
9 |
=A8.new(~.align@a(3,EVENTGROUP):e,e(1).select(VISITTIME<et).group@u1(VISITTIME):e1,e(2).group@o(SESSIONID):e2,e(3):e3) |
10 |
=A9.run(e=join@m(e1:e1,SESSIONID;e2:e2,SESSIONID).select(e2=e2.select(VISITTIME>e1.VISITTIME && VISITTIME<e1.VISITTIME+86400000).min(VISITTIME))) |
11 |
=A10.run(e0=e1.id(DEVICETYPE),e1=e.min(e1.VISITTIME),e2=e.min(e2),e=e.min(e1.SESSIONID),e3=e3.select(SESSIONID==e && VISITTIME>e2 && VISITTIME<e1+86400000).min(VISITTIME),e=e0) |
12 |
=A11.news(e;~:DEVICETYPE,e2,e3).groups(DEVICETYPE;count(1):STEP1_COUNT,count(e2):STEP2_COUNT,count(e3):STEP3_COUNT) |
A8 每次读入一个 ID 的所有事件,然后用 A9 到 A12 四句代码实现复杂判断逻辑,最后 A12 分组统计时也只要简单计数就可以了,不用再考虑去重了。
SPL 解决老大难问题 JOIN
SPL 还能解决 SQL 的老大难问题 JOIN。
SQL 对于 JOIN 的定义并不涉及主键 ,但几乎所有有业务意义的 JOIN 都和主键相关 SQL 无法利用这个特征。采用双边 HASH JOIN 算法不仅计算量大,在外存和集群时的性能还不可控。
SPL 重新定义 JOIN,把 JOIN 分类,可以充分利用主键特征来降低计算量,不仅计算快,也没有不可控的问题。
结果,SPL 的关联表运算性能常常超过 SQL 的宽表。
进一步讨论
SQL 为什么写不出我们期望的高性能算法呢,表面上看是因为对某些运算的支持不足,比如有序计算,分组子集等。更深层原因在于其理论基础 - 关系代数过于简单,缺少必要的数据类型和相应的基础运算。五十年前的理论体系不能表达现代应用的计算需求,也是很正常的。
那么工程上的手段是否可以解决 SQL 慢的问题呢?
比如分布式并行计算。这种手段有时候可以提高性能,但成本太高。
SQL 调优能起到的作用也有限,对于复杂情况不管用。调优确实能通过改变执行路径来采用某些高效算法,但相当多高性能算法在 SQL 中根本没有。
用 UDF 编写高性能代码,原则上可行,但成本太高,可操作性差。集群环境中还会带来复杂的调度和运维问题。而且,如果不能改变数据库存储方案,仅用 UDF 也很难提速。
总之,工程上的优化方法成本高、效果差,没有什么有效手段。SQL 慢是理论层面的问题,工程优化只能有限改善,不能根除。
SPL 则没有继续采用关系代数,而是发明了离散数据集理论,这就会有更丰富的数据类型和基础运算:

图中带星号的都是 SPL 独创的算法。
有了这些基础,就容易写出低复杂度的代码,充分利用硬件资源,实现比 SQL 快出数量级的高性能计算。
SPL 其实提供了集群计算能力,不过在 SPL 的性能优化案例中,大部分场景单机已经足够,集群功能很少有机会得到历练,以至于 SPL 几乎不宣传分布式能力。
SPL 现已开源,欢迎下载: https://github.com/SPLWare/esProc 。


英文版