


(已解决) 集算器函数按文本中的位置增删改
大佬们,请问集算器处理文本的函数中有没有按位置替换值的功能?
以我目前所熟悉的 spl 函数,处理文本替换的有两个:
1、regex@a ,正则替换所有匹配的文本;
2、replace,把文本中的 old_text 替换成 new_text
这两个函数是把所有指定的文本替换成对应的值,不能按位置替换,比如:
spl 中的 replace: =replace(“ACACA”,“A”,“X”) 就把所有的 A 替换成了 X,得到 XCXCX
这样的替换相当于 excel 函数中的 substitute,如下所示:

excel 函数中也有一个 replace 函数,是按文本中的位置进行替换,比如,从第 3 位开始替换,替换 1 位,替换成 X,第 3 参数大于 0 表示替换:

如果第 3 参数是 0,表示在 2 参表示的位置插入一个值,如下:

如果第 3 参数大于文本长度,就直接替换至末尾,如下:
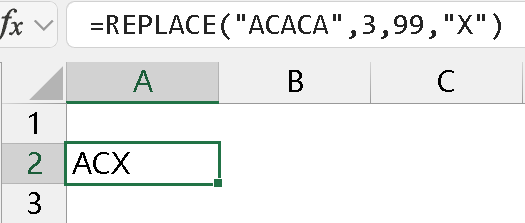
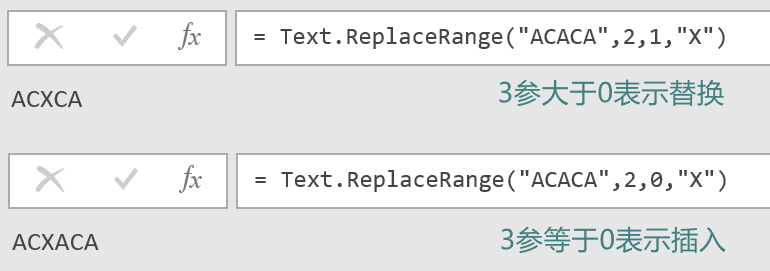
第 2 参数所表示的索引必须大于 0,不支负数,第三参数所表示的替换长度要大于等于 0,大于 0 时表示替换,等于 0 时表示插入。同属于微软系的 Powery Query 也有类似的按位置替换的文本处理函数 Text.ReplaceRange 函数,功能跟 excel 函数是一样的,除了 2 参表示的索引下标不同,PQ 的索引下标是从 0 开始的,如下:
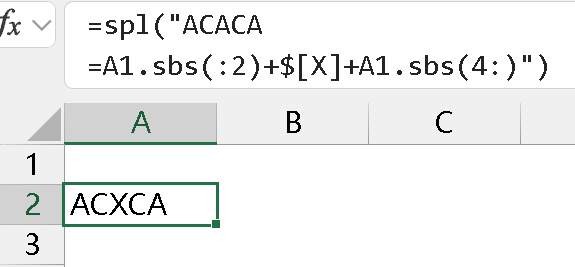
在 spl 中,如果要处理成类似的结果,比如替换,要先按位置切片,然后拼接,比如:
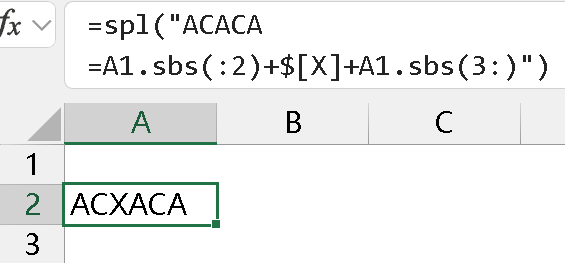
插入时同理,位置少切 1 位:
或者先把文本变成序列,然后用序列中的 modify 或者 insert 方法处理替换、插入后再拼接:
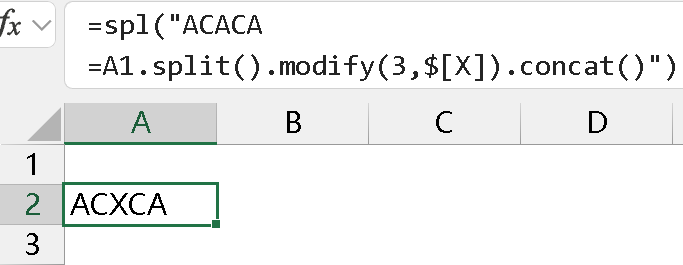
按位置插入时如下: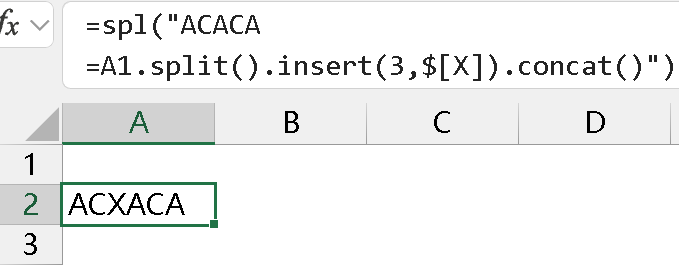
按位置删除时用 delete:
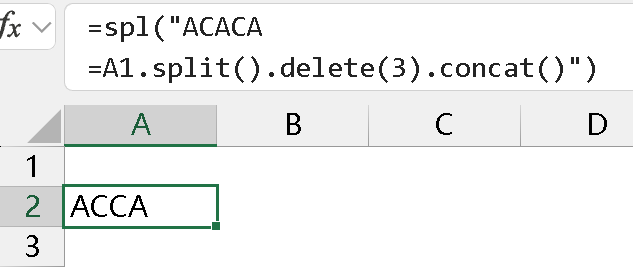
文本串 split 变成序列后,方法相对会多一些。这么多方法不能说不方便,但先拆后合,总感觉多了一步,个人感觉有点不利落。
我是在写异序词 (也就是文本串的排列) 时碰到了这个按位置替换的问题,如下所示,求出文本串 ACAA 的所有异序词,也就是所有字母的全排列拼成的文本串:

所以,想恳请大佬们看看,有没有较简洁的方法来实现文本串中按位置增删改。


replace 函数做了调整,允许第二个参数为位置或者位置: 长度,语法为 replace(s,p:l,b),例子如下:
在字符串 s 的第 2 个字符前插入 s2 可写为:replace(s,2,s2)
删除字符串 s 从第 2 个字符开始的 3 个字符可写为:replace(s,2:3)
把字符串 s 从第 2 个字符开始的 3 个字符替换为 s2 可写为:replace(s,2:3,s2)
谢谢大佬🙏
等 jar 包更新我测试一下😄 位置支持负数吗?
不支持负数
程序已更新,请前往下载贴中下载最新的 esproc-bin.jar 文件
大佬,长度超出文本长度也是不允许的对吧:
要通过计算得到最大允许长度:
长度超出文本长度时做了处理,已提交到 git 上
谢谢大佬🙏 🙏
语句简洁不少,文本处理函数 sbs,replace 好用的很😄 👍
位置做了修改,支持负数
😄 😄 👍 👍 谢谢大佬,麻烦你了。
那我再多问一句,目前以下 3 中写法都表示在指定位置插入值:
replace(str,2,X)
replace(str,2:0,X)
replace(str,2:,X)
第一种是最正常的插入,第二种其实是替换,替换 0 长度,相当于插入了,第三种冒号后面是空,目前视同为 0 处理。
我在想,冒号后面是空,是视同为 0 合适还是视同为剩余全部合适,比如:
replace(str,2:,X) 这样表示替换位置 2 开始的所有为 X
replace(str,2:) 这样表示删除位置 2 及其后面的所有文本
看上去两种都可以😄 ,恳请大佬指导解惑🙏
这个意义不太大了,用 left(s,n)+x 实现起来也很容易。
规则多了增加学习成本,写出的代码也不利阅读。
好嘞,懂了,感谢大佬指导解惑,麻烦你了,谢谢🙏 🙏