


(已解决) 关于组表 T.cursor(x:C,...;) 中 x 表达式的疑问
😄 两个疑问:
1、x 表达式能不能直接用函数处理,甚至是字段之间的运算后得到一个新字段;
2、如果后续计算中要用到字段之间的运算,可不可以先在 cursor 处完成,对效率有没有积极影响?比如,有数量, 单价和折扣 3 个字段,先在 cursor 中计算得到新字段: 数量×单价×(1- 折扣)
这样写就免去了后续计算中对这个值的重复计算,当然也有其他途径避免重复计算。
对于第 1 个疑问,根据文档说明,T.cursor(x:C,…;) 中参数 x 是表达式,缺省时返回 T 中的所有字段。我的理解是 x 表达式既可以直接写字段名,也可以是字段进行计算后得到的 x,比如数值字段的加减乘除,文本字段的文本处理,或者是字段之间的运算…等等,应该都属于表达式。我就好奇做了些测试,如下所示:
1、对组表文件中的文本型字段 L_SHIPMODE 用 sbs 函数截取,结果符合预期。
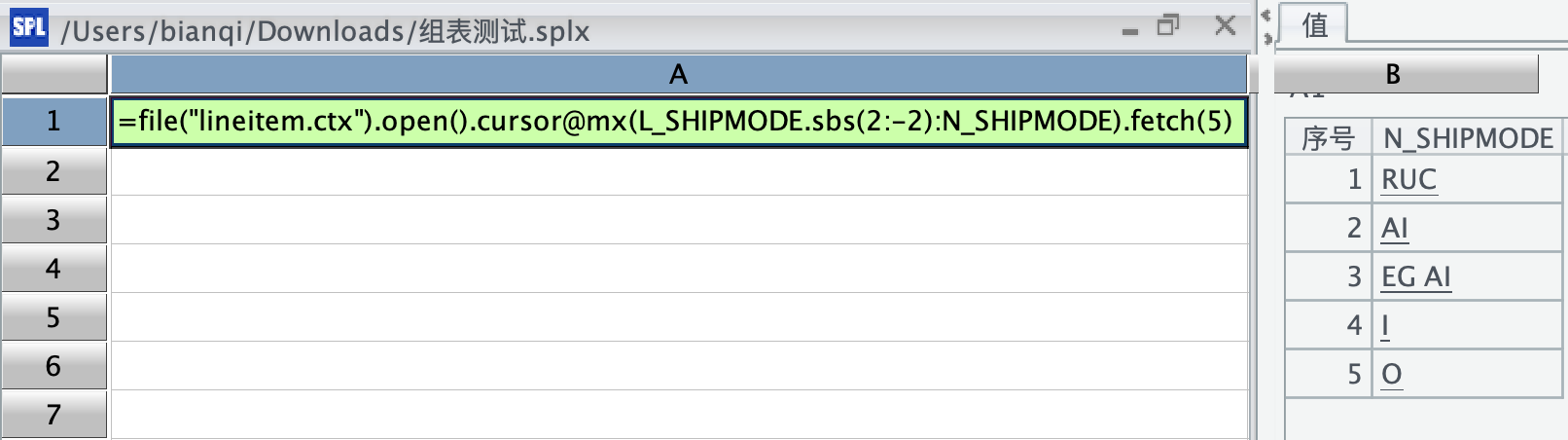
此时,若换成 mid/left/right 就报错了,不能识别字段,如下所示:
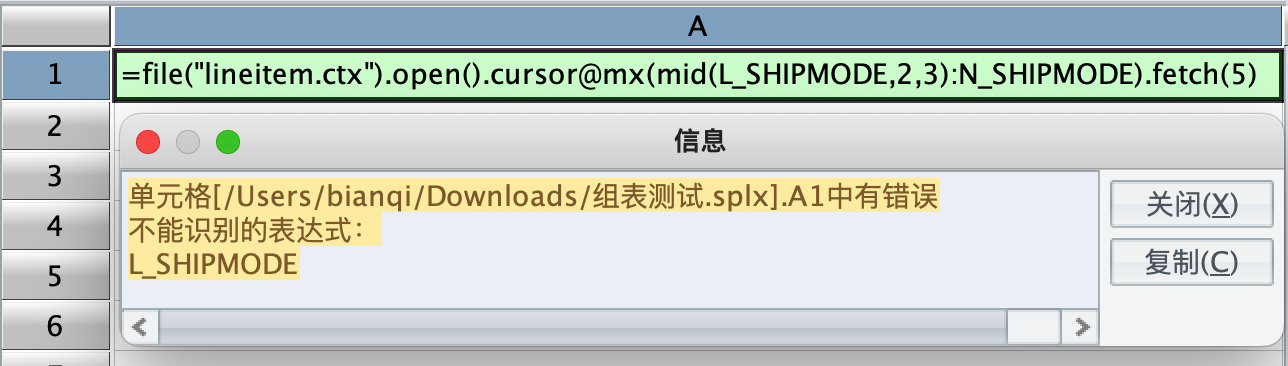
既然不能识别字段,那把字段先获取出来,再处理,也就是写两遍,结果符合预期,如下:

跟第一种情况的区别就是,sbs 能直接处理字段,而其他一些函数不能直接处理字段,须把字段先获取出来,再去处理。
2、再来看看数值型字段的处理情况,比如,对数值型字段 L_DISCOUNT 直接乘以 10,报错了:
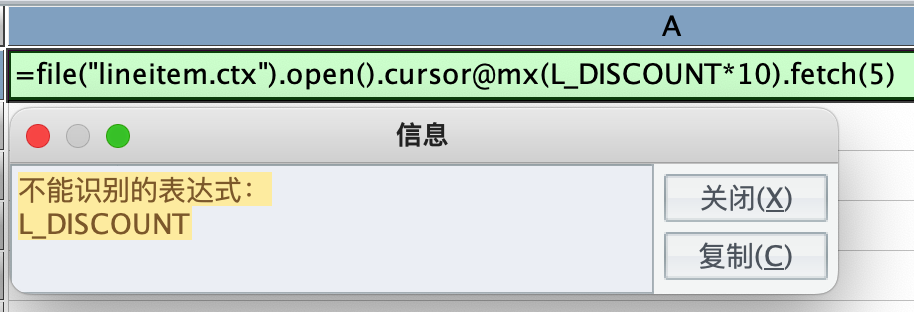
把 L_DISCOUNT 先写出来,再写一遍乘以 10,返回结果符合预期:
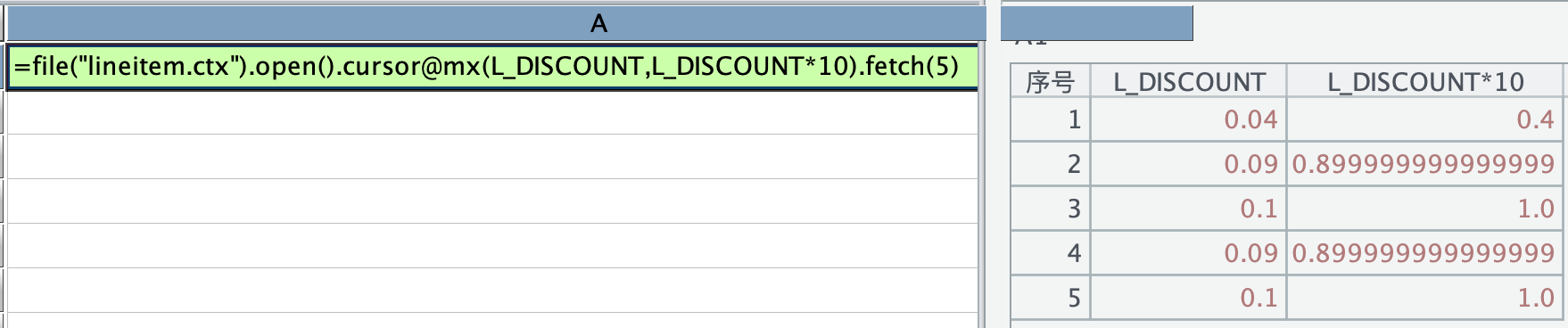
此时,再把乘法换成加法,报错了:
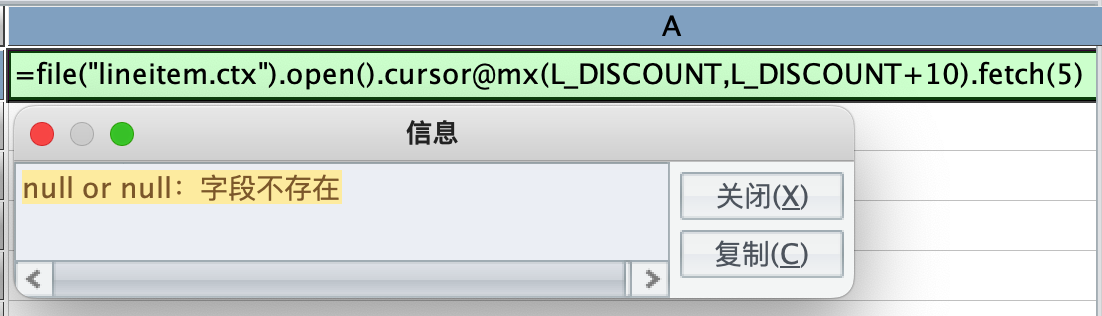
如果把加法换成 sum(字段,10),不会报错:
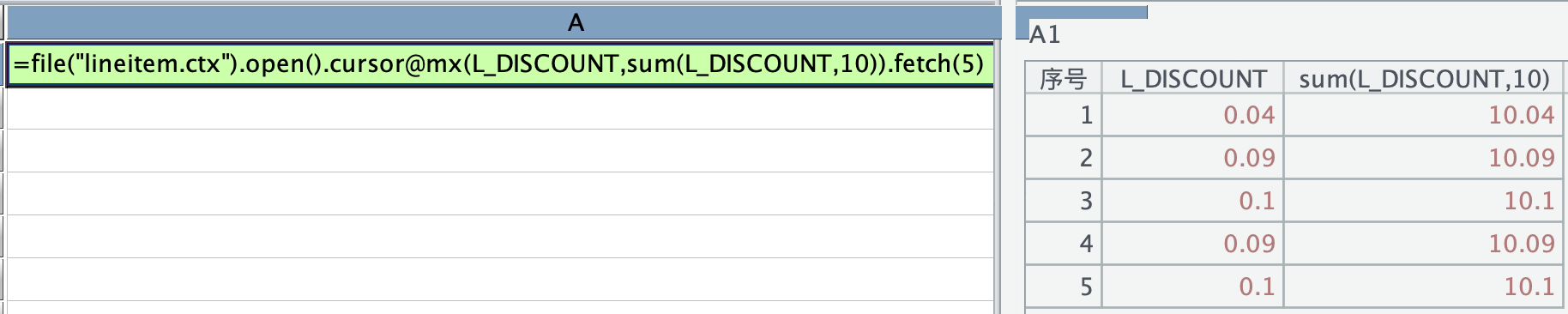
再来试试减法,减法可以返回预期结果:
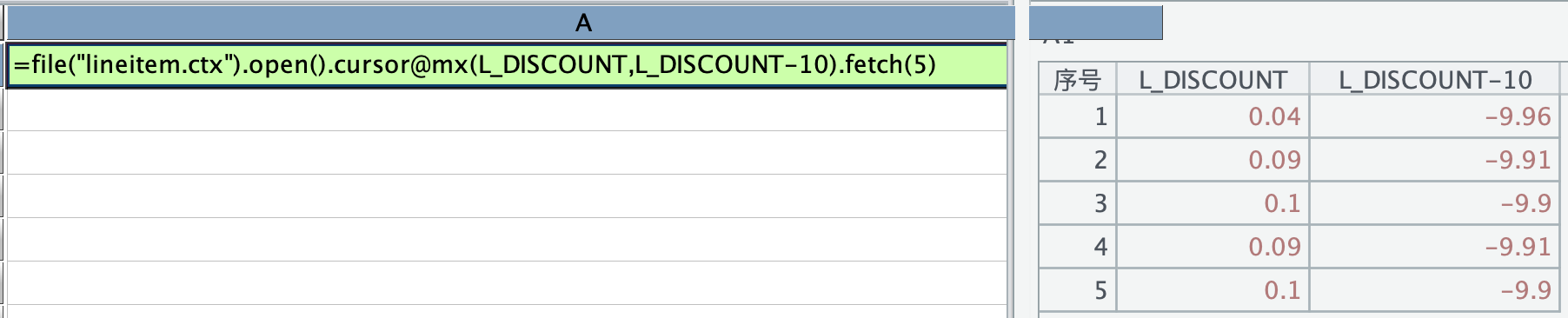
那上述加上 10 报错,变成减去 -10 行不行,结果返回正确:
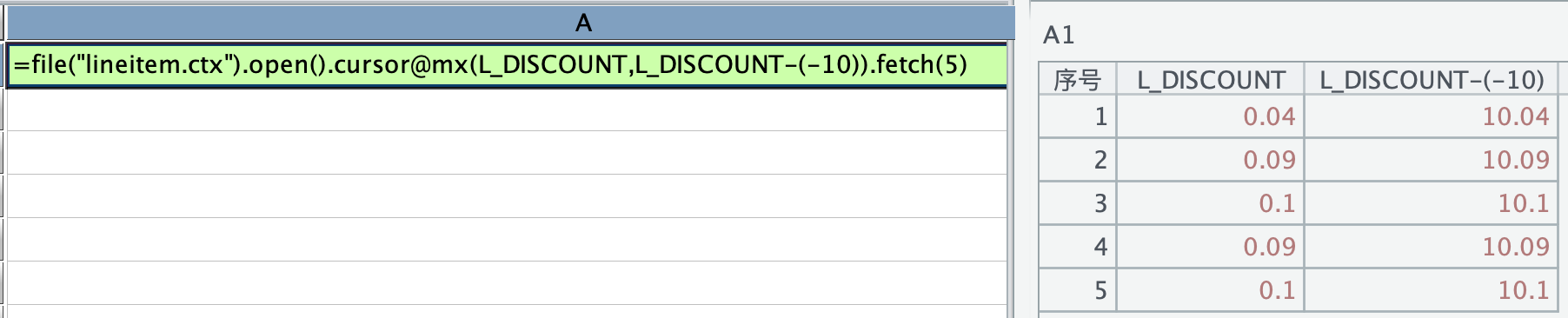
只要是乘除减都可以,唯独加法不行,加上负数也报错:
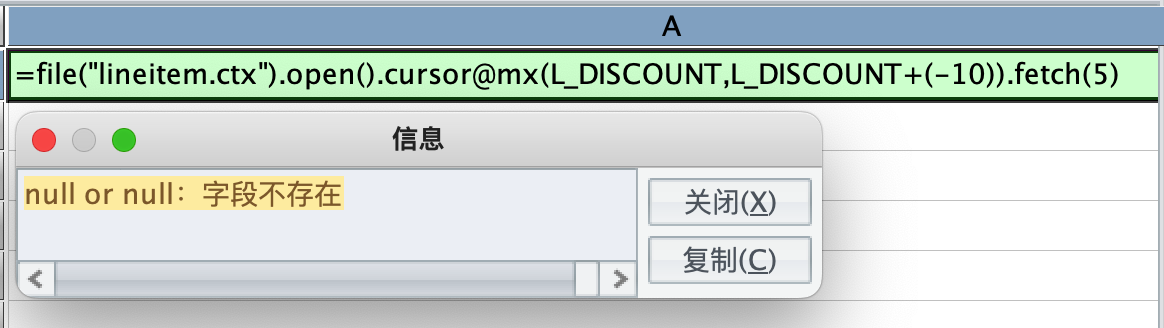
第 2 个疑问,是在学习 性能优化案例课程 TPCH-Q1 时想到的,文中第 7 部分有如下描述,

代码中 L_EXTENDEDPRICE*(1-L_DISCOUNT) 这部分是在后续 groups 聚合计算时算的,赋值给了变量 dp。我就在想,如果把这部分移到上一步获取数据时在 T.cursor() 中直接得到一个新字段 dp,会不会对效率有积极影响,在测试过程中碰到了本帖求助的这些问题,有点困惑:
能不能直接对字段处理,甚至是字段之间的直接运算,不用先把字段写出来,再写一遍计算;
在 cursor 处运算得到一个新字段,会不会影响效率,我自己测试看不出名堂,好像快一些,又好像没啥区别。
帖子中用到的 ctx 文件是 TPCH 的测试文件,应该能弄到,或者可以通过以下途径得到:
2、 https://pan.baidu.com/s/1RIo8JqQqD8-STyNNYt5ADA?pwd=spl6
恳请大佬们得闲时给予指导解惑🙏


x 不是真正的表达式。一些表达式能执行,是因为支持附表写法的缘故。目前不建议把 x 作为表达式使用。
效率问题可以用 derive 来改进:
=A7.derive@(L_EXTENDEDPRICE*(1-L_DISCOUNT):dp,L_RETURNFLAGA4+L_LINESTATUS:gk)
=A8.groups@(gk;sum(L_QUANTITY):sum_qty, sum(L_EXTENDEDPRICE):sum_base_price,sum(dp):sum_disc_price,sum(dpL_TAX):sum_charge, sum(L_DISCOUNT):sum_disc, count(1):count_order)
懂了,谢谢大佬指导解惑🙏
我也是好奇,因为函数文档中只有组表相关的 cursor(),import() 里边用了 x 表达式,而 file().cursor()/import() 明确写了是 Fi 字段。想着既然是表达式,那应该支持运算,所以就尝试了一下。
derive@o 在论坛文章中看到过多次,这个用法记住了,谢谢大佬指导,现在有些碎片化的东西开始慢慢成型了😄
老贼之前说过 "正确的写法得到正确的结果",看来不能天马行空乱整胡来,得多看看官方的正统写法。