


A1.split("DFX") 得到的长度不对
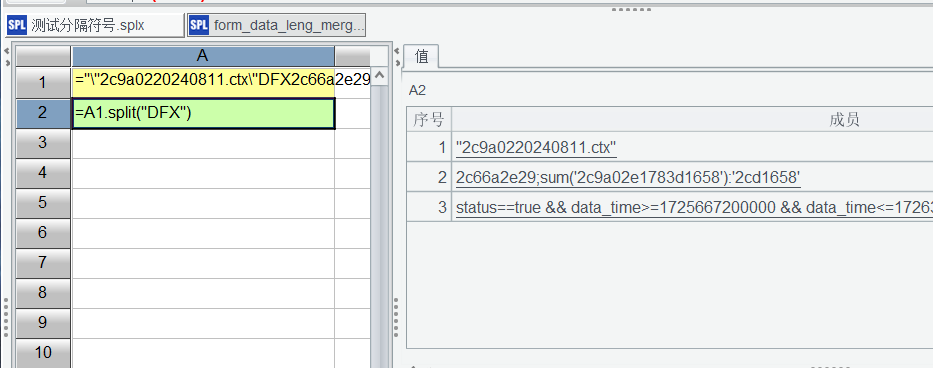
A1 的内容是:
=“"2c9a0220240811.ctx"DFX2c66a2e29;sum(‘2c9a02e1783d1658’):’2cd1658’DFXstatus==true && data_time>=1725667200000 && data_time<=1726314426000 && ["1349755xx","1821693xx"].contain@b(26a2e29),switchboard_identity_id:D5DFXDFXDFXDFXDFX2c9a02e1783b5e3701785de4766a2e29DFX2c9a02e178d1658,2c9a0e4766a2e29DFXfalseDFXfalseDFXtrueDFXB19DFXDFXDFXDFXDFXDFXDFX2c9a02e4ad1658”
A2 的内容是:
=A1.split(“DFX”)
集算器输出的结果是 3 个,我期望得到的结果是 20 个。
这个 A1 字符串是程序组成的参数字符串,不同的场景有些参数是空。但是总体切割之后参数个数是 20 个。
测试脚本下载链接:


试试 =A1.split@b(“DFX”)
split 默认是对引号和括号做匹配检查的,括号除了常规括号还包含了尖括号、中文括号等…
文中的小于号被用于做 <> 匹配了,所以后面的分隔符没有被识别出。
可以了
程序新做了修改,默认不再把 < 当做括号,增加了 @g 选项用于表示尖括号也做括号匹配
大佬,我之前求助的括号匹配是不是把事情搞复杂了😄 (已解决) split/import 时的括号匹配处理
中文括号比较合理,当时没考虑小于号,这个比较常见,当成默认的括号匹配处理不太合适