


开源 BI 实践:集算器 DQL
DQL 通过自动关联表,能提升了 BI 前端用户查询数据能力。遇到较大数据量时,新增的查询能力容易碰上性能问题。成熟的数据库厂商对 SQL 多表关联查询已做过大量性能优化,但表稍多,优化手段就逐渐失效,性能依旧低效。
集算器组表是一种高性能存储格式,再配合能写出高性能算法的 SPL 脚本,就能对多表关联查询性能有较大改善。基于集算器组表和 SPL 实现的 DQL 既提升了 BI 用户的查询能力,又有较高的查询性能。
创建集算器 DQL 元数据
以 TPCH 的原始文本数据文件为基础,用《把数据表转储成组表》里的方法,把它们转存成组表文件:
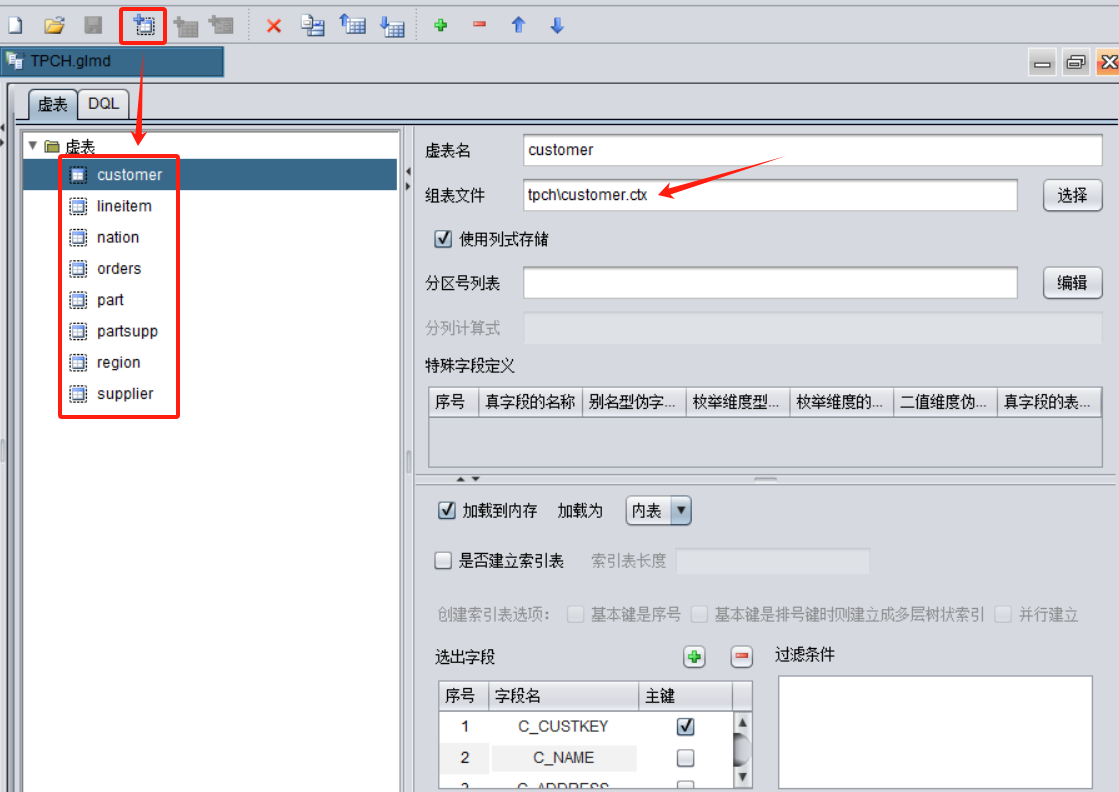
然后打开集算器DQL设计器:{集算器安装根目录}/esProc/bin/dql.exe,新建元数据(TPCH.glmd),用这些组表文件创建出虚表:
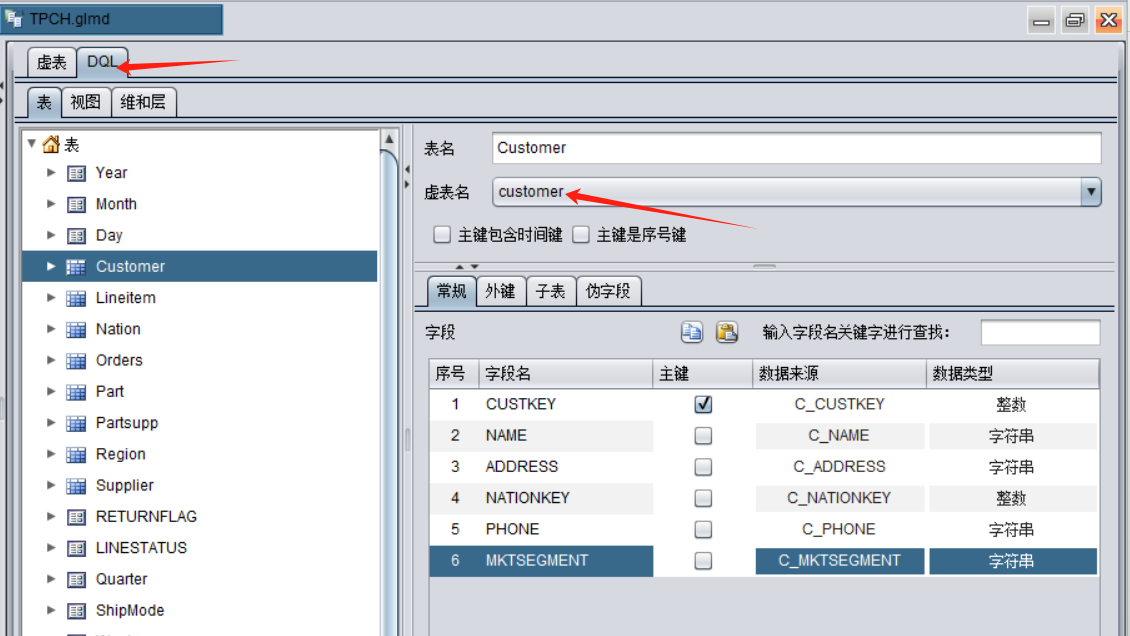
基于虚表再设置DQL元数据就与之前的报表DQL无异了,只是数据不再来自数据库表,而是之前定义的虚表:
部署 DQL 服务
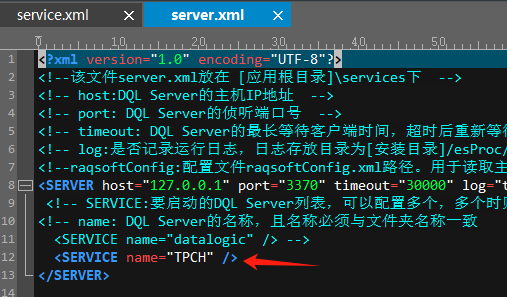
报表DQL的服务器部署在service目录下,集算器DQL则部署在esproc-services目录下,其下的结构一样了,esproc-services/server.xml中配置TPCH服务,服务端口设置为3370,避免和同一服务器上的报表DQL冲突:
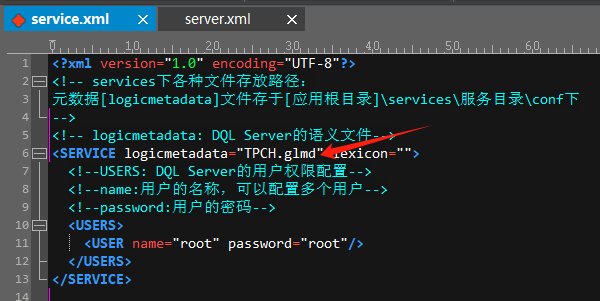
esproc-services/TPCH/service.xml中不用配置数据库的JDBC数据源了,配置上元数据文件即可:
部署集算器 DQL 的 WEB 查询页面
WEB-INF/web.xml 下增加 Servlet:
<servlet>
<servlet-name>DqlServlet</servlet-name>
<servlet-class>com.scudata.web.dql.esprocdql.DqlServlet</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>DqlServlet</servlet-name>
<url-pattern>/DqlServlet</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>DqlServlet</servlet-name>
<url-pattern>/DqlServletAjax</url-pattern>
</servlet-mapping>
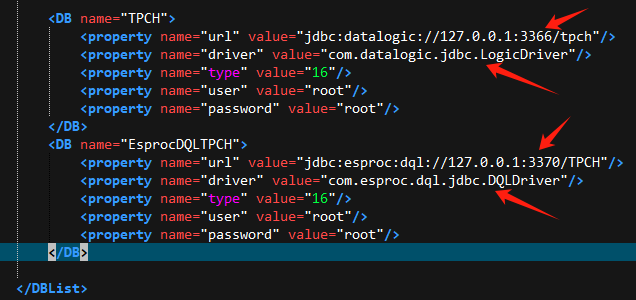
WEB-INF/raqsoftConfig.xml中配置集算器DQL的JDBC,注意与报表DQL的驱动类不同,看以下两者对比:
然后把esproc-*.jar、guide-*.jar复制到自己WEB的WEB-INF/lib下。
基于DQL的元数据树,之前已经让前端用户能比较敏捷地做多维分析、制作DBD,现在再实现一个侧重于数据查询的页面,访问/raqsoft/dql/jsp/dqlQuery.jsp:
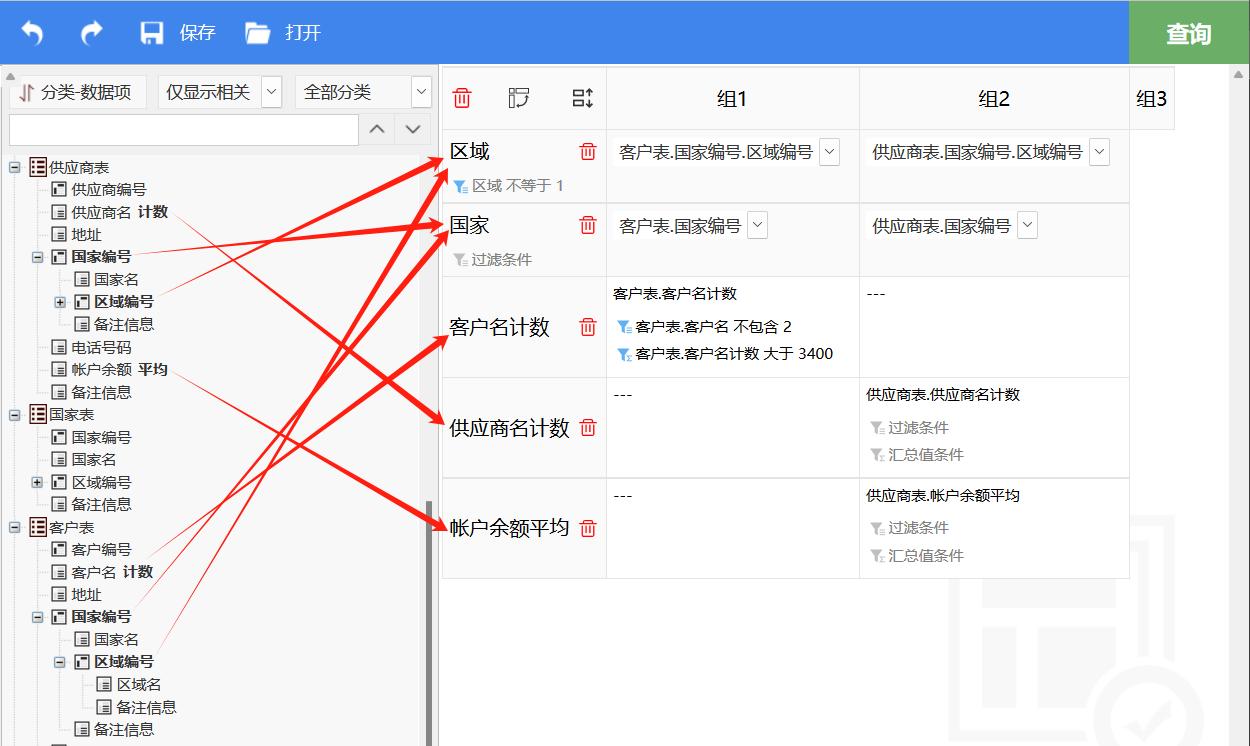
从左侧元数据树上把字段拖选到右侧进行查询。如上,按区域、国家统计客户数、供应商数、供应商账户平均余额,并设置了一些查询条件。这个界面能比较形象的反映出查询过程:
1、组1中按照区域、国家计算出客户数;
2、组2中按照区域、国家计算出供应商数、供应商账户平均余额;
3、最后按照相同的区域、国家再把两组汇总值合起来。
开源代码及二次开发
查询页面 JSP 是 {WEB 根目录}/raqsoft/dql/jsp/ dqlQuery.jsp;
{WEB 根目录}/raqsoft/dql/js/ 下的 query.js、dqlApi.js、dqlreport.js、where.js 是实现主要功能的 JS 代码;
Java 源码是 com.raqsoft.guide.esprocdql 包下的几个类。
这是基于 DQL 的第三种风格 BI 前端方案,不管 BI 前端设计成什么样,只要基于 DQL 查询模型,都容易让前端用户自然地提高查询数据能力,再配合上提高性能的集算器 DQL,让敏捷 BI 口号就变成了现实。

