


解放数据科学家的神器 esProc SPL
SQL 正在消耗数据科学家的生命
SQL 难写
数据科学家几乎都会用 SQL 做探索分析,SQL 看上去很简单,也有一定的交互性,做数据探索分析似乎很不错。
比如要进行过滤、分组等计算,简单一句就能完成:
select id,name from T where id=1
select area,sum(amount) from T group by area
但这只限于简单的情况,情况复杂时 SQL 的代码就没那么简单了。比如计算每支股票的最长连续上涨天数,SQL 写出来:
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT, SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
还有电商业务中常见的用户行为漏斗分析:
WITH e1 AS (
SELECT uid,1 AS step1, MIN(etime) AS t1
FROM events
WHERE etime>=end_date-14 AND etime<end_date AND etype='etype1'
GROUP BY uid),
e2 AS (
SELECT uid,1 AS step2, MIN(e1.t1) as t1, MIN(e2.etime) AS t2
FROM events AS e2 JOIN e1 ON e2.uid = e1.uid
WHERE e2.etime>=end_date-14 AND e2.etime<end_date AND e2.etime>t1 AND e2.etime<t1+7 AND etype='etype2'
GROUP BY uid),
e3 as (
SELECT uid,1 AS step3, MIN(e2.t1) as t1, MIN(e3.etime) AS t3
FROM events AS e3 JOIN e2 ON e3.uid = e2.uid
WHERE e3.etime>=end_date-14 AND e3.etime<end_date AND e3.etime>t2 AND e3.etime<t1+7 AND etype='etype3'
GROUP BY uid)
SELECT SUM(step1) AS step1, SUM(step2) AS step2, SUM(step3) AS step3
FROM e1 LEFT JOIN e2 ON e1.uid = e2.uid LEFT JOIN e3 ON e2.uid = e3.uid
上面的两个例子都需要使用多层嵌套的子查询,读懂都不容易,写起来难度更大。
实际业务中,类似的计算还有很多,比如:
-
1 分钟内连续得分 3 次的球员
-
每 7 天中连续三天活跃的用户数
-
每天新用户的次日留存率
-
股价高于前后 5 天时当天的涨幅
-
…
这些复杂需求通常要求多步过程,还涉及次序相关运算,SQL 实现非常绕,动不动就得上百行嵌套 N 层。数据科学家的生命消耗在 SQL 编写中。
SQL 难调试
复杂 SQL 调试十分不便,像上面看到的那些业务中常见的复杂 SQL 都嵌套多层,调试需要逐层拆解后分别执行,拆解过程中还要伴随 SQL 调整和修改,整个调试过程非常麻烦。
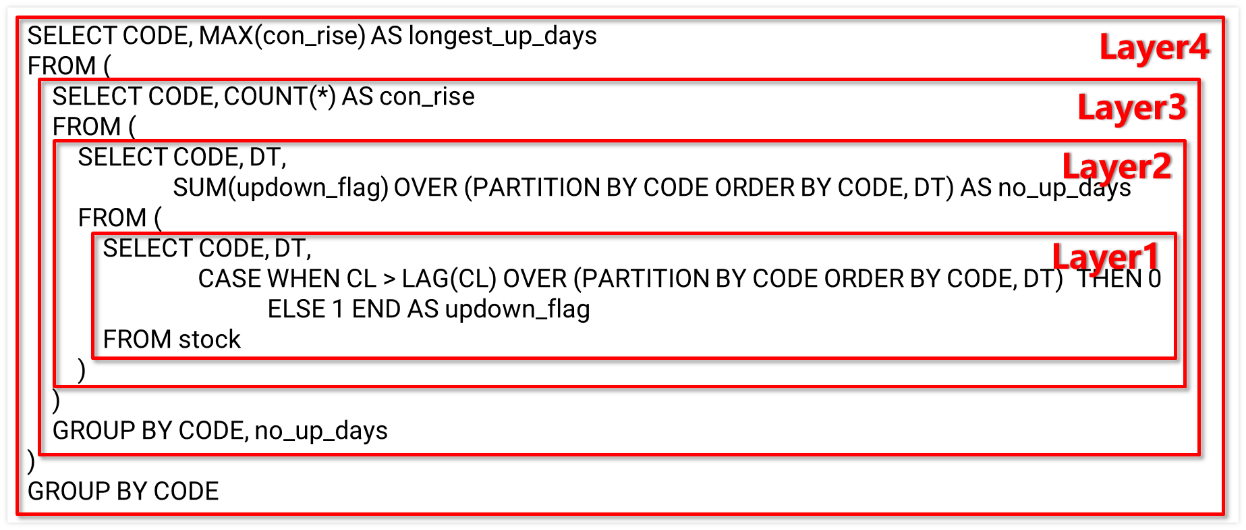
这是因为 SQL 没有设置断点、单步执行这些很常见的调试方法,想要调试就只能硬着头皮拆解,数据科学家的生命消耗在 SQL 调试中。
SQL 低性能
SQL 的查询性能主要依赖数据库提供的优化引擎,好的数据库可以根据计算目标采用更高效的算法(而不是 SQL 字面的意思),但这种自动优化机制在面对复杂情况时经常失效。
举个简单的例子,如果要从 1 亿条数据中取前 10 名,SQL 写出来是这样的:
SELECT TOP 10 x FROM T ORDER BY x DESC
这个 SQL 虽然有 ORDER BY 的字样,但数据库优化引擎并不会真正进行大排序(大数据排序很慢),而会选择其他更高效的算法。
但如果我们稍微改一下,计算每个分组内的前 10 名,SQL 写起来是这样:
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rn
FROM Orders )
WHERE rn<=10
虽然实现上并没有复杂太多,但此时大部分数据库的优化引擎就会犯晕了,猜不出这句 SQL 的目的,只能老老实实地执行按语句书写的逻辑去执行排序(这个语句中还是有 ORDER BY 的字样),结果性能陡降。
现实业务中的 SQL 的复杂度远远超过这个例子,数据库优化引擎犯晕的情况相当常见。比如前面那个漏斗运算的 SQL 语句,需要反复关联,不仅是写出来困难,执行性能也极其低下。
性能低就要等待,有的大数据场景下甚至要等数小时到一天,数据科学家的生命就这样在等待中消耗。
SQL 封闭
SQL 是数据库的形式化语言,数据库的封闭性会导致数据处理困难。所谓封闭性,是指要被数据库计算和处理的数据,必须事先装入数据库之内,数据在数据库内部还是外部是很明确的。
而实际业务中,数据分析师们经常还要处理其他来源的数据,文本、Excel、程序接口、网络爬虫不一而足。这些数据有些只是临时用一下,如果每次都需要装进数据库才能使用,不仅会占用数据库的空间,ETL 过程也需要消耗大量时间,数据库通常还有约束,有些不符合规范的数据无法写入,这就需要先花时间精力整理数据;整理完数据写入又需要时间(数据库写入很慢)。数据科学家的生命就这样白白消耗在整理数据、入库出库的琐事中。
Python 也在浪费数据科学家的生命
SQL 有各种不如意,数据科学家也会寻求其他工具,比如 Python。
Python 在很多方面优于 SQL,包括调试方便度、过程性计算、开放性等。但 Python 仍存在诸多缺点。
复杂情况仍然不好写
Python 的第三方库 Pandas 有丰富的计算函数,有些计算的确比 SQL 写得简单。但情况复杂时,代码仍然不太好写。比如前面计算的每支股票最长连续上涨天数:
import pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
Python 写起来也很繁琐,还要用 for 循环来硬编码。数据科学家的生命仍在消耗中。
调试功能仍然不理想
Python 有很多 IDE,也提供有断点等调试功能,比 SQL 好得多,不必再拆解代码。
但查看中间值仍然主要靠 print 大法,调试完还要删掉,浪费时间。
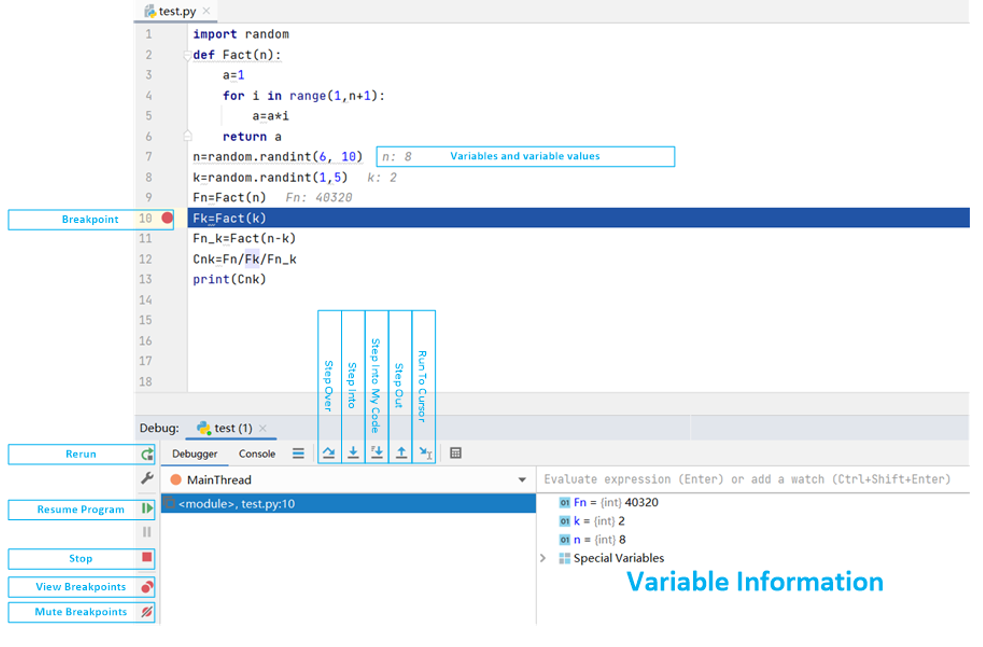
调试不便就要多花时间,数据科学家的生命持续消耗。
大数据能力弱性能低
Python 基本没提供大数据运算的能力。Pandas 库虽然可以直接进行排序、过滤等内存计算,但这些函数不能直接处理超出内存的大数据,需要硬编码分段处理,代码会复杂许多。
Python 的并行是假的,想要利用多 CPU,还得用复杂的多进程并行,这超出了大部分数据科学家的能力范围。写不出并行代码,就只能串行慢慢跑,数据科学家的生命消耗殆尽!
SQL 不行,Python 也不好,那谁能解放数据科学家的生命?
esProc SPL 解放数据科学家
esProc SPL!专门面向结构化数据处理的工具。
SPL 简洁易懂,调试便利,还有大数据和高性能的支持,可以从根本上解决 SQL 和 Python 的诸多缺点。
写着更简单
SPL 提供了丰富的数据类型和计算类库,同时支持过程计算,可以大幅简化复杂计算的实现代码。比如前面计算每支股票的最长连续上涨天数,SPL 的实现:
A |
|
1 |
=stock.sort(StockRecords.txt) |
2 |
=T(A1).sort(DT) |
3 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
代码更简短,也不需要循环语句,读 / 写都没有太大难度。
电商漏斗分析:
A |
|
1 |
=["etype1","etype2","etype3"] |
2 |
=file("event.ctx").open() |
3 |
=A2.cursor(id,etime,etype;etime>=end_date-14 && etime<end_date && A1.contain(etype) ) |
4 |
=A3.group(uid) |
5 |
=A4.(~.sort(etime)).new(~.select@1(etype==A1(1)):first,~:all).select(first) |
6 |
=A5.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) |
7 |
=A6.groups(;count(~(1)):step1,count(~(2)):step2,count(~(3)):step3) |
SPL 同样更简洁,也更符合自然思维,而且这段代码还能对付任意多步的漏斗,比 SQL 简单又通用。
调试更方便
SPL 还有完整的调试功能,包括:设置断点、执行到光标、单步执行等功能。每步计算结果能在右侧实时查看,不用再消耗精力拆分子查询或手动 print,非常方便。
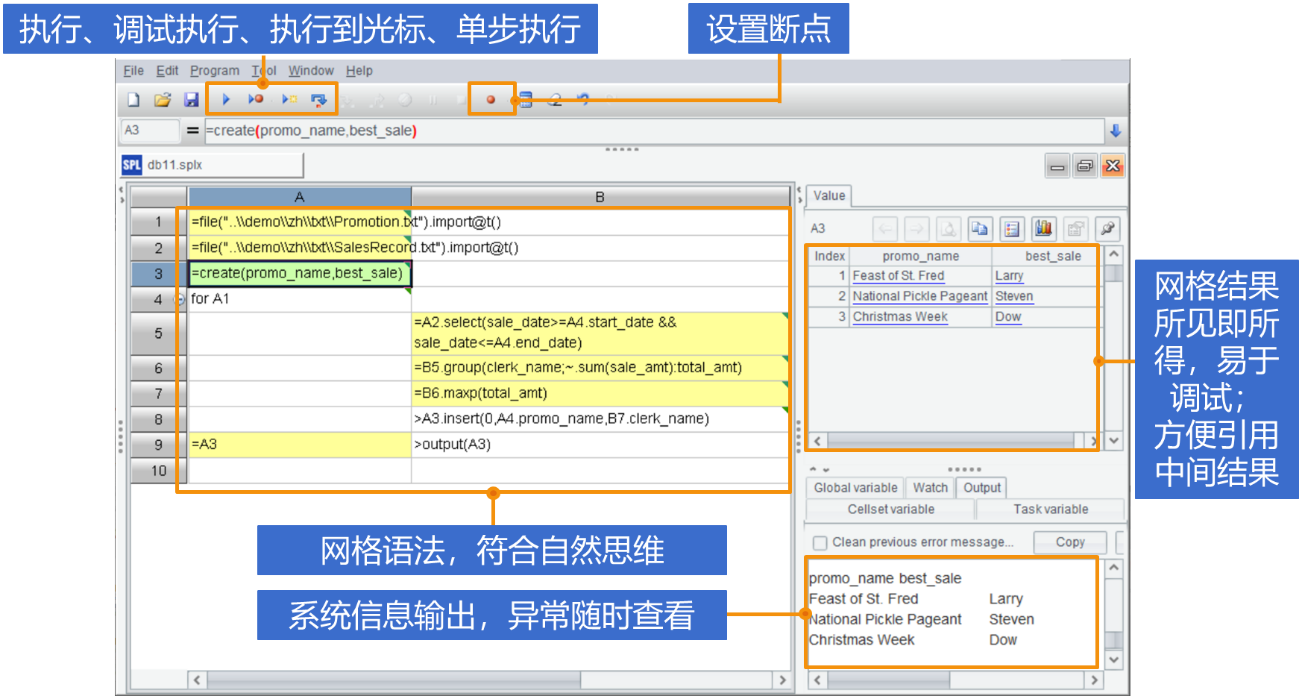
大数据支持
SPL 支持大数据,内存装不装得下都能计算。
内存计算:
A |
|
1 |
=d:\smallData.txt |
2 |
=file(A1).import@t() |
3 |
=A2.groups(state;sum(amount):amount) |
外存计算:
A |
|
1 |
=d:\bigData.txt |
2 |
=file(A1).cursor@t() |
3 |
=A2.groups(state;sum(amount):amount) |
从上面的代码可以看到,SPL 外存计算的代码与内存计算几乎完全一样,不会额外增加工作量。
SPL 也很容易实施并行计算,只需要在串行计算代码上增加一个 @m 选项就可以,很方便。
A |
|
1 |
=d:\bigData.txt |
2 |
=file(A1).cursor@tm() |
3 |
=A2.groups(state;sum(amount):amount) |
性能更高
SPL 还容易写出计算量小的代码,跑得更快。比如前面说到的 topN 问题,SPL 把 topN 理解为聚合计算,计算逻辑无须大排序,速度快很多,这是天然支持的,并不需要优化器辅助。
全集 TopN:
Orders.groups(;top(10;-Amount))
组内 TopN:
Orders.groups(Area;top(10;-Amount))
组内 topN 和全集 topN 写法基本一样,写得简单,跑得也快。
类似的,SPL 还提供了很多这样的高性能算法。包括:
-
查找:二分法、序号定位、索引查找、批量查找、……
-
遍历:游标过滤、遍历复用、多路游标、聚合理解、有序分组、程序游标、列式计算、……
-
关联:外键预关联、外键序号化、对位序列、大维表查找、单边分堆、有序归并、关联定位、…
-
集群:集群组表、复写维表、分段维表、负载均衡、……
有了这些算法,SPL 计算性能直接飞起,数据科学家无需再消耗生命长时间等待。
体系更开放
SPL 天然具有开放性,可以直接计算各种数据源,不管什么数据源,只要能访问到就能算,还能混算。比如 csv、Excel 等数据文件,以及各种关系和非关系型数据库等等,也能处理 json,XML 这类多层结构数据。

有了开放性的支持,数据科学家就可以直接快速处理多源数据,节省原来数据整理、入库出库的时间,提升数据处理效率。
良好的便携性与企业属性
SPL 还提供了自有文件格式,性能更高的同时也更便携。
A |
|
1 |
=d:\bigData.btx |
2 |
=file(A1).cursor@t() |
3 |
=A2.groups(state;sum(amount):amount) |
相比之下,Python 缺乏自有存储方案,使用文本文件太慢,使用数据库又会丧失便携性。
SPL 还有良好的企业属性。数据科学家完成探索分析后,可以将 SPL 以 jar 包嵌入的方式与应用集成,应用内外无缝切换。
有了 SPL 的简便性、易调试、高性能、开放性、易集成等能力以后,数据科学家就可以从繁重的编码工作中解放出来,更多投入到业务当中。
SPL 现已开源,欢迎下载:https://github.com/SPLWare/esProc


英文版