


倍增 Java 程序员开发效率的 esProc SPL
应用计算困境
顾开发还是顾架构?
Java 是当前应用开发最常用的语言,但是 Java 写数据处理的代码并不简单,比如针对两个字段的分组汇总要写成这样:
Map<Integer, Map<String, Double>> summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map<String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry<Integer, Map<String, Double>> entry : summary.entrySet()) {
int year = entry.getKey();
Map<String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry<String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
相比之下 SQL 就要简单很多,一句 group by 就出来了。
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
早期应用程序的确就是 Java 和 SQL 配合工作的,业务流程在应用端用 Java 实现,而数据处理则放到后端数据库中使用 SQL 实现。这种架构因为受制于数据库而难以扩展和移植,对现代应用很不友好,而且很多时候还面临无库或跨库的情况,也没有 SQL 可用。
所以后来很多应用也开始采用全 Java 架构,特别是微服务的兴起以后,数据库只做简单读写,业务流程和数据处理都在应用端通过 Java 实现,这样就能与数据库解耦,获得良好的扩展和移植性,从而带来架构上的优势。但这又会面临前面提到的 Java 开发难问题。
看起来开发和架构只能顾一头,用 Java 享受架构的优势就必须忍受开发困难,反之用 SQL 就要容忍架构上的缺点,面临两难境地。
还有什么办法?
那我们想办法增强 Java 的数据处理能力呢?这样既能避免了 SQL 的问题,同时还能克服 Java 的不足。
事实上,Java 下的 Stream、Kotlin、Scala 都在尝试做这件事。
Stream
Java8 以后引入的 Stream,增加了很多数据处理方法,前面的计算用 Stream 实现。
Map<Integer, Map<String, Double>> summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
Stream 的确能一定程度简化计算代码,但整体来看仍然繁琐,远不及 SQL 简洁。
Kotlin
而号称更强大的 Kotlin 则有进一步改进:
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Kotlin 也简单了一些,但还是不够,和 SQL 的差距仍然很大。
Scala
再看看 Scala:
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala 则又简单了一些,但仍然不能和 SQL 同日而语。Scala 还有过于沉重的缺点,使用起来并不方便。
其实这些技术的发展方向是对的,只是现在做的还不够好。
编译语言难以热切换
另外,Java 这些作为编译语言,不支持热切换,修改代码要重新编译部署,经常要重启服务,响应多变需求时的体验恶劣。SQL 在这方面反而没问题。
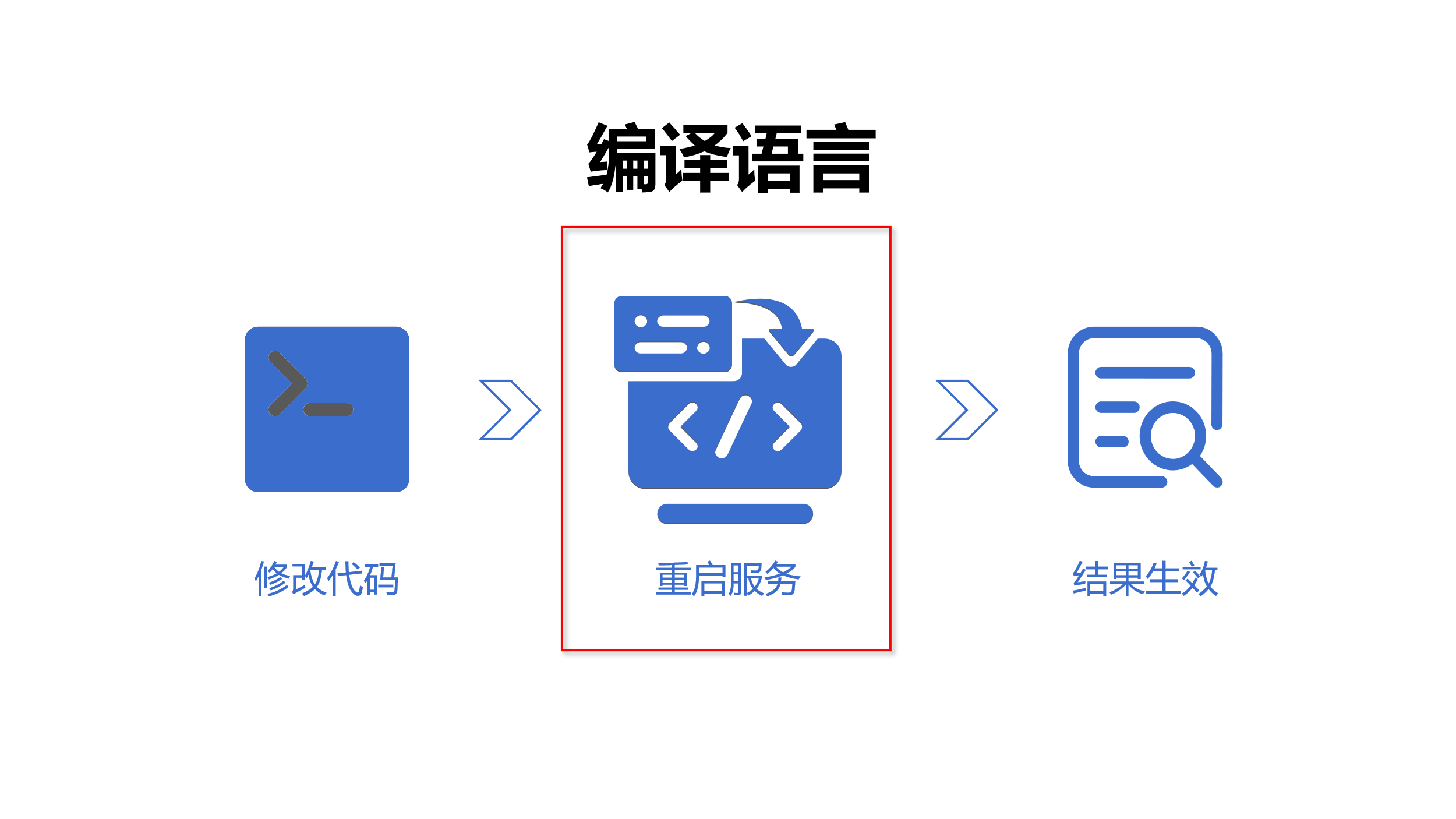
Java 开发麻烦,架构也有缺点,SQL 架构上很难满足,两难困境很难解决。还有什么办法吗?
终极解决办法 esProc SPL
还有 esProc SPL,纯 Java 开发的数据处理语言,开发简单、架构灵活。
语法简洁
我们回顾前面分组汇总的计算,Java 这些的实现:

相比之下,SPL 则要简洁得多:
Orders.groups(year(orderdate),sellerid;sum(amount))
这已经与 SQL 的实现一样简单了:
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
其实,很多时候 SPL 代码比 SQL 更简单。由于对有序计算和过程计算的支持,SPL 更擅长完成一些复杂计算。比如计算股票连涨天数, SQL 要嵌套三层,别说写,读懂都不容易。
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
这个计算 SPL 一句就能完成,比 SQL 简单很多,更是能甩 Java 那些几条街。
stock.sort(tradeDate).group@i(price<price[-1]).max(~.len())
完善、独立的计算能力
SPL 提供了专业的结构化数据对象序表,并在序表的基础上提供了丰富的计算类库。包括常规的过滤、分组、排序、去重、连接等计算,比如一般的:
Orders.sort(Amount) // 排序
Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // 过滤
Orders.groups(Client; sum(Amount)) // 分组
Orders.id(Client) // 去重
join(Orders:o,SellerId ; Employees:e,EId) // 连接
……
更重要的是,SPL 的计算能力与数据库无关,没有数据库时一样可以工作,具备独立的计算能力,不像 ORM 技术要翻译成 SQL 执行。
高效易用的 IDE
除了语法简单,SPL 还有功能全面的开发环境。提供单步执行、设置断点等调试功能,还有可视结果面板,可以实时查看每步计算结果,对调试非常友好。
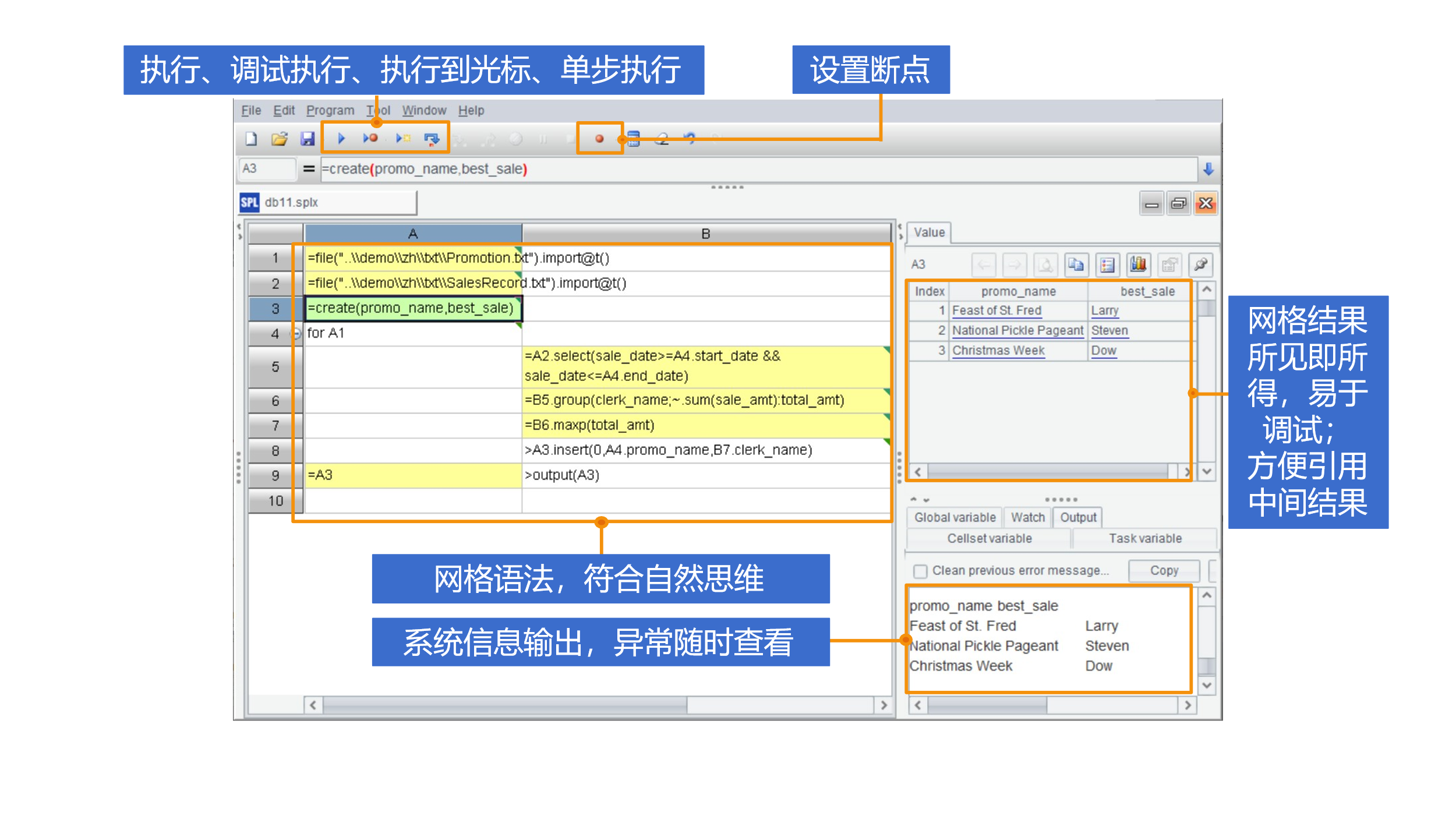
大数据支持
SPL 还支持大数据,内存装不装得下都能计算。
内存计算:
A |
|
1 |
=d:\smallData.txt |
2 |
=file(A1).import@t() |
3 |
=A2.groups(state;sum(amount):amount) |
外存计算:
A |
|
1 |
=d:\bigData.txt |
2 |
=file(A1).cursor@t() |
3 |
=A2.groups(state;sum(amount):amount) |
从上面的代码可以看到,SPL 外存计算的代码与内存计算几乎完全一样,不会额外增加工作量。
SPL 也很容易实施并行计算,只需要在串行计算代码上增加一个 @m 选项就可以,比 Java 不知道简单多少倍。
A |
|
1 |
=d:\bigData.txt |
2 |
=file(A1).cursor@tm() |
3 |
=A2.groups(state;sum(amount):amount) |
与 Java 应用无缝集成
SPL 采用 Java 开发,将 JAR 包嵌入应用即可使用,通过标准 JDBC 接口执行或调用 SPL 脚本,整体很轻,甚至可以在安卓上工作。
JDBC 调用代码:
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
有了轻量易集成的特点,SPL 可以无缝集成进主流 Java 框架,尤其适合在微服务框架内部充当计算引擎使用。
开放性
SPL 还具备良好的开放性,可以对接多种数据源并实时混合计算,很容易处理无库或多库场景。

不管什么数据源,只要能访问到,SPL 就都能读取并混合计算,啥都行。
数据库和数据库:
A |
|
1 |
=oracle.query("select EId,Name from employees") |
2 |
=mysql.query("select SellerId, sum(Amount) subtotal from Orders group by SellerId") |
3 |
=join(A1:O,SellerId; A2:E,EId) |
4 |
=A3.new(O.Name,E.subtotal) |
RESTful 和文件:
A |
|
1 |
=httpfile("http://127.0.0.1:6868/api/getData").read() |
2 |
=json(A1) |
3 |
=T(“/data/Client.csv”) |
4 |
=join(A2:o,Client;A3:c,ClientID) |
JSON 和数据库:
A |
|
1 |
=json(file("/data/EO.json").read()) |
2 |
=A1.conj(Orders) |
3 |
=A2.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) |
4 |
=db.query@x(“select ID,Name,Area from Client”) |
5 |
=join(A3:o,Client;A4:c,ID) |
解释执行热切换
SPL 是解释型语言,修改代码无需重启服务即可实时生效,天然支持不停机热切换,能更好适应需求多变的数据业务。
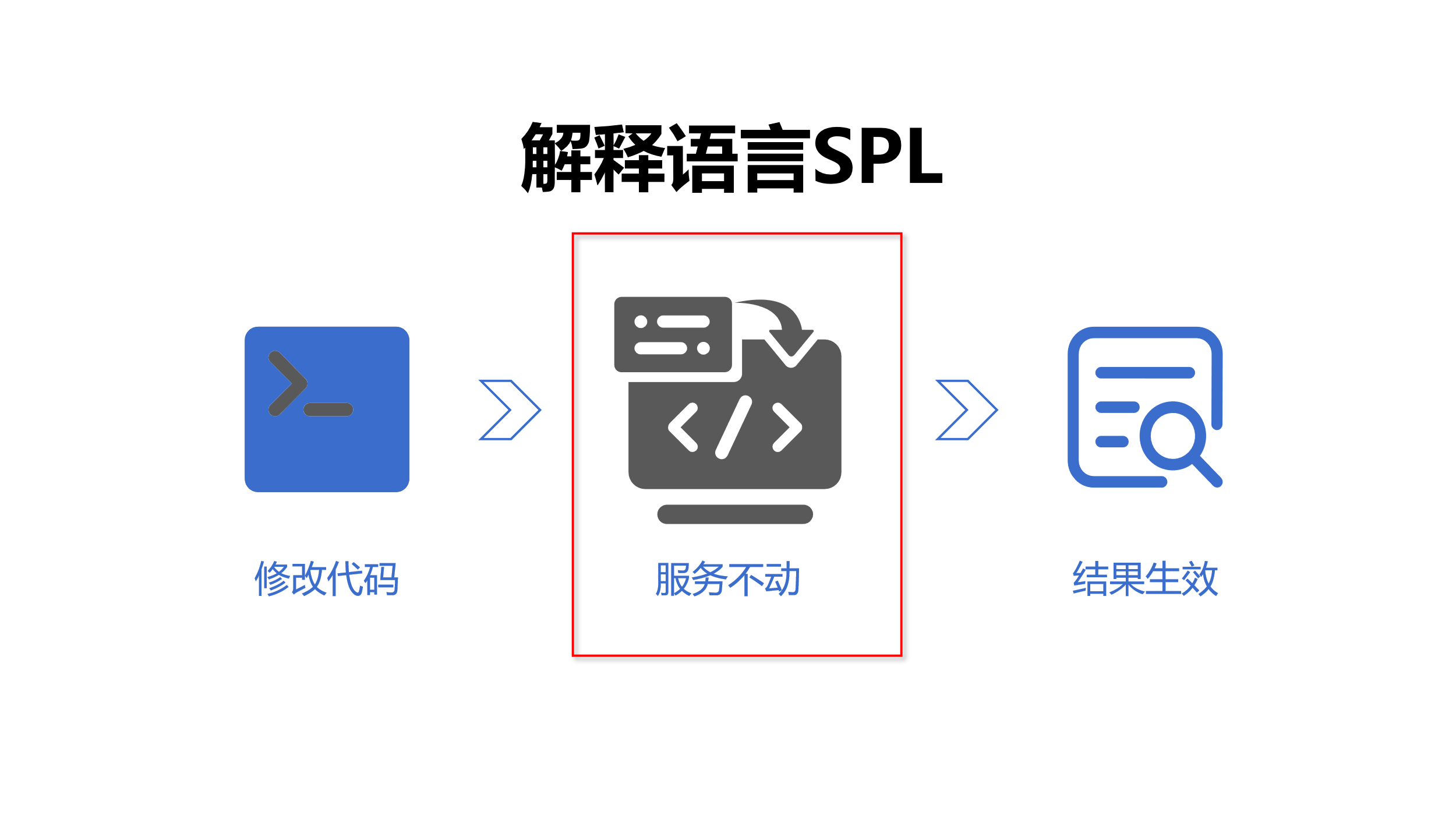
支持热切换还可以进一步独立计算模块,单独管理和运维,使用上更加灵活方便。
有了 SPL,可以大幅提升 Java 程序员的开发效率,同时获得架构上的优势。兼顾 Java 和 SQL 优点的同时,还能进一步简化计算、提升性能。
SPL 现已开源,欢迎下载: https://github.com/SPLWare/esProc


英文版