


Excel 后,我们需要怎样的数据分析软件
在现代商业环境中,数据分析已成为企业决策的重要工具。通过数据分析,企业可以更好地了解市场趋势、客户行为以及内部运营情况,从而制定出更科学的策略,提高竞争力。然而,数据分析并不是一项简单的任务,需要选择合适的工具和方法。
很多人认为 BI 软件是数据分析的首选,因为 Business Intelligence 这个词听上去和数据分析的关系很密切,而且 BI 软件通常具有流畅的交互性和炫丽的界面,看上去很适合做这项工作。然而,BI 工具在技术上已经被狭义化成多维分析,主要用于基于预设的数据立方体的汇总和展示。这在一些简单场景中的确有效,比如:企业成本过高时精确定位出是哪个时间段和哪些部门导致的。但面对复杂的业务问题时,BI 软件往往显得力不从心。比如,股票分析师猜测:满足某种条件的股票会更容易上涨?销售总监考虑:安排哪类销售员去对付难度大的客户会更有效?电商的数据分析员判断:以较低成本奖励符合某种特征的用户,就能获得高出平均值的收益。
这些问题都涉及到多步骤交互式计算,是传统 BI 工具无法应对的。
看具体例子:股票分析师根据自己的经验大胆做出猜测,符合某种预设条件的股票将来应该更容易上涨。为了验证自己的猜想,他先针对历史数据进行计算,找到符合这些条件的股票。再看这些股票的走势,如果大部分真如猜测一样上涨了,那就验证了猜测;如果猜测不对,那就调整猜测,改变约束条件,继续用历史数据验证猜测。经过对预设条件的多次迭代,最终使筛选出的股票达到较高的上涨概率和涨幅,就能得到一种规律性的结论,可以据此指导未来的股票交易。以上就是用多步骤交互式计算完整解决一个数据分析任务的过程, 本质上,就是基于历史数据反复猜测和验证,最终获得某种规律。
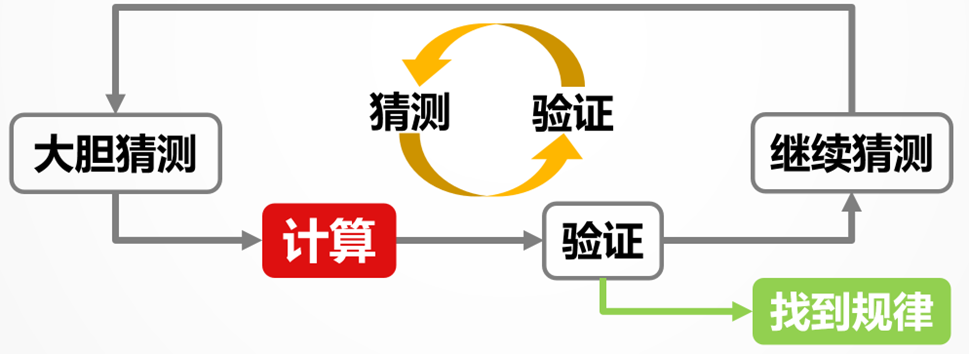
有经验的业务人员会提出猜测,剩下要做的是帮助业务人员验证猜测,也就是对历史数据做计算。这种计算的特点在于:不能事先设计过程,分析人员会根据上一步的结果临时决定下一步动作,也就是自由操纵计算过程。这就是交互式计算,非常类似于使用计算器。但与普通的数值计算器不同的是,数据分析需要计算的数据不是简单数值,而是批量的表格,也就是结构化数据。这种能力可以形象地称为表格型数据计算器。
Excel 就是这样一个表格型数据计算器。作为一种广泛使用的数据分析工具,Excel 具有良好的交互性,适合处理表格型数据,甚至,BI 的多维分析功能也包含在 Excel 透视表内了,只是界面的炫丽度和操作流畅性要弱一些。事实上,Excel 是业务人员最常用的数据分析软件。
但是,用 Excel 做数据分析久了,困扰也来了,有些工作用 Excel 很难完成。
数据太大跑不动。Excel 有容量限制,数据量一大就跑不动,几十万行就会很慢,超过百万行就直接没法工作了。
公式太难写不出。集合运算和分组后运算也是 Excel 不擅长的,比如,前面提到的“更容易上涨的股票”,验证猜测中的某一步可能是:找出股票连续上涨 5 天以上的区间,看看是否有某种规律。

这个任务会涉及有序分组并保持分组子集用于筛选,Excel 很难应对这些较复杂的数据计算。
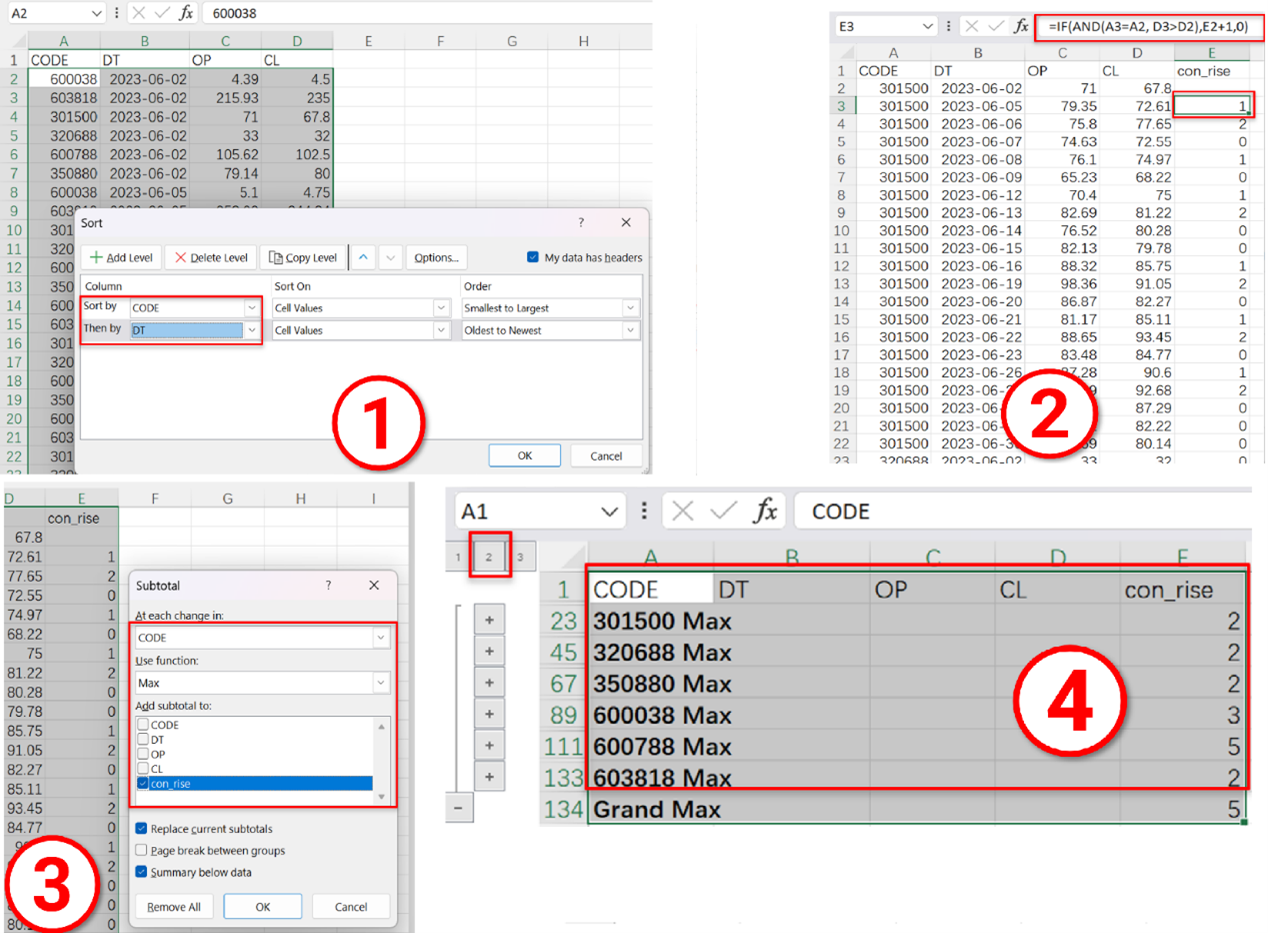
数据库可以解决 Excel 的问题吗?数据库应付稍大的数据量是没问题的,但环境准备复杂得多,而且 Excel 还要经过繁琐的入库才能分析。最重要的,SQL 难度经常远大于 Excel,比如计算每支股票最长连涨天数,用 SQL 要写成这样:
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT, SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
这种嵌套的 SQL 代码,专业程序员都很难写出来。
这个任务用 Excel 反而很简单。第一步按照股票代码、日期排序;第二步填写公式计算连续上涨天数;第三步分组汇总计算最长连续上涨天数;第四步收缩显示。直观四步搞定。
BI当然也指望不上。BI 本身用起来不难,但它解决大数据还是要依托数据库,同样还会面临环境准备的困难。而且,如前所述,狭义化成多维分析的 BI,计算能力简化到远不如 SQL 了,连刚才那个股票最长连涨天数都算不出,Excel 熟手会感到很受限。
看来,似乎只能借助于编程了,毕竟没有什么不能编程完成。
但是,大部分编程语言交互性差,离表格型数据计算器的概念较远,也不适合做数据分析软件。VBA可以增强 Excel 的计算能力,但对结构化数据支持力度太差,编程任务过于繁琐。而且 VBA 没有内置的大数据能力,只能自己实现,更加繁琐。
满大街培训班都在喊的Python总可以了吧?Python 的表格运算能力还行,但是写起来还是有点复杂,比如计算股票连涨天数要写成下面这样,要硬写循环。
import pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
此外,Python 也没有直接的大数据支持,也要自己写,这远远超出了 Excel 选手的能力范围。
而且,这些编程语言的交互性也不好,必须写完代码执行后才能看到结果,发现有局部错误也要改正后再从头执行,这远没有所见即所得的 Excel 顺手。
这些看似热门的编程语言并不是好选择,还有什么别的吗?
还有esProc Desktop,后 Excel 的数据分析神器。
esProc Desktop 是一个表格型数据计算器,提供了面向结构化数据的编程语言 SPL,开发环境有极强的交互性,可以方便高效地处理大数据,可以增强 Excel 的计算能力,极大地降低了复杂计算的难度,是数据分析人员的理想工具。
所见即所得的强交互计算能力
SPL 的网格编程就像是写 Excel 公式,业务人员也能轻松掌握。格名就是天然的变量名,可以直观引用之前的计算结果。SPL 代码可以单步执行,随时在右侧查看计算结果,结构化数据自动以表格形式展现,特别适合多步骤的交互式计算。
以前面的股票连涨区间为例,SPL 代码分为五步:读文件、排序、有序分组、过滤、合并,交互过程可以清晰地呈现在格子里。
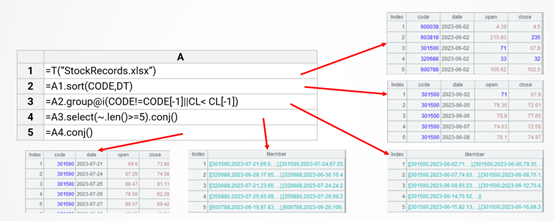
每步都可以独立执行,有错误时可以只修改局部代码重新执行这一句再观察结果。
远超 Python 的表格计算能力
SPL 有强大的表格运算能力,代码比 Python 简单很多,既具备 Excel 的简单性,又能解决 Excel 难算的任务,真的做到既要又要。比如计算每支股票最长连涨天数,简单三行即可搞定。
A |
|
1 |
StockRecords.xlsx |
2 |
=T(A1).sort(DT) |
3 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
更复杂的任务:求每 7 天中连续 3 天活跃的用户数。Python 写起来很罗嗦:
df = pd.read_csv("../login_data.csv")
df["ts"] = pd.to_datetime(df["ts"]).dt.date
grouped = df.groupby("userid")
aligned_dates = pd.date_range(start=df["ts"].min(), end=df["ts"].max(), freq='D')
user_date_wether_con3days = []
for uid, group in grouped:
group = group.drop_duplicates('ts')
aligned_group = group.set_index("ts").reindex(aligned_dates)
consecutive_logins = aligned_group.rolling(window=7)
n = 0
date_wether_con3days = []
for r in consecutive_logins:
n += 1
if n<7:
continue
else:
ds = r['userid'].isna().cumsum()
cont_login_times = r.groupby(ds).userid.count().max()
wether_cont3days = 1 if cont_login_times>=3 else 0
date_wether_con3days.append(wether_cont3days)
user_date_wether_con3days.append(date_wether_con3days)
arr = np.array(user_date_wether_con3days)
day7_cont3num = np.sum(arr,axis=0)
result = pd.DataFrame({'dt':aligned_dates[6:],'cont3_num':day7_cont3num})
SQL 更加冗长:
WITH all_dates AS (
SELECT DISTINCT TRUNC(ts) AS login_date
FROM login_data),
user_login_counts AS (
SELECT userid, TRUNC(ts) AS login_date,
(CASE WHEN COUNT(*)>=1 THEN 1 ELSE 0 END) AS login_count
FROM login_data
GROUP BY userid, TRUNC(ts)),
whether_login AS (
SELECT u.userid, ad.login_date, NVL(ulc.login_count, 0) AS login_count
FROM all_dates ad
CROSS JOIN (
SELECT DISTINCT userid
FROM login_data) u
LEFT JOIN user_login_counts ulc
ON u.userid = ulc.userid
AND ad.login_date = ulc.login_date
ORDER BY u.userid, ad.login_date),
whether_login_rn AS (
SELECT userid,login_date,login_count,ROWNUM AS rn
FROM whether_login),
whether_eq AS(
SELECT userid,login_date,login_count,rn,
(CASE WHEN LAG(login_count,1) OVER (ORDER BY rn)= login_count
AND login_count =1 AND LAG(userid,1) OVER (ORDER BY rn)=userid
THEN 0
ELSE 1
END) AS wether_e
FROM whether_login_rn),
numbered_sequence AS (
SELECT userid,login_date,login_count,rn, wether_e,
SUM(wether_e) OVER (ORDER BY rn) AS lab
FROM whether_eq),
consecutive_logins_num AS (
SELECT userid,login_date,login_count,rn, wether_e,lab,
(SELECT (CASE WHEN max(COUNT(*))<3 THEN 0 ELSE 1 END)
FROM numbered_sequence b
WHERE b.rn BETWEEN a.rn - 6 AND a.rn
AND b.userid=a.userid
GROUP BY b. lab) AS cnt
FROM numbered_sequence a)
SELECT login_date,SUM(cnt) AS cont3_num
FROM consecutive_logins_num
WHERE login_date>=(SELECT MIN(login_date) FROM all_dates)+6
GROUP BY login_date
ORDER BY login_date;
SPL 代码要简短易懂得多,普通业务人员也能轻松掌握:
A |
|
1 |
=T("login_data.csv") |
2 |
=periods(date(A1.ts),date(A1.m(-1).ts)) |
3 |
=A1.group(userid).(~.align(A2,date(ts)).(if(#<7,null,(cnt=~[-6:0].group@i(!~).max(count(~)),if(cnt>=3,1,0))))) |
5 |
=msum(A3).~.new(A2(#):dt,int(~):cont3_num).to(7,) |
天然的大数据支持
SPL 提供了原生的大数据处理能力,支持游标以应对超出内存容量的外存计算,内外存计算代码几乎一致,不会额外增加工作量。比如,计算每支股票最长连涨天数,只要把 import 函数改为 cursor。
A |
|
1 |
StockRecords.txt |
2 |
=file(A1).cursor@t().sortx(CODE,DT) |
3 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
SPL 支持基于线程的并行计算,充分利用多核 CPU。比如,找出股票连涨超过 5 天的区间,只要增加一个 @m 选项,性能直接起飞。
A |
|
1 |
StockRecords.txt |
2 |
=file(A1).cursor@tm().sortx(CODE,DT) |
3 |
=A2.group@i(CODE!=CODE[-1]||CL< CL[-1]) |
4 |
=A3.select(~.len()>=5).conj() |
内嵌 Excel 的增强插件
esProc Desktop 提供了 XLL 插件,用户可以在熟悉的 Excel 环境中,利用 SPL 的强大计算能力,在 Excel 内直接写 SPL 公式,同时发挥 SPL 和 Excel 优势。比如连涨区间的计算,在 Excel 里写一句 SPL 代码就能算完。
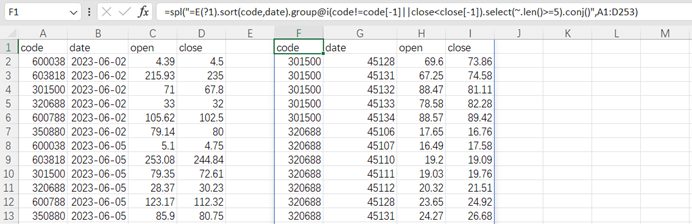
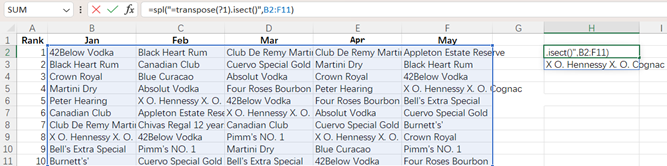
再比如:找出每个月都能进 top10 的明星产品,Excel 做交集很麻烦,SPL 集合运算要强大得多,简短的公式可直接获得结果。
esProc Desktop 现在可以免费使用,还有图书、课程、Excel 例程集等丰富的资料,详见https://www.raqsoft.com.cn/desktop-download


英文版