


* 分类下两列一组统计
表格 A 列是分类,后面是 2N 个 key-value 列
A |
B |
C |
D |
E |
F |
G |
|
1 |
Country |
Label1 |
Count1 |
Label2 |
Count2 |
Label3 |
Count3 |
2 |
US |
A |
10 |
B |
9 |
C |
8 |
3 |
US |
D |
9 |
C |
8 |
A |
7 |
4 |
US |
C |
8 |
D |
7 |
B |
6 |
5 |
US |
A |
7 |
C |
6 |
B |
5 |
6 |
CA |
A |
10 |
B |
9 |
C |
8 |
7 |
CA |
D |
9 |
C |
8 |
A |
7 |
8 |
CA |
C |
8 |
D |
7 |
B |
6 |
9 |
IN |
A |
10 |
C |
9 |
B |
8 |
10 |
IN |
D |
9 |
A |
8 |
B |
7 |
11 |
IN |
A |
8 |
D |
7 |
B |
6 |
需要对分类、key 分组,对 value 求和,结果是 3 列。注意,计算结果的分组列要保持原始顺序。
A |
B |
||
1 |
Country |
Label |
Total |
2 |
US |
A |
24 |
3 |
US |
B |
20 |
4 |
US |
C |
30 |
5 |
US |
D |
16 |
6 |
CA |
A |
17 |
7 |
CA |
B |
15 |
8 |
CA |
C |
24 |
9 |
CA |
D |
16 |
10 |
IN |
A |
26 |
11 |
IN |
C |
9 |
12 |
IN |
B |
21 |
使用 SPL XLL,输入公式并下拉:
=spl("=E(?).groupc@r(Country;;Label,Count).groups@u(Country,Label;sum(Count):Total)",A1:G11)
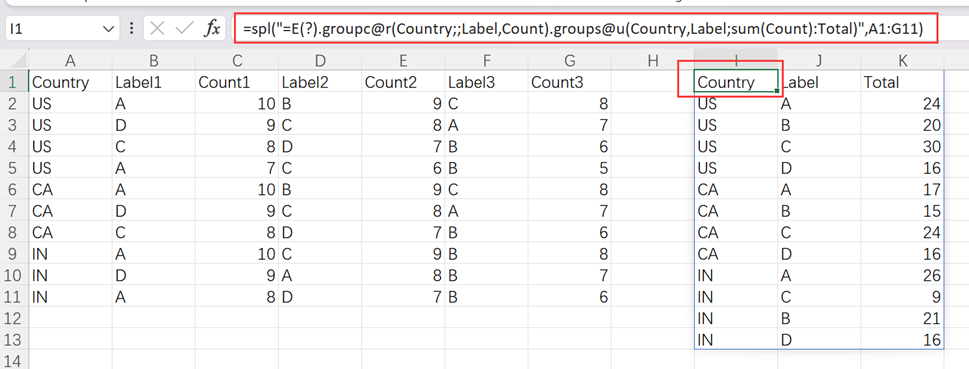
函数 E 按表格形式读入数据。groupc@r 以相同列数为组进行列转行,groups 分组汇总。
https://www.reddit.com/r/excel/comments/1cz218j/how_can_i_summarize_a_table_with_location/


英文版
大佬们,如果把原始数据换一种格式布局,并不是以 Label1,Count1,…Labeln,Countn 这样的顺序出现,如下所示:
此时,结果还是要以 Label,Count 的形式输出,那序表.groupc@r 要如何写?注意到函数的 2 参是表的字段,2 参缺省时表示除 1 参之外的所有字段,也可以一个一个写出来,所以,我想着 2 参在写的时候应该可以随意,不用管次序,但写成这样之后报错了:
2 参中的字段名或者 #n 的形式不能随意调换次序。即使按源数据的格式,2 参也不能随意写,比如我只想要其中某几对:
但是写头两列 #2,#3 能出结果,写#3,#2 又不行:
以上写法换成序列.groupc@r 都没问题,此时 2 参中是序列,灵活度大一点。
麻烦大佬们得空时看看,给予指导帮助,谢谢🙏 🙏
多谢,实现的是有点问题,刚改了一下,提交到 github 上了。
不用谢,大佬客气了🙏
要感谢 SPL,简洁易用、高效可靠。
Omnipotent & Light-Years Ahead!👍 👍
To: @leavedy
Cc: @279400248
大佬,不好意思又来打扰你,见谅🙏
我还是纠结于 P.groupc(;; 新字段) 中 3 参新字段在缺省时自动展开成序号的问题,你也跟我讲了设计 3 参自动展开时的缘由,我想来想去,仍然觉得默认成序号作为字段名并不实用,如果该表作为中间结果,字段名是什么都无所谓,如果作为最终结果呈现,序号字段名肯定不常用,最终还是要手动写出三参,或者通过构造字符串用宏解析。构造字符串时多余的字段会扔掉,这个超级好。但我觉得默认的序号字段似乎没起到默认的作用,因为这个默认序号字段并不实用,会被重新指定的几率很大,官方可不可以默认一个常用的格式,比如:
1、2 参指定了字段名,3 参省略的时候,可不可以自动生成 Lable_1,Count_1…这样的格式字段名。正好是 2 参指定字段跟序号生成的一个叉乘序列;
2、同理,2 参省略,且 3 参省略时,按照除一参之外的字段跟序号生成叉乘序列作为字段名;
3、如果 2 参只有 1 个参数 X,3 参省略时,生成 X_1,X_2…. 这样的格式。
我个人愚见,默认一个常用的格式会比默认一个序号字段要实用一些,至少会比序号字段实用且常用。至于其它的格式,只能后续由用户自己写字符串了。
我不是故意找茬,因为序号字段 _2,_3…_n 确实很少用,与其占用了一个默认不实用,可否默认一个常见实用的。
以上想法,恳请大佬得闲时考虑一下是否可行。谢谢🙏
这个是左右都不合适,有人要 _,有人不要,这里再弄个匹配式也很烦。哪天想出好办法再说了,先自己拼出字段名。
感谢老贼回复🙏
3 参拼字符串也方便,leavedy 大佬教了我几个写法,非常好,我学到了。
默认字段展开还请您方便的时候再想想,哈哈,拜托🙏
@leavedy
大佬,早上好😄 关于 groupc 我想到了一些东西,麻烦大佬看看:
1、函数文档中对 A.groupc(g;v) 中 g 的描述是这样的,g 是分组依据,是 A 成员序列中的的某个成员。这里的“某个成员”一度让我误解为只能是一个条件,结合函数语法 1 参 g 也没有写成 g1,…gi 这种多条件分组的形式,所以我还以为不能多条件分组。实际上是可以多条件分组的,经过你指导,多条件时,g 要写成序列的形式 [~1,~2,…],或者其它能产生序列的写法。 所以,函数文档可不可以对此时的 g 描述的更详细一点? 比如以下例子,我把索引号加入分组条件 g 时,写成序列的形式,得到了预期的结果,很好用:
2、上述是针对序列的序列 A.groupc 时的写法,既然序列的序列可以这样写引入索引号,那针对序表的 P.groupc 是不是也能实现在 1 参中加入跟源序表完全不同的字段?还是拿上述例子写,如下图所示,可以看到 1 参也能引入索引号或者其它跟源表完全不一样的字段,但此时,2 参必须要显式指定源表中的字段,不能缺省。
根据 P.groupc() 的语法说明,2 参省略时,会被默认为除了一参之外的所有字段,那如果在一参中加入了一些不相关的字段,2 参缺省时可不可以也默认为除了 1 参之外的所有有效字段?如果源表有很多字段,要一个一个写出去,会略显麻烦。
3、groupc 的 1 参其实是一个分组条件,这样理解应该不会错吧?既然是分组,那 groupc 可不可以有一些跟 group 一样的选项,比如,groupc@o,groupc@i…。如果是这样的话,那 1 参得支持运算,A.groupc() 灵活度好一些,序列应该可以运算,P.groupc 的 1 参是字段名,还跟 2 参有关系…这点可能是我想多了,但肯定也有一些应用场景。
上述 3 点,恳请大佬得闲时帮忙看看,谢谢🙏
1、我会跟产品部反应一下
2、已修改
3、group 的许多选项是为了提速的,groupc 一般是用于小数据量的,没必要用那些提速选项了。
懂了,谢谢大佬🙏 🙏
有些应用场景等我实战碰到了再跟大佬汇报情况哈
Have a nice day😄
@leavedy
大佬,不好意思又来麻烦你,对于 groupc@r,是否存在两种天然索引号,一种是来自于源表的行序号,这个用 #就能获取,另一种是源表的列序号,这个列序号能不能搞出来?如下图所示,其中的列序号是通过添加一步用 seq 算出来的,不是天然存在的:
换成 news 函数时,可以在同一个函数内获取到两种序号,如下:
所以,groupc@r 里是不存在天然列序号的,对吧?比如想直接得到以下结果,不再 run 一遍:
这种的应该写成:=E(?).groupc@r(名字,#: 行序号;1, 链接 1,2, 链接 2,3, 链接 3,4, 链接 4; 列序号, 链接)
谢谢大佬🙏
这样枚举式地写出跟我想的不一样,是我钻牛角尖搞复杂了😂
总想着在一个函数里完成,要回归正常,让 groupc 干他该 (能) 干的活。