


(已解决) 集算器插件里序表比序列占用内存高?
大佬们,我在 EXCEL 里使用集算器插件时遇到一个现象,生成一堆数量不小的最多只有 4 行的序表,合并后 80 万行 4 列,返回结果时变成了 null,要么就是 Excel 无响应。当把这些序表用 E@b()或者 array() 转换成二层序列后,同样是 80 万行的结果,很快就能出来结果。难道生成中间结果的序表对象比序列对象占用内存高?不知道这样描述是否正确。我尝试了一些方法,比如把文件发给官方测试,测试人员说他那边正常,我又重新安装了集算器,无奈本机(WIN8G 内存,分配给 JVM 大概 6G 左右)还是跑不出结果。现在只剩下卸载 EXCEL 重装后再测试了。这跟 EXCEL 有没有关系?我用的是 OFFICE365BETA 版本,就是每周会更新的版本。
情况是这样的,在 EXCEL 中有这么一个处理需求,如下图所示,需要把左边的文本串变成右边的表格形式,文本串中的每一行都是以一个字母加冒号加数字组成的类似键值对的形式:
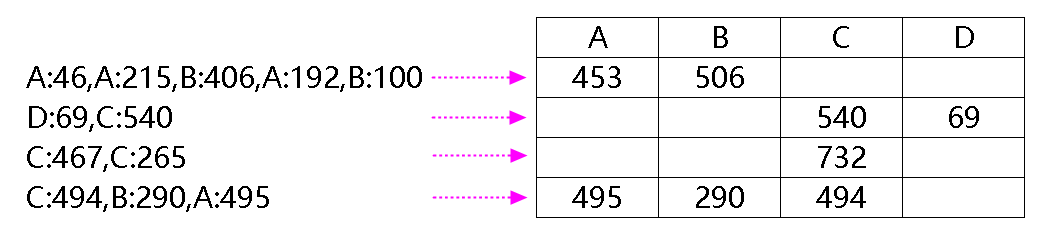
处理后,相同名称的键值要相加。以第一行为例:A:46,A:215,B:406,A:192,B:100
其中:A = 46+215+192 = 453 , B = 406+100 = 506
每一行都需要横向展开,列名并不限于 A、B、C、D,可能还有其他字母,也就是说表头是动态的。
常规思路,下意识的做法就是把文本串按每一行,先用逗号拆,再用冒号拆,拆成一个二层序列后,再用 group 聚合,合并同类项,此时每一行变成一个序表,最后把所有序表合并后再用 pivot 行转列,生成动态表头。如下所示:
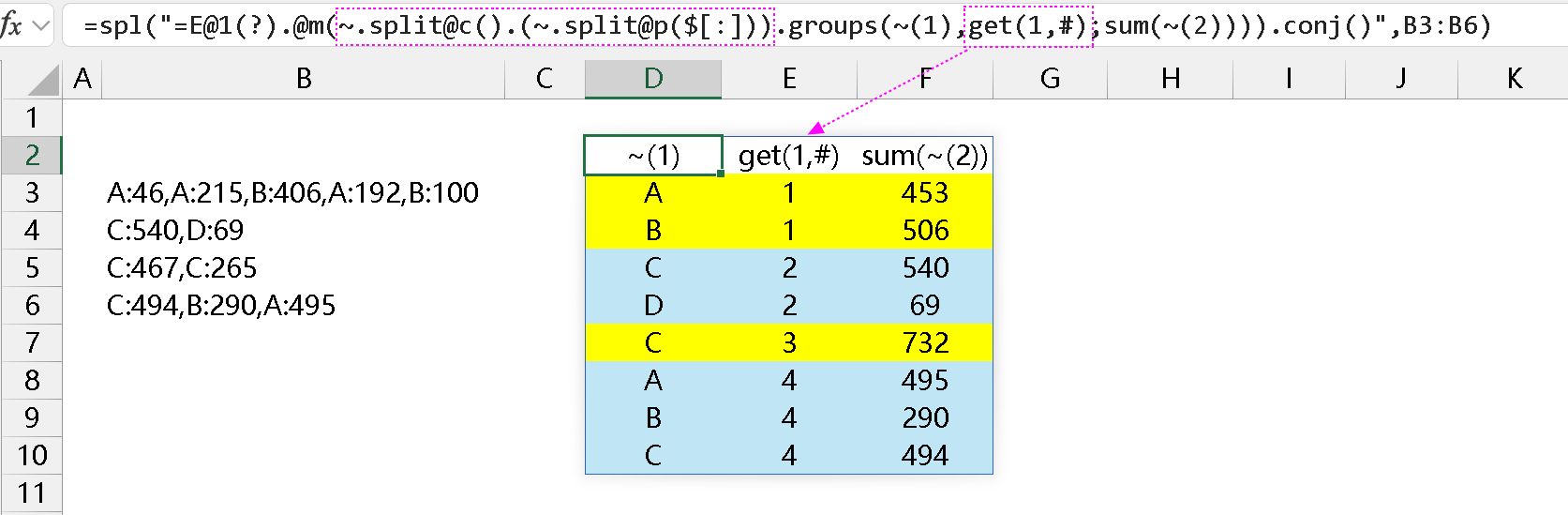
上述写法中,存在嵌套,看着会有点眼花,拣出主要的说一下:
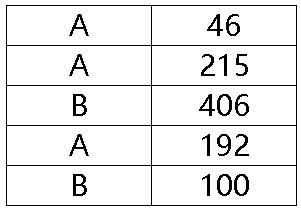
1、split 两次拆分部分:~.split@c().(~.split@p($[:])),用左侧第一行举例拆分得到的是如下所示的二层序列:
2、拆分后对这部分二层序列用 groups 聚合:xxx.groups(~(1),get(1,#);sum(~(2))),聚合时添加了 get(1,#),这一部分的用途是为了引入文本串所在的索引,便于后续 pivot 时使用。聚合之后的序表是这样的:

整体结果请观察上边标有颜色的那个截图。后续的 pivot 这里就不写了。
我们先不管这个写法的优劣,事实上这个写法也确实存在问题,我请教了 leavedy 大佬,这种生成中间结果为序表的,如果一旦数据量大,比如把源文本串序列扩大 10 万倍,这样一来生成的中间序表会很多,自然会消耗很多内存,导致爆栈。这个我能理解,后来在 leavedy 大佬指点下,我换了写法,确实很快就能出结果。让我困惑的不是写法,而是中间过程生成序表时和把序表变成序列后情况完全不一样,比如把数据源扩大 10 万倍之后,继续用上述序表写法,就跑不出结果,代码如下:
=spl("=E@1(?*100000).@m(~.split@c().(~.split@p($[:])).groups(~(1),get(1,#);sum(~(2)))).conj()",B3:B6)
奇怪的是,只要把 groups 后的序表变成二层序列,结果就能很快出来。做法很简单,用 E@b()或者 array() 就成:
1、用 E@b() 序表转序列
=spl("=E@1(?*100000).@m(E@b(~.split@c().(~.split@p($[:])).groups(~(1),get(1,#);sum(~(2))))).conj()",B3:B6)
2、用 array().m(2:) 序表转序列
=spl("=E@1(?*100000).@m(~.split@c().(~.split@p($[:])).groups(~(1),get(1,#);sum(~(2))).array().m(2:)).conj()",B3:B6)
以上所有写法,不管写法优劣,在集算器 IDE 均使用正常,都能跑出结果来。唯独在 EXCEL 插件中使用时出现了意料之外的情况。我问了多方面,也向插件大佬 ordat 请教了,他那边测试都是正常的,这让我困惑。本机使用环境如下:
1、集算器最新版,最新 esproc-bin 包,最新 esproc-ext 包;
2、MAC 机 WIN 虚拟系统,可用内存 8G,JVM 安排了 6G;
3、EXCEL 用的是 OFFICE365.
恳请大佬们有空时帮忙测试一下,给予帮助解惑,EXCEL 文件会附在文末。
那较好的写法是什么,以下是按我自己理解写的 (可能理解有偏差,并没有写出大佬所说的精髓):
1、经 leavedy 大佬指点,我按自己的理解写了一个,中间过程不用事先 groups 聚合成表,因为 pivot@s 也能聚合,只要标识好每一串文本对应的索引号就行,如下:
=spl("=E@1(?*100000).@m(~.split@c().(~.split@p($[:])|get(1,#))).conj().pivot@s(~(3);~(1),sum(~(2))).alter(;#1)",B3:B6)
2、或者动态表头,用 json@t(json()),原本以为转 json 字符串会慢,实际上这个 json@t()表现远超出预期。这个写法也是之前一开始的思路,中间生成了 groups 后的序表,但经过 E@b() 序表转序列和 E@p()序列转序表之后,变成只有一行的表了。估计是得益于 E@b() 序表转序列这一操作。
=spl("=json@t(json(E@1(?*100000).(E@p(E@b(~.split@c().(~.split@p($[:])).groups(~(1);sum(~(2)))))).conj()))",B3:B6)
最后附上文本串 (复制可用于集算器 IDE 测试):
A:46,A:215,B:406,A:192,B:100
C:540,D:69
C:467,C:265
C:494,B:290,A:495
还有 excel 文件,测试时只需把语句中?*1 变成?*100000 即可,或者烦请大佬们复制上述提到的 spl 语句测试。为安全起见,文件中都是?*1,并未扩大到 10 万倍。

附件在此↓:


记录数少的序表占用的内存要比序列的序列大的,序表的成员变量多于序列,序表有数据结构、索引这些信息,数据结构上还有主键信息,记录数少的时候这些信息占用的空间相对于数据本身占用的空间就会显得非常大。
谢谢大佬解惑,正如你之前说的,中间过程生成的大量序表内存占用过高了,groups 之后还有主键的信息,而序列相对而言就少了这部分信息,内存占用少了。
我可能是钻牛角尖了,我觉得 spl xll 是不参与计算的,那正常集算器 IDE 里跑多快,excel 插件里也应该有相应的一个表现,不至于跑不出结果,我纠结于这个。 而事实上,症结所在还是内存不够,之前别的机器测试的时候是 16G 内存,而本机只有 8G 内存。 目前,@oradt 已经帮忙解决了插件里跑不出结果的问题了。
@oradt 谢谢大佬帮忙解决了我的强迫症🙏 😂 纠缠了你好几天,我是真的不懂内存硬件配置,见谅🙏