


(已解决) xjoinx 参数为同一个游标时的问题
1、帖子中用到的数据来自集算器自带的 demo;
2、xjoinx 函数的官方链接: http://d.raqsoft.com.cn:6999/esproc/func/xjoinx.html
根据函数语法 xjoinx(csi:Fi,xi,..;…),参数 csi 为游标时,必须为可回转的单路游标,也可以是序表。正常来说,csi 应该是属于不同的游标或者不同的序表,但也有特殊情况,比如,自己跟自己叉乘,也就是说 xjoinx 所有的参数 csi 是同一个游标或者序表。当参数是同一个序表时,没有啥问题,过滤条件随意写。当参数是同一个游标做叉乘时,就会跟同是序表的结果有出入。这个应该跟游标的只遍历一次特性有关,且文档也说了,必须是可回转的单路游标。那在 xjoinx 函数计算时,如何才能让游标自动回转,或者有没有人工干预的方法使其在函数执行的过程中按需要回转。举例对比如下:
源数据的结构如下所示:
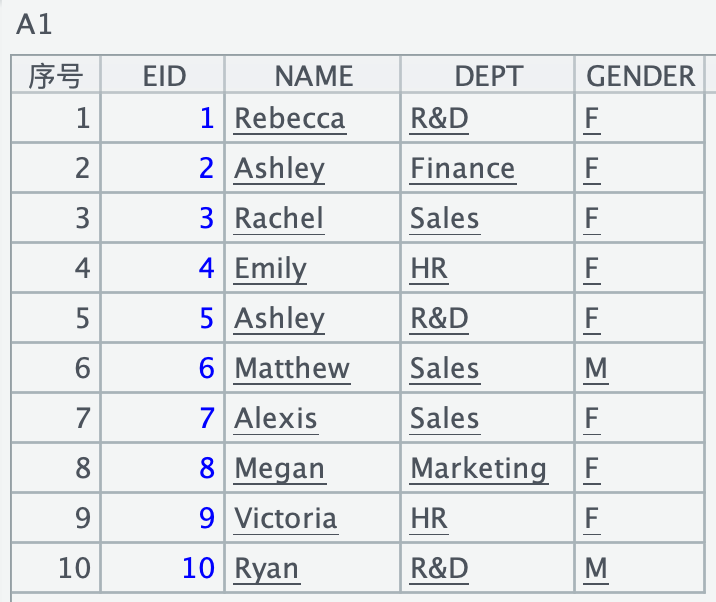
1、同一个序表,用 xjoinx 自己跟自己叉乘:
| A | |
| 1 | =demo.query@x("select top 10 EID,NAME,DEPT,GENDER from EMPLOYEE") |
| 2 | =xjoinx(A1:a,GENDER=="M";A1:b, GENDER=="M") |
| 3 | =A2.fetch() |
A3 中的结果显示如下:
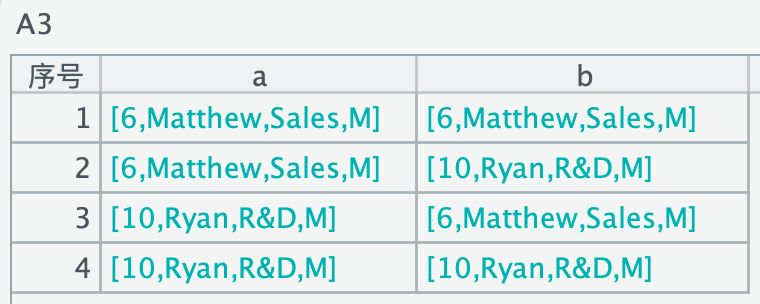
选出 GENDER 等于 M 的做叉乘,观察源数据可知,这个结果是正确的。
此时把序表换成游标,过滤条件写在同样的位置:
| A | |
| 1 | =demo.cursor("select top 10 EID,NAME,DEPT,GENDER from EMPLOYEE") |
| 2 | =xjoinx(A1:a,GENDER=="M" ;A1:b,GENDER=="M") |
| 3 | =A2.fetch() |
此时 A3 中 fetch 出来的结果就跟上述不一样了,少了两条:

此时,如果把第一个游标的过滤条件换个位置,写到第二个过滤位置处,发现结果为空。但在参数为序表时,过滤条件换位置,出来的结果是一样的。以下语句运行结果为空:
| A | |
| 1 | =demo.cursor("select top 10 EID,NAME,DEPT,GENDER from EMPLOYEE") |
| 2 | =xjoinx(A1:a;A1:b,a.GENDER=="M" && GENDER=="M") |
| 3 | =A2.fetch() |
再比如,把过滤条件写复杂一点,依然是同一个游标自己叉乘,以下语句没有结果:

如果上述语句中的 A1 是序表,是能出结果的。
所以,同一个游标自己跟自己叉乘是不是属于不正规用法,有没有办法可以写出结果来?
恳请大佬们得闲时给予指导帮助,谢谢🙏


xjoinx 的参数不能用同一个游标,需要定义成多个游标来使用。
这跟多个线程从同一个游标取数一样,每个线程只能取到一部分数据,所有线程取到数据合起来才是完整的数据。
麻烦大佬了🙏
学艺不精,我再去看看文档。
不行,还得麻烦大佬看看,我把原始文件和 splx 打包成了附件:
zip
如下图所示,游标经过了二次处理,此时 xjoinx(游标或序表;序表) 才能出结果,xjoinx(游标或序表;游标) 不会出结果,也就是说本例中 xjoinx 的第二个位置的表必须是序表,不知道哪里没搞对:
附加了 group 操作的游标重复使用时有个 bug,已修改提交到 git 上了。
谢谢大佬🙏 …我多问两句哈😄
1、游标是不能复制的吧,比如 cs.derive() 是不会产生一个不同于源 cs 的另一个 CS 吧。
2、这种叉乘有没有优化方法?此例的意思是,一堆客户买了一些商品,要求出哪些商品是这个客户买了但其他客户没有买的。叉乘一一配对。
xjoin 中过滤条件,一个是客户自己不跟自己比较,两个比较客户之间相同的商品数量要至少两样才符合,然后再求出补集, 求补集的时候又是叉乘。
此处 xjoin 和 fjoin 相差无几,跑出结果的时间平均在 6 秒左右,写法上都是硬搞,但比 SQL 跑的快,在 DuckDB 里跑 SQL 跑了 15 秒,也有其它数据库跑不出来结果。
1、游标不能被复制,derive 属于游标的“延迟计算”函数,这类函数返回的是源游标,不会产生新游标。从游标取数时,游标会把取到的数据依次传给游标上定义的“延迟计算”函数,最后把“延迟函数”的计算结果返回。
2、没想到好的计算方案
这种两两比较的只能是叉乘方式,数据量大也只能来回读。
能想的办法只能是工程方面的,比如是否能把购买的商品做成对位序列,这样做交集可以用位运算。但商品数太多就不行了。或者购买商品号是有序的,算差集的时候可以用归并。还有,算到空集时就立即结束,不要再读下去了(这个 xjoin 直接写不出来了,要用 for)。
谢谢老贼关注指点🙏 谢谢 leavedy 大佬🙏
我再琢磨琢磨怎么玩,一开始拿到题的时候直觉就是叉乘,预计不会秒出。但 xjoin 也是牛的很,能写条件过滤做剪枝,表现远超预期,后续计算中的再一次叉乘展开,实在是没有办法。不过,此例集算器的表现 (平均 6 秒) 已经相当牛了,某些流行数据库跑 SQL 跑不出来结果。
虽然是个小题,从中还是学到了不少东西。
具体这个题,如果结果集及所有的商品并集在内存中可以放得下,大概也可以遍历一次算出来。
设 A1, A2, …,An 是每个客户的商品集合。
R 就是结果。
这样遍历一次就能算出来,计算量也少一半左右。但要求内存能把 R 和 ALL 都放下。
谢谢老贼指导,您有心指点,无奈我悟性不够,始终没有领会您的意思,只好再次打扰。麻烦您有空有心情的时候再看看🙏
简化一下题目,3 个客户 a,b,c 各自买了商品,比如 a 购买了 1、2、3 号商品,b 购买了 2、3、4 号商品,c 购买了 1、2、3、5 号商品,如下所示:
现在 a,b,c 之间做叉乘,实际上就是 N 取 2 的组合,配对得到 3 组:
1、[a:{1,2,3},b:{2,3,4}]
2、[a:{1,2,3},c:{1,2,3,5}]
3、[b:{2,3,4},c:{1,2,3,5}]
此处为了方便,正好都满足每一组配对的交集个数都是至少 2 个,比如第 1 组中的 a^b=[2,3],如果组中的交集数量小于 2 个就不满足配对要求。这样配对完成后,再从每一组中求出两个差集 a\b 和 b\a,比如 a\b=1,返回 [b,1],表示客户 b 没购买的商品;同理 b\a=4,返回[a,4] 表示 a 没有购买的商品。接下来第二组要返回 [a,5],因为 c 买了 a 购买过的所有商品,所以此时[c,null] 在结果中不出现,同理第三组返回[b,1],[b,5],[c,4],最终结果为 3 组结果去重后的结果,得到[a,4],[a,5],[b,1],[b,5],[c,4]
我理解错了意思 “要求出哪些商品是这个客户买了但其他客户没有买的”
这句话,我理解是找出每个客户独有购买的商品(他买过而其它人没买过,就他的商品集和其它人的商品集的差集),这样每个客户只有一个结果集。总共是 n 个结果集,也就是结果集的规模是 n。
现在的意思似乎是两两之间都有两个结果集,总共会有 n*(n-1) 个结果集,这是平方级的了,也只能平方级的算法了,复杂度上不会降低了,能想的办法只是工程上让每一步算得快一点。
😄 是我一开始没描述清楚🙏 🙏
换了一个写法,几乎是换汤不换药,没 xjoin 直观,执行耗时跟之前的 xjoin 差不多,本机 7 秒左右。
之前用 xjoin,再用 news 展开,还能快一两秒😂