


(已解决) 集算器中 record 的复制和字段删除
取出一条 record,如何才能使其 immutable? 在集算器中,表或者集合具有离散性,从源表中取出某些记录后会依然跟源表保持关系 (mutable)。比如,有这么一个序表 b=[{a:1,b:2,c:3},{a:11,b:22,c:33}],取出第 2 条记录进行修改后,源表也会同时修改,=b(2).modify(111,222)。
但有时候,希望只是单纯的修改取出的记录,不同时修改源表,也就是 immutable。此时只要能复制出这条记录,后续对其的修改就不会对源表产生影响。但在集算器中,应该没有对 record 复制的方法,不像序列,序列的复制简单一点,比如 A.m(:) 或者 A.(~) 这样就把序列 A 复制了一遍,变成了另一个跟 A 没有关系的序列。
对 record 的复制没有直接的方法,略费周折,要先变成排列,再用 derive 转序表,用序表方法修改后,再用 (1) 深化出来就相当于复制了一遍 record,转成 spl 语句就是:
[record].derive().modify()(1),此时 modify 就不会同时修改源表了。
同样,如果要删除 record 中的某个字段而不对源表产生影响,也只能转序表后再删:
[record].derive().alter(; 字段名)(1)
为什么会有复制 record 这样的用法?情况是这样的,经常会碰到这样的表格,一个单元格里塞了很多条数据,然后要把这个单元格里的数据拆分到每一行,比如以下例子:
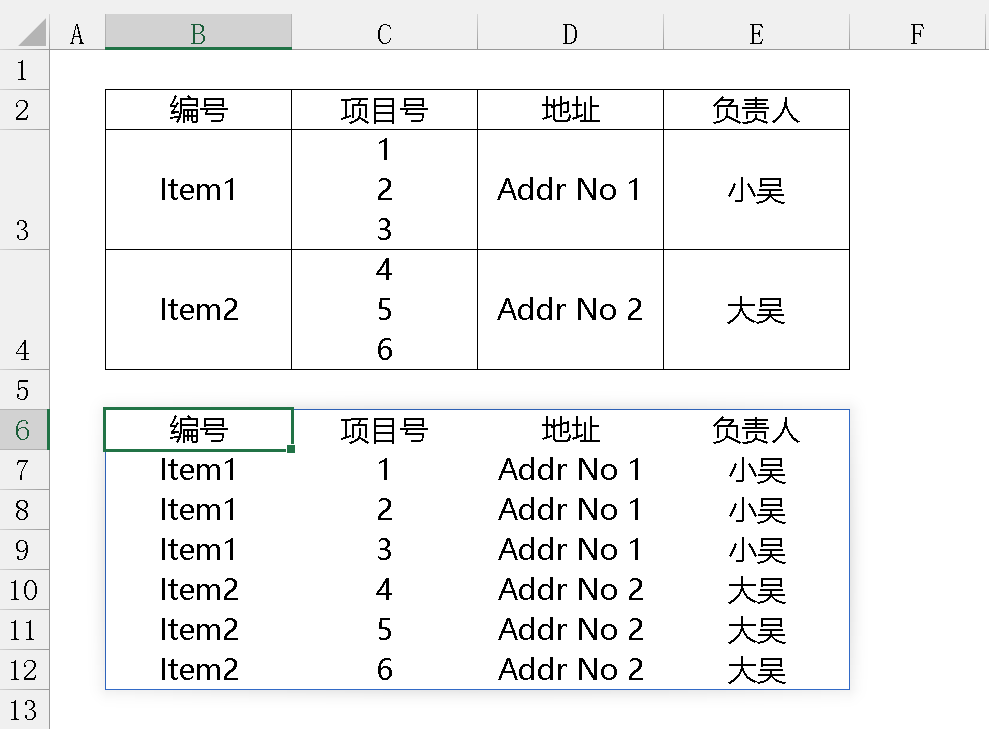
要把上表中项目号所在列中的值拆分到每一行,其它列复制,变成下表的格式。这种表格变形对 spl 来说就是小菜一碟,实现很简单。但有个问题,在用 news 方法时(此处只说 news 方法,不说其它序列嵌套遍历解法 A.conj(B.())),除了项目编号之外的字段,其它字段要一个一个手写出去,如果只有几个字段枚举一下也行,一旦字段很多,挨个枚举不是很妥当。当然,也可以事先用 fname 得到所有字段后拼接成文本串,再用宏去解析,这个方法也行,但要分两步。因为懒不想挨个敲字段,宏又不好驾驭,所以想到了用 derive@x() 一次性把所有字段展开,但这个方法的前提是要造一个 record 出来:

上图中有颜色部分就是之前讲到的复制 record 的变通方法,这样的话字段再多也不怕,要拆分的字段无论在哪个位置只要知道字段名就能动态实现拆分。因为这种复制 record 的方法有点不直接,所以想请教大佬们,有没有更直接一点的方法复制一条 record 使其 immutable。
还有另一种变形,只拆某些列其余的列不复制保持空 (有些 xml 文件解析出来就是这种格式),如下:

如何得到一条 immutable 的 record,恳请大佬们得闲时给予帮助解惑🙏


刚添加了记录的 derive 函数,可以更新开源的 jar 包试用
👌 谢谢大佬,大佬辛苦了🙏 等官网更新 jar 包再试吧,GitHub 我上不去。
尚有以下疑问:
1、record.derive()除了复制功能外,是否能增加字段和值,r.derive(value:key) 这样行不?
2、从 record 中删除某个或者某几个字段有办法弄吗?
趁机会把跟 record 有关的一下说完算了,我把微软 Power Query 里 Record 函数和集算器中 record 相关函数简单做了一个陈列展现,如下:
可以看到,集算器中可以对 record 直接操作的函数并不多,有些需要借助于序表函数间接转换得到。当然,并不是说函数多就是好。PQ 里所有结构都是 immutable 的,所以可以随意造,用户只要闭着眼写不会出现隔山打牛的情形。集算器中很有可能因为 mutable 的特性,所以在一些函数功能上做了精简。
上图中,最后 3 个函数我还是比较眼馋的,个人认为在表格变形转换中这 3 个函数能提供方便。虽然表格转换变形不是集算器的主要功能,但避不过,国内办公时得到的数据结构从源头就很乱,逃不过清洗这一关。
1、 record 的合并,在 PQ 中对两个及多个记录合并时,后一个记录中的字段会覆盖前一个记录中相同的字段,没有的自动按顺序添加,比如.r1 中有 a=1,r2 中有 a=11,r1&r2 合并后 a=11 覆盖了前一个 a=1:
集算器中没有 record 合并的操作,但有序列合并的操作,序列 1| 序列 2,或者 [序列,…].conj()
2、Record.ToTable 会把一条记录转换为一个表,这个表的列名默认为 Name 和 Value,Name 列对应 record 中的 Key,Value 列对应字段值。
集算器中没有直接的函数,只能通过 E@bp([record].array()) 来达到转换效果。
3、Record.FromTable 是 Record.ToTable 的逆操作,会把含有 Name 和 Value 列的表,不管这个表有多少列,只要字段含有 Name 和 Value 关键字,就会把这两列转换成 record。
集算器中没有直接操作的函数,也需要通过序表方法间接得到。
写这些东西没啥其它意图,不存在好坏比较,真的要比,说实话 PQ 效率太低了,实战玩不起来,要不是 PBI 中 DAX 引以为傲的 Vertipaq 引擎 (说白了就是列式计算引擎) 微软的 PBI 真的玩不起来(DAX 有点反人类思维,个人认为不好学),只是心里惦记大半年了,不吐不快,正好有机会一起提出来说一下。
还是那句话,念念不忘,终有回响…万一响了呢,是吧😄 🙏
1:支持 r.derive(value:key)
2:目前只有序表有更改、删除字段函数 T.alter,记录是否支持再考虑一下
谢谢大佬。
关于 record,我把想问的都列出来了,麻烦大佬再辛苦一下,看看有没有用得上的信息😄 🙏
这种功能基本上朝着表格变形去了,10 有 89 背离了集算器的设计方向。😂
我也不懂编程,写代码全凭个人喜好,给大佬们添麻烦了,见谅🙏
增加了 记录.alter(…) 函数用于调整字段顺序和删除字段,其它的函数暂时不增加了
好的…谢谢大佬🙏 谢谢老贼😄
SPL…light years ahead👍 👍 👍