


7.1 出料收率和生产路线
工业上,某些装置的出料收率波动比较大,其中的一些出料量还需要特别关注,这些需要关注的出料往往与生产路线对应,比如催化装置中,汽油的收率大时,认为是汽油路线,柴油的收率大时,认为是柴油路线…现在希望把历史收率数据分成指定数量的类别,让它们对应到相应的生产路线,后续在建模(质量守恒约束下的线性模型)时,选择相同生产路线下的数据作为输入数据,从而提高模型的准确性。
某种进料不同出料的收率数据用X表示:
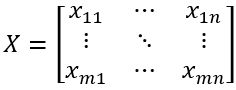
其中n是出料数,m是序号。每一行是某一天生产数据的不同出料的收率,每一列是某种出料每天的收率。
我们希望对收率数据X分类,但历史数据并没有标记好的分类数据,只能用无监督聚类,生产路线数对应分类数,kmeans聚类就可以满足聚类需求。
把收率数据X聚成的k类,聚类过程如下:
1. 随机选择k个数据作为初始类心C。
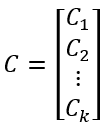
其中Ct是C的第t类的类心,是X中的某个随机成员。
2. 计算每个数据到这k个类心的距离,到哪个类心距离最近,就把该数据划为第k类。
xci=t,t=pmin(dis(Xi,Ct))
其中xci是X的第i行Xi的类别标记,Ct是第t类的类心,dis()是距离计算方法。
同一生产路线的收率相差不大,如果把X中的每一行看成高维空间中的一个点,同一生产路线下的点应该聚集在一起,不同生产路线的点又相对远离,所以我们选择欧式距离作为距离度量方法。
3. 更新类心。
计算每个类别中各种出料收率的均值,把它作为新的类心CN。
CNt=avg(Xtj),j∈[1,2,…,n],t∈[1,2,…,k]
其中CNt是第t类的新类心,Xtj是属于第t类的X的第j种出料收率。
4. 重复第2、3步,直到类心不在移动或达到最大迭代次数N。
即类心的距离和小于一个很小的数ε:
sum(dis(CNt, COt))<ε|| iter==N,t∈[1,2,…,k]
其中COt是上次迭代类心的第t类的类心,ε是一个很小的数,iter是迭代的次数,dis()是距离计算方法。
迭代结束后,X中每个点到哪个类心Ct的距离最近就属于哪一类。
xci=t,t=pmin(dis(Xi,Ct))
SPL例程
A |
B |
C |
D |
|
1 |
[[1,2,3,4],[2,3,1,2],[1,1,1,-1],[1,0,-2,-6]] |
/X |
||
2 |
=k=2 |
/类别数 |
||
3 |
=iter=300 |
/迭代次数 |
||
4 |
=center=null |
/初始类心C |
||
5 |
=it=0 |
|||
6 |
=func(A7,A1,A2,A3,A4) |
|||
7 |
func |
|||
8 |
if !D7 |
=D7=A7.sort(rand()).to(k) |
/随机类心 |
|
9 |
=it+=1 |
|||
10 |
return func(A7,A7,B7,C7,D7) |
|||
11 |
else |
=A7.((d=~,D7.(dis(~,d)))) |
||
12 |
=C11.(~.pmin()) |
|||
13 |
=A7.group(C12(#)) |
|||
14 |
=C13.((cent=mmean(~,1).~,if(ifa(cent),cent,[cent]))) |
|||
15 |
=C14.sum(dis(~,D7(#))) |
/新旧类心距离和 |
||
16 |
1E-4 |
/ε |
||
17 |
if C15<C16||it==C7 |
|||
18 |
=C14 |
|||
19 |
=C12 |
|||
20 |
return [D18,D19] |
|||
21 |
else |
=D7=C14 |
||
22 |
=it+=1 |
|||
23 |
return func(A7,A7,B7,C7,D7) |
|||
计算结果示例:
输入数据X:

聚类数k=2
最大迭代次数iter=300
聚类结果:
类心C:
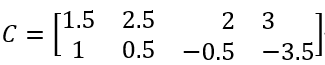
成员所属类别Xc:
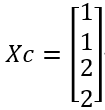
不难验证,X1,X2到C1的距离近,它们的均值就是C1,X3,X4到C2的距离近,它们的均值就是C2。

