"[图片] 如图所示,需要拿到每个渠道和地区的产品数量前五位,如有并列则全拿 =A1.groups(salechnl,seragefgscode;count(risk):rs).sort(rs: .."
如图所示,需要拿到每个渠道和地区的产品数量前五位,如有并列则全拿
=A1.groups(salechnl,seragefgscode;count(risk):rs).sort(rs:-1).derive(ranki(rs):id).select(id<=5)
我用这个方法可以拿到单组数据的前五位,但是无法拿到每个分组的,该怎么取到每个组的?
求大佬支招!
用聚合函数 top@i 中式排名:
=A1.groups(渠道,地区;top@i(-5;数量)).conj(#3)
我的集算器版本低,中式排名没效果,无法拿到并列的,其余都正常,这个该咋办
花钱升级啊😂…能花钱解决的事就不要烧脑😂
以下仅供参考
=A1.group(渠道,地区).conj(X=(Y=~).(数量),Y.select(X.rank@iz(数量)<6))
如果不能更新 jar 包,只能用 A.group 先分组得到组序列,再对每个组计算前 5 名。
想花公司的钱怕是有点难
是的,但我目前就是卡在这步了,要不就是只有第一个分组取前五,后面的都是空;要不就是所有分组成一个组了,每组各拿一个排名了
试试这个, 分组里的分组中 "- 数量" 是为了从大到小:
=A1.group(渠道,地区).conj@r(~.group(-数量).m(:5))
试了一下,有个问题,分组中总数不足五位的组,数据丢失,试了下 A.m@r(:5) 只找回部分,还是不足
把每组的行数和你要的 topn 数比一下大小,取较小的那个😂没注意这个问题,A.m(:N)N 越界时啥都没了😄第二次回复的那个 select+rank 是没有问题的,但那样写可能效率一般。
=A1.group(渠道,地区).conj@r(~.group(-数量).m(:min(5,~.p(-1))))
用 A.to(5) 吧
👍 👍 👍 谢谢大佬,学到了…
一直忽略了这个 A.to(n) 的用法;想着 A.m()是能越界容错的,没想到 A.m(a:b) 越界时啥也不剩了。
=A1.group(渠道,地区).conj@r(~.group(-数量).to(5))
用了 A.to(5)还是越界丢失数据,这也是版本低的原因吗?
还是这个可以,感谢了




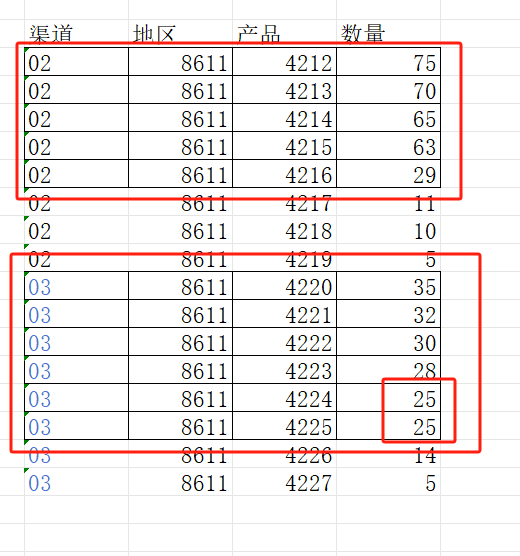

用聚合函数 top@i 中式排名:
我的集算器版本低,中式排名没效果,无法拿到并列的,其余都正常,这个该咋办
花钱升级啊😂…能花钱解决的事就不要烧脑😂
以下仅供参考
如果不能更新 jar 包,只能用 A.group 先分组得到组序列,再对每个组计算前 5 名。
想花公司的钱怕是有点难
是的,但我目前就是卡在这步了,要不就是只有第一个分组取前五,后面的都是空;
要不就是所有分组成一个组了,每组各拿一个排名了
试试这个, 分组里的分组中 "- 数量" 是为了从大到小:
试了一下,有个问题,分组中总数不足五位的组,数据丢失,试了下 A.m@r(:5) 只找回部分,还是不足
把每组的行数和你要的 topn 数比一下大小,取较小的那个😂
没注意这个问题,A.m(:N)N 越界时啥都没了😄
第二次回复的那个 select+rank 是没有问题的,但那样写可能效率一般。
用 A.to(5) 吧
👍 👍 👍 谢谢大佬,学到了…
一直忽略了这个 A.to(n) 的用法;
想着 A.m()是能越界容错的,没想到 A.m(a:b) 越界时啥也不剩了。
用了 A.to(5)还是越界丢失数据,这也是版本低的原因吗?
还是这个可以,感谢了