


SPL 复组表
OLAP 业务的数据一般不会出现大量频繁地更新动作。数据变动主要是:1、新增数据的追加,2、数据插入、修改和删除。
SPL 提供了复组表,可以有效缩短数据变动的处理时间,同时保证数据计算的性能。
复组表由多个组表文件构成的,这些组表称为复组表的分表,每个分表都有自己的分表号。
1. 追加型复组表
为了提高性能,SPL 要将数据按照某些字段有序存储。而定期产生的新增数据不一定总能有序地追加到原有数据后面。
比如订单表存储了大量订单数据,包含客户号 cid、订单日期 odate、订单号 oid、雇员号 eid 和订单金额 amt。为了提高性能,订单表可能要按照维字段 cid、odate 有序存储。每天产生的新订单 cid 字段通常还是同一批客户编号,不能直接在历史数据的末尾追加,否则会破坏 cid 的有序性。
如果每天都将历史数据和当天新数据重新排序或者有序归并,耗时过长。SPL 采用复组表可以方便地解决这个问题。
1.1. 存储结构
以订单表为例,复组表 orders 由 2 个分表组成,分表 1 存储历史数据,分表 2 存储当月数据。每天追加数据时,新数据只和分表 2 归并。分表 2 不断归并新数据一个月后,每月 1 日再和分表 1 做全量归并。
需要注意的是,分表号必须是整数,而且必须递增。
orders 的存储结构大致是这样的:

1.2. 初始化
在系统初始化的时候,复组表中的数据可能会来自数据库、文本文件或者其他数据源。假设 orders 的数据来自于文本文件 orders.txt,新建复组表并写入历史数据的代码大致是这样的:
A |
|
1 |
=file("orders.txt").cursor@t(cid,odate,oid,eid,amt).sortx(cid,odate) |
2 |
=file("orders.ctx":to(2)).create(#cid,#odate,oid,eid,amt;if(month@y(odate)==month@y(now()),2,1)) |
3 |
=A2.append@x(A1) |
A1 建立文本文件的游标,并按照需要排序。
A2 创建的复组表由 2 个组表文件构成,每个文件会有个编号,称为分表号。同时给出一个计算分表号的表达式 x,这里是 if(month@y(odate)==month@y(now()),2,1)。
A3使用append@x 追加数据时,SPL 会针对每条追加记录计算分表表达式x,根据结果把历史数据追加到分表1中,当月数据追加到分表2中。
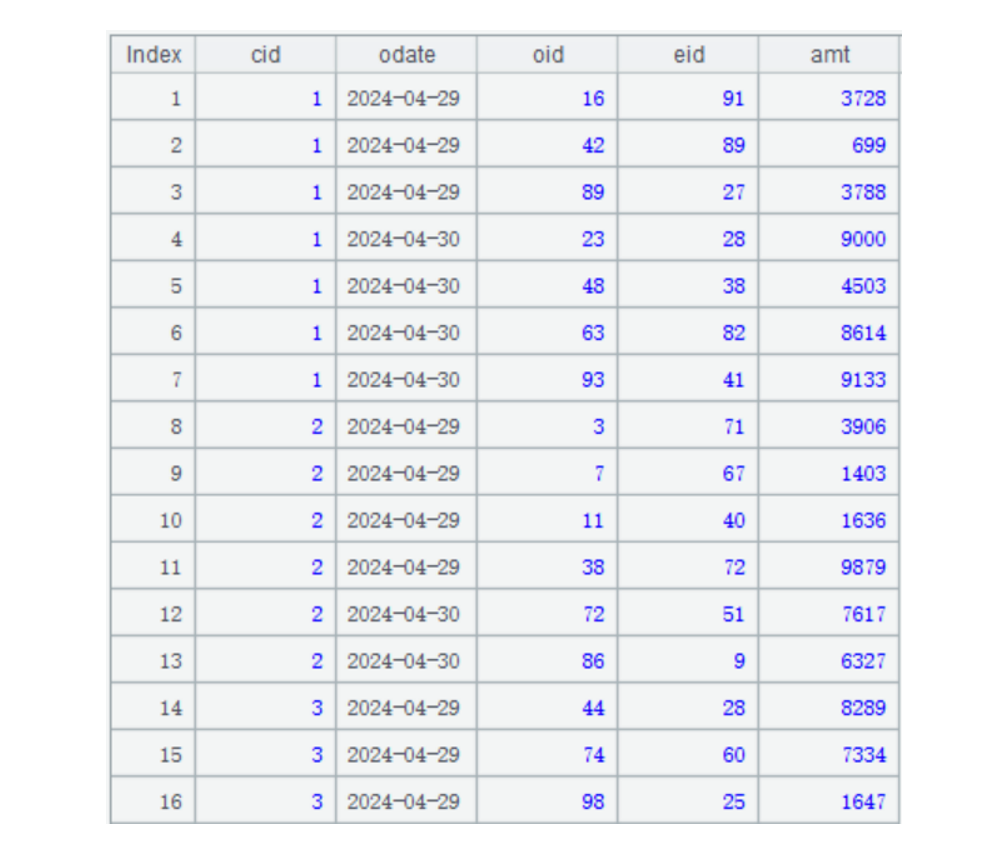
复组表生成后,数据会分别存储在各个分表中。例如 4 月份时,第二个分表 2.orders.ctx 中存储的数据大致是下图这样:
1.3. 实施计算
用追加型复组表计算时,代码写法和单组表几乎完全一样。比如按照客户分组统计 2023 年全年交易额的代码大致是这样的:
A |
|
1 |
=file("orders.ctx":to(2)).open().cursor(cid,amt;year(odate)==2023) |
2 |
=A1.group(cid;~.sum(amt)) |
A1 打开复组表时可以选择分表,这里选择了 2 个分表。
A2 做有序分组计算。分表 1 和分表 2 中的数据都对 cid 有序,两个文件有序归并后再做分组计算。性能比单个组表差一些,但是也很快。
1.4. 追加数据
orders_new.txt 中的每天新增订单数据归并到 orders 的分表 2 中,每月 1 日将分表 2 中的数据合并到分表 1 中。这样,分表 2 中最多只有一个月的数据,每天归并的耗时不会太久。每个月做一次全量归并,耗时长一些也可以接受。
代码大致是这样的:
A |
B |
|
1 |
=file("orders_new.txt").cursor@t(cid,odate,oid,eid,amt).sortx(cid,odate) |
|
2 |
=file("orders.ctx":to(2)) |
|
3 |
if day(now())==1 |
=A2.reset@y(A2,if(month@y(odate)==month@y(now()),2,1);A1) |
4 |
else |
=file("orders.ctx":2).open() |
5 |
=B4.append@m(A1) |
|
6 |
>B4.close() |
|
A1:当天新增数据按照维字段排序。
A3 判断如果是当月 1 日,B3 将复组表 orders 分表 1、2 和新增数据一起合并到 orders 中。合并后,上月数据在分表 1 中,本月 1 日数据在分表 2 中。
A3 判断如果不是当月 1 日,B4、B5、B6 将新增数据有序归并到分表 2 中。
用复组表 orders 进行计算的代码不变。
2. 追加型复组表 - 分区多表
前面介绍的追加型复组表由两个分表组成,比较适合中等规模数据量。当数据量非常大的时候,可以考虑用分区多表的方式解决,不仅能提升数据追加性能,还能很快速地批量删除过期历史数据。
2.1. 存储结构
仍以订单表为例,可以将历史数据也分成多个分表,每月一个分表,用年月 yyyyMM 作为分表号。比如 202402、…、202405 这些分表分别存储 24 年 2 月开始到 5 月结束的数据。
分区多表的存储结构大致是下图这样。为了区别前面的订单表,分区多表的订单表命名为 ordersN。

同时,要以全局变量 beginMonth、endMonth 表示订单数据开始和结束的月份 202402,202405。
从这个例子可以看到,分表号不一定是从 1 开始的,只要保持递增就可以。
2.2. 初始化
在系统初始化的时候,假设 ordersN 的数据来自于文本文件 orders.txt,新建复组表并写入历史数据的代码大致是这样的:
A |
B |
|
1 |
>env(beginMonth,202403),env(endMonth,202405) |
|
2 |
=file("orders.txt").cursor@t(cid,odate,oid,eid,amt).sortx(cid,odate) |
|
3 |
=file("ordersN.ctx":to(beginMonth,endMonth)).create@y(#cid,#odate,oid,eid,amt;month@y(odate)) |
|
4 |
=A3.append@x(A2) |
>A3.close() |
A1:确定开始月份和结束月份,这两个值可以作为初始化参数传入,也可以计算出历史数据 odate 字段年月的最大、最小值。初始化时,endMonth 一般都是当前月。
A2 将原数据按照 cid 和 odate 排序。
A3 建立一个复组表,分表号从 beginMonth 到 endMonth,分表表达式是计算 odate 的年月值。
A4 将排好序的原数据写入复组表,订单数据根据分表表达式的计算结果分别写入不同的分表。
以分表 202404 为例,数据是这样的:

2.3. 实施计算
用追加型复组表计算时,代码写法和单组表几乎完全一样。比如按照客户分组统计 2024 年全部交易额的代码大致是这样的:
A |
|
1 |
=file("orders.ctx":to(beginMonth,endMonth)).open().cursor(cid,amt;year(odate)==2024) |
2 |
=A1.group(cid;~.sum(amt)) |
A1 打开复组表时可以选择分表,这里选择了所有分表。
A2 做有序分组计算。每个分表中的数据都对 cid 有序,符合日期条件的多个文件有序归并后再做分组计算。性能比单个组表差一些,但是也很快。
对于批量删除过期数据的情况,只要不让过期数据的分表参加计算就可以了。比如 2 月份的数据过期了,只要将 beginMonth 从 2 改成 3 就可以了。
实际上,复组表分表号也可以不连续。比如仅计算 3 月和 5 月的数据,A1 就可以改为 =file("orders.ctx":[3,5]).open().cursor(cid,amt)。只要保持分表号递增就可以了。也就是说,生成用的复组表对象和计算用的未必是相同分表构成的,可以根据需要来决定哪些分表参与计算。
当然,前提条件是要判断 beginMonth<=3 && 5<=endMonth。
2.4. 追加数据
orders_new.txt 中的每天新增订单数据归并到 ordersN 的最后一个分表中。每月 1 日新建一个分表,将新增数据追加到新增分表就可以了。这样,可以避免大量历史数据和新增数据的归并。
代码大致是这样的:
A |
B |
|
1 |
=file("orders_new.txt").cursor@t(cid,odate,oid,eid,amt).sortx(cid,odate) |
|
2 |
if day(now())==1 |
>endMonth=month@y(now()) |
3 |
=file("ordersN.ctx":[beginMonth]).open() |
|
4 |
=B3.create@y(file("ordersN.ctx":[endMonth])) |
|
5 |
=B4.append@i(A1) |
|
6 |
>B3.close(),B4.close() |
|
7 |
else |
=file("ordersN.ctx":endMonth).open() |
8 |
=B7.append@m(A1) |
|
9 |
>B7.close() |
|
A1 将新增数据按照 cid、odate 排序。
A2 判断如果是当月第 1 天,则执行 B2 到 B6。
B2 将结束月改为当月。B4 新建一个当月分表。新增数据添加到新建分表中。
A2 判断如果不是当月第 1 天,则执行 B7 到 B9。
B7 打开结束月分表。B8 将新增数据有序归并到结束月。
追加数据之后,计算代码不需要改变。
3. 更新型复组表
追加型复组表不能用于对历史数据更新(插入、删除、修改)的情况。
如果更新的数据量很小,可以使用单组表的补区方式,详细介绍参见【性能优化】2.6 [外存数据集] 数据更新及复组表。
当每次更新数据量都比较大时,补区可能出现装不下的情况,要采用更新型复组表来实现。更新型复组表必须有主键。
我们先看只有插入、修改,没有删除的情况。
3.1. 存储结构
更新型复组表可以用一个分表存储历史数据,另一个分表存储更新数据。
假设用分表 1 存储历史数据,分表 2 存储当月更新数据,更新型订单表存储结构大致是下图这样。为了区别追加型订单表,命名为 ordersModify。
 每天更新数据时,新数据只和分表 2 合并。每月 1 日,分表 2 再和分表 1 做全量合并。
每天更新数据时,新数据只和分表 2 合并。每月 1 日,分表 2 再和分表 1 做全量合并。
3.2. 初始化
下面来看初始化代码的写法。订单表主键是客户号 cid、订单日期 odate、订单号 oid。客户姓名 cname 和所在城市 ccity 也被冗余到了订单表中。
注意还要新增一个记录更新时间字段 mdate。订单数据大致是这样的:
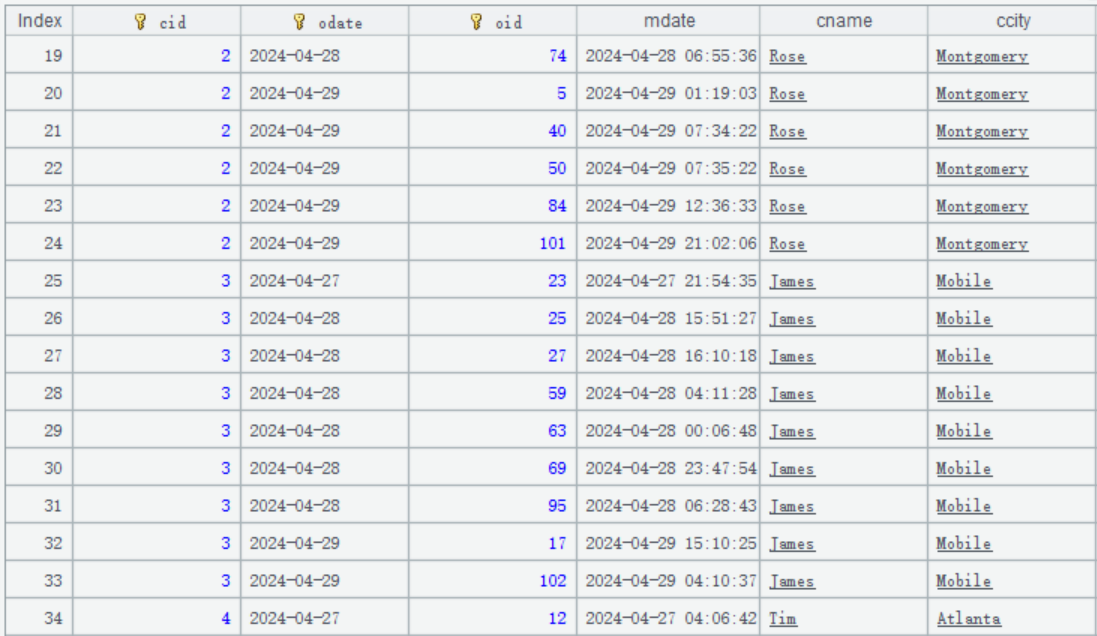
系统初始化时,要先将历史数据写入分表 1,代码大致是这样的:
A |
B |
|
1 |
=file("orders.txt").cursor@t(cid,odate,oid,cname,ccity,eid,amt).sortx(cid,odate,oid) |
|
2 |
=file("ordersModify.ctx":[1]).create@y(#cid,#odate,#oid,cname,ccity,eid,amt;1) |
|
3 |
=A2.append@i(A1) |
>A3.close() |
A2 创建分表 1,A3 写入历史数据。
3.3. 数据更新 - 无删除
假设从数据源过来的更新数据存放在 orders_new.txt。2024 年 4 月 30 日的更新数据大致是这样的:
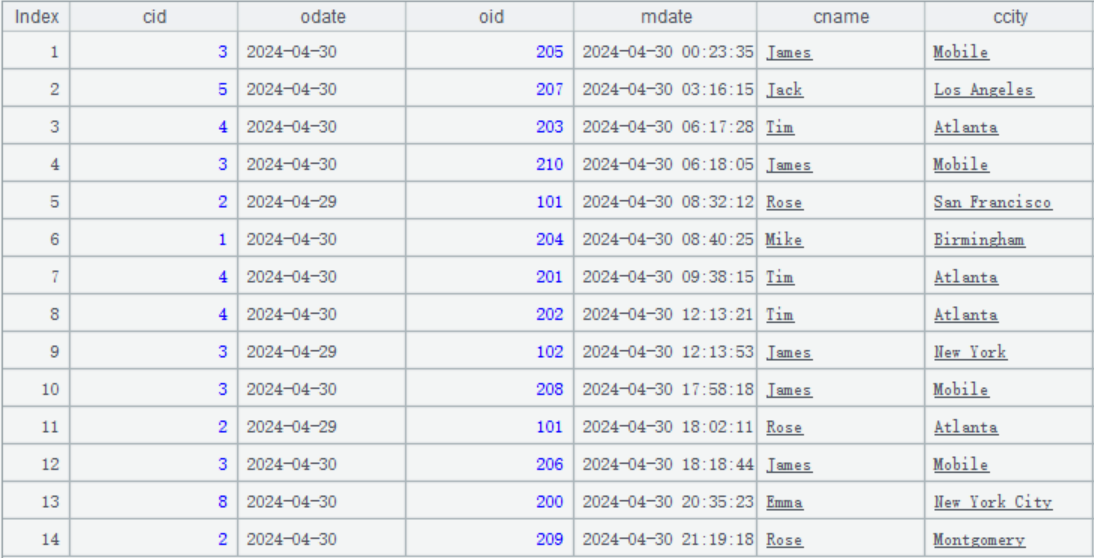
更新数据往往是按照更新时间升序排序的,而且可能会对同样的主键做多次修改。
比如上图中,index 是 5 的记录,要对主键是 [2、2024-04-29、101] 的订单数据做修改,将 ccity 改成 San Francisco。index 是 11 的记录,又改成了 Atlanta。
2024 年 5 月 1 日更新时,更新数据是这样:
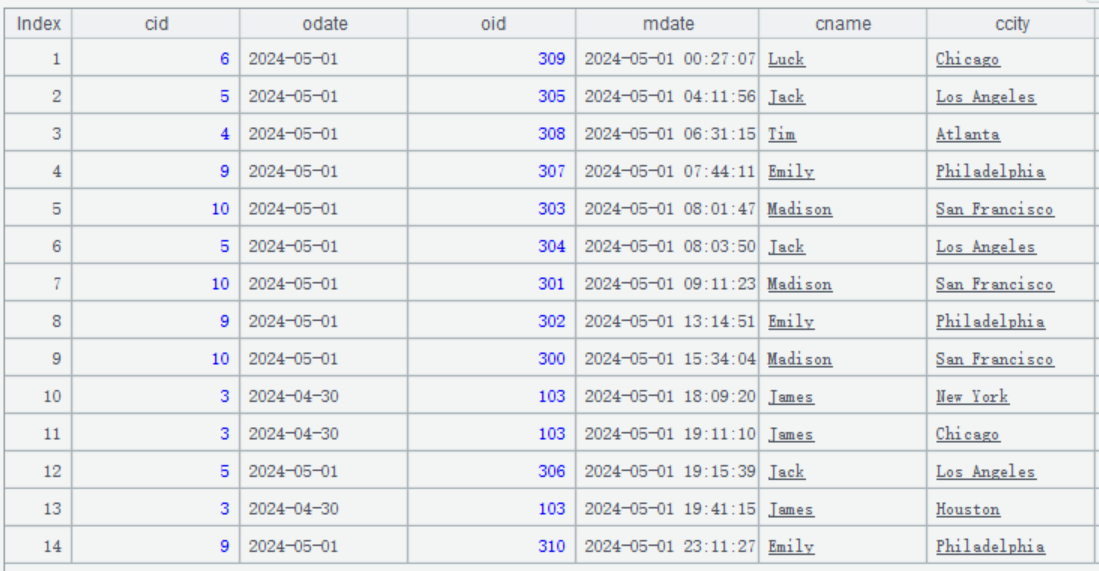
其中,index 是 10 的记录先插入了主键是 [3、2024-05-01、103] 的订单数据。然后 index 是 11 和 13 的记录,又两次修改这个主键记录,将 ccity 改成 Chicago 和 Houston。
对 ordersModify 进行更新的代码大致是这样的:
A |
B |
|
1 |
=file("orders_new.txt").cursor@t(cid,odate,oid,eid,amt).sortx(cid,odate,oid,mdate) |
|
2 |
if day(now())==1 |
=file("ordersModify.ctx":[1,2]).reset@wy(file("ordersModifyNew.ctx":[1])) |
3 |
=movefile@y("1.ordersModifyNew.ctx","1.ordersModify.ctx") |
|
4 |
=file("ordersModify.ctx":1).open() |
|
5 |
=B5.create@y(file("ordersModify.ctx":[2])) |
|
6 |
>B6.close(),B5.close() |
|
7 |
=file("ordersModify.ctx":[2]).reset@wy(;A1) |
|
A1 是源数据传过来的更新数据,注意:一定要按照主键、更新时间升序排序。
A2 判断是不是当月 1 日,如果是,执行 B2 到 B6。否则跳转到 A7。
B2 将分区 1、2 合并到新复组表 ordersModifyNew.ctx 的分区 1 中。reset 的 w 选项表示要自动处理分区 1、2 出现的相同主键,保留 mdate 最大的记录。
B3 将新复组表分区 1 改名,覆盖原复组表分区 1。
B4 到 B6 清空、新建分区 2。
A7 将更新数据游标合并到分区 2 中。reset 的 w 选项表示要自动处理分区 2 和更新游标中重复出现的相同主键,保留 mdate 时间最大的记录。
3.4. 实施计算
对 ordersModify 查询、计算的代码大致是这样的:
A |
B |
|
1 |
=file("ordersModify.ctx":[1,2]).open().cursor@wx().fetch(100) |
|
2 |
=file("ordersModify.ctx":[1,2]).open().cursor@wx() |
|
3 |
=A2.group(cid;~.cname,~.sum(amt)) |
|
A1:对 ordersModify 表的分表 1、2 进行查询,cursor 的 @w 选项表示要处理分区 1、2 中出现的相同主键,以分区 2 中为准。
5 月 1 日更新后,A1 的计算结果是这样:
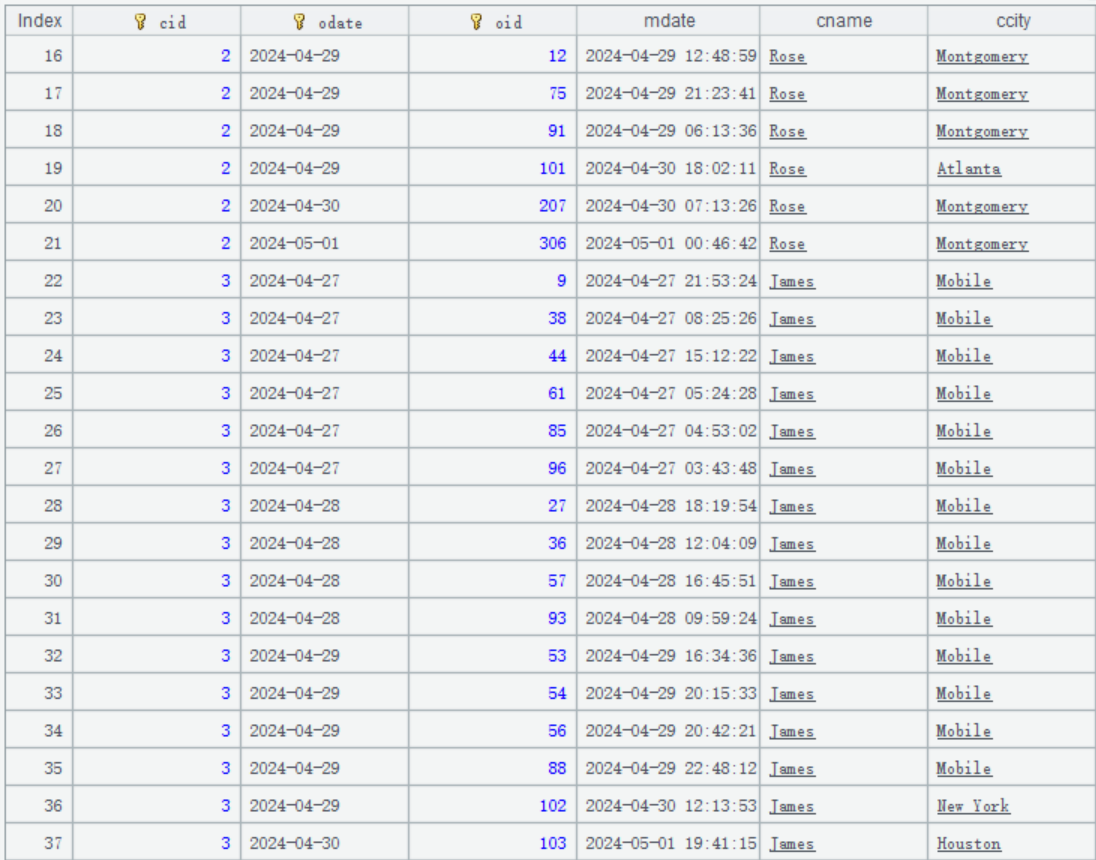
主键是 [2、2024-04-29、101] 的订单数据,ccity 已经改成 Alanta。
主键是 [3、2024-04-29、102] 的订单数据,ccity 已经改成 New York。
主键是 [3、2024-05-01、103] 的订单数据已经插入到适当的位置,ccity 已经改成 New Huoston。。
A3 中,可以按照 cid 有序分组、汇总。
3.5. 有删除的情况
增加删除标识字段
要处理删除的情况,更新型复组表必须增加一个删除标识字段。删除标识字段是维字段之后的第一个字段,其值为 true 表示删除数据、为 false 表示修改数据、为 null 表示插入。
比如订单数据增加删除标识字段 mflag 后,大致是这样的:
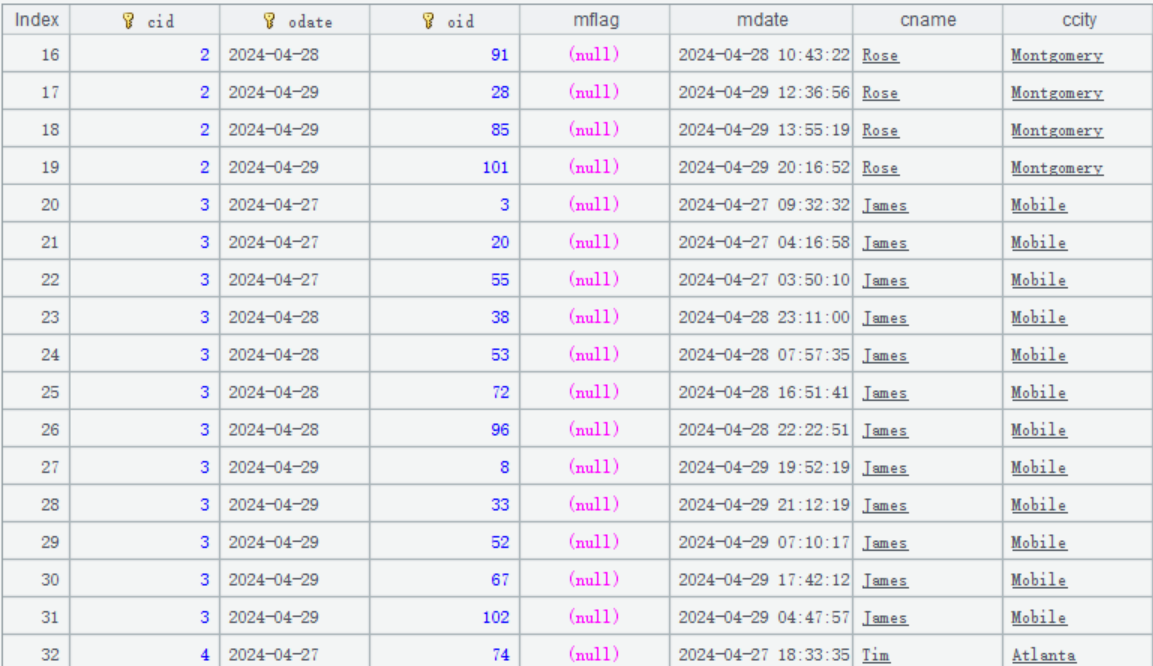
系统初始化
系统初始化时,将历史数据加入分表 1 的代码和无删除的情况略有不同,大致是这样的:
A |
B |
|
1 |
=file("orders.txt").cursor@t(cid,odate,oid,mflag,mdate,cname,ccity,eid,amt).sortx(cid,odate,oid) |
|
2 |
=file("ordersModify.ctx":[1]).create@dy(#cid,#odate,#oid,mflag,mdate,cname,ccity,eid,amt;1) |
|
3 |
=A2.append@i(A1) |
>A3.close() |
A2 创建分表 1,create 加 d 选项表示主键后面第一个字段 mflag 是删除标识,SPL 在合并数据的时候,会自动完成数据的插入、删除和修改。
每天从数据源过来的订单更新数据 orders_new.txt 也要包含删除标记字段 mflag。比如 4 月 30 日的更新数据是这样的:
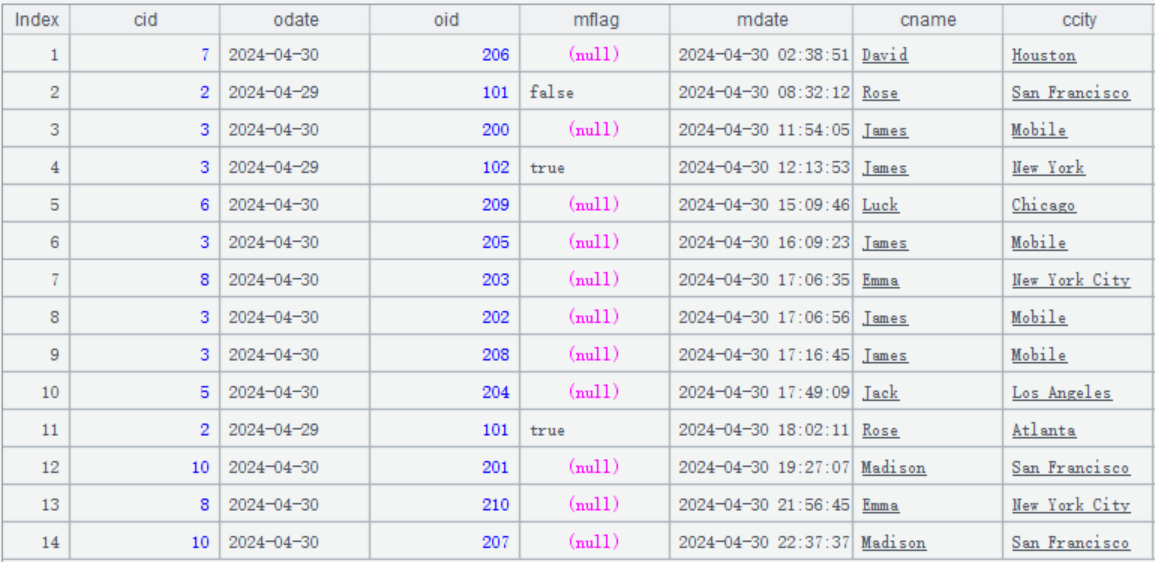
更新数据是按照修改时间 mdate 有序的,也存在订单主键重复出现的情况,比如:
index 是 2 的记录表示要修改主键是 [2、2024-04-29、101] 的订单数据。
index 是 4 的记录表示要删除主键是 [3、2024-04-29、102] 的订单数据。
index 是 11 的记录表示要删除主键是 [2、2024-04-29、101] 的订单数据。
其他都是追加的数据。
更新和实施计算
有删除的更新、实施计算代码,和无删除的情况是一样的。
删除标识的三种状态
前面说过删除标识有三种状态,那么为什么要用 false 和 null 来区分修改和插入呢?我们以 4 月 30 日的更新数据为例,来说明原因。
这一天并不是当月 1 日,只要将更新数据合并到分表 2 中就可以了。和无删除时一样,也要用 reset@w 函数自动合并计算。
上图中,更新数据 index 为 11 的记录主键是 [2、2024-04-29、101],删除标识是 true,表示要删除这个主键。
由于分表 1 不参加计算,reset@w 无法判断其中有没有这个主键的记录。这时候,要在更新数据中找 mdate 更靠前的记录,来决定这个删除操作如何处理:
1、图中,前面的更新数据 index 为 2 的记录主键是 [2、2024-04-29、101],且删除标识是 false,表示修改。由此可推断出分表 1 中有这个主键,所以这个删除记录要保留,前面的修改要舍弃。
2、假设前面有主键是 [2、2024-04-29、101] 的更新记录,但删除标识是 null,表示插入。由此可推断出分表 1 中没有这个主键,所以这个删除记录和前面的插入记录都要舍弃。
3、假设前面没有主键是 [2、2024-04-29、101] 的更新记录。由此可推断出分表 1 中有这个主键,所以删除记录要保留。
从这个例子可以看出,删除标识必须有三个状态:true、false 和 null,否则 reset@w 无法自动处理有删除的各种情况。
4. 更新型复组表 - 分区多表
有些场景中,历史数据量特别大,而且更新又相对比较频繁。
这种情况下,更新也可以采用分区多表的方式。比如:每天的更新都产生一个新的分表,适当的时候再合并、重整。
4.1. 存储结构
采用每天一个分表时,分区多表的存储结构大致是这样的:
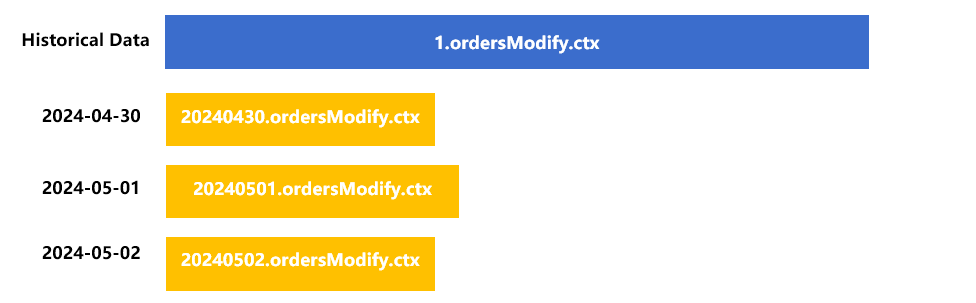
分表 1 中存放历史数据。
4 月 30 日更新的数据存入新建的分表 20240430。5 月 1 日、2 日的更新数据存入对应日期的分表。
4.2. 初始化
下面来看初始化代码的写法,订单数据大致是这样的:
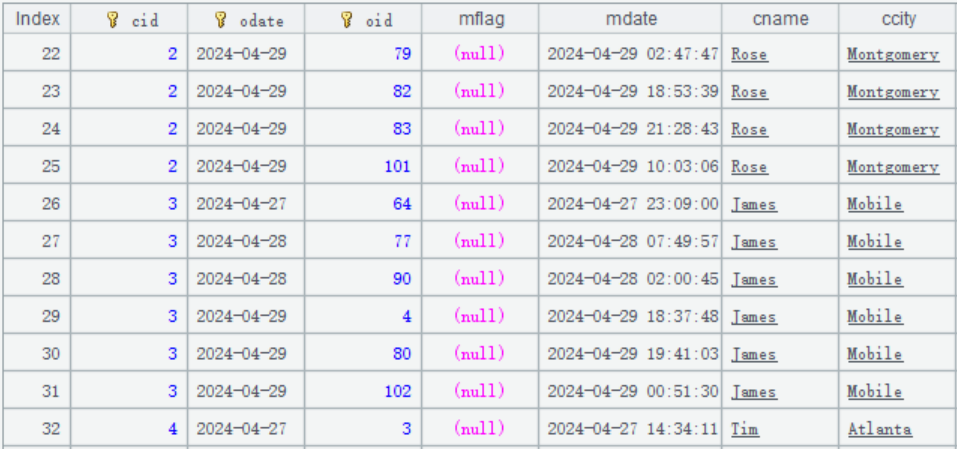
系统初始化时,要先将历史数据加入分表 1,代码大致是这样的:
A |
B |
|
1 |
=file("orders.txt").cursor@t(cid,odate,oid,mflag,mdate,cname,ccity,eid,amt).sortx(cid,odate,oid) |
|
2 |
=file("ordersModify.ctx":[1]).create@dy(#cid,#odate,#oid,mflag,mdate,cname,ccity,eid,amt;1) |
|
3 |
=A2.append@i(A1) |
>A3.close() |
A2 创建分表 1,这里 create 加了参数 d,如果是没有删除的情况,可以不加这个参数。
A3 写入历史数据。
4.3. 数据更新
多区分表的更新,也是用 reset@w 来实现。比如 2024 年 5 月 2 日更新数据是这样处理的:
A |
|
1 |
=int(string(now(),"yyyyMMdd")) |
2 |
=file("orders_new.txt").cursor@t().sortx(cid,odate,oid,mdate) |
3 |
=file("ordersModify.ctx":1).open() |
4 |
=A3.create@y(file("ordersModify.ctx":[A1])) |
5 |
>A4.close(),A3.close() |
6 |
=file("ordersModify.ctx":[A1]).reset@wy(;A2) |
A1 计算出分表号是 20240502。将 A2 更新数据按照主键和更新日期时间 mdate 排序。
A3 到 A5,用分表 1 新建分表 20240502。A6 将更新数据合并到分表 20240502 中。
4.4. 分表合并和实施计算
随着时间推移,分表会越来越多,要在合适的时候合并分表。合并的方式有两种:
方式 1:全合并。
将所有分表合并到分表 1 中。大致是下图这样:

方式 1 的代码大致是这样的:
A |
|
1 |
=file("ordersModify.ctx":[1,20240430,20240501,20240501]).reset@wy(file("ordersModifyNew.ctx":[1])) |
2 |
=movefile@y("1.ordersModifyNew.ctx","1.ordersModify.ctx") |
A1,所有分表合并到一个新的复组表。A2 用新的复组表第 1 分区,覆盖原复组表第 1 分区。
方式 1 合并后,实施计算的代码大致是这样的:
A |
|
1 |
=file("ordersModify.ctx":[1]).open().cursor@x().fetch(100) |
2 |
=file("ordersModify.ctx":[1]).open().cursor@x() |
=A2.group(cid;~.cname,~.sum(amt)) |
方式 2:部分合并。
任意选择几个更新分表合并,也可以达到减少分表的目的。比如合并分表 20240430 和 20240501 为新的分表 2,大致是下图这样。
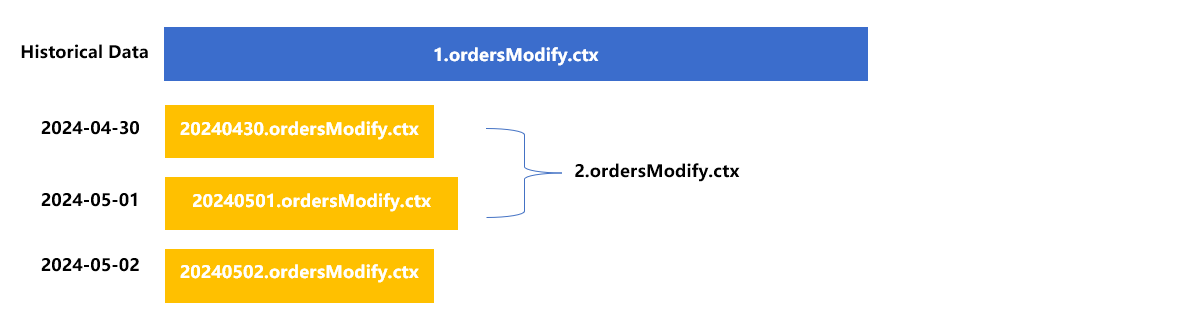
或者也可以只合并 20240501 和 20240502 为新的 20240502,只要保持分表号递增就可以了。
方式 2 的代码大致是这样的:
A |
|
1 |
=file("ordersModify.ctx":[20240430,20240501]).reset@wy(file("ordersModifyNew.ctx":[2])) |
2 |
=movefile@y("2.ordersModifyNew.ctx","2.ordersModify.ctx") |
A1,需要的分表合并到一个新的复组表。A2 用新的复组表第 2 分区,覆盖原复组表第 2 分区。
方式 2 合并后,实施计算的代码大致是这样的:
A |
|
1 |
=file("ordersModify.ctx":[1,2,20240502]).open().cursor@x().fetch(100) |
2 |
=file("ordersModify.ctx":[1,2,20240502]).open().cursor@x() |
=A2.group(cid;~.cname,~.sum(amt)) |
注意:实施计算的时候,分表号一定要包含当前所有的有效分表。比如 A1 中如果写成 [1, 20240502] 就会漏掉分表 2 中的更新,结果会出错。
这一点和追加型复组表是不同的。追加型多表分区时,复组表分表号可以不连续,可以根据需要选择分表号,比如:过滤条件只需要计算 3、5 月数据,那么 4 月份分表是可以跳过的。
5. 复组表应用例程
本文主要讲解复组表的原理和基本应用。前面介绍的追加和更新都是在业务计算暂停的时候进行的,比如每天下班以后不对外营业的时候进行计算。这种方式的追加和更新可以称为冷模式。
在实际应用中,复组表还可以用于热模式。也就是在追加和更新的同时,还可以进行业务计算。
具体的做法要复杂一些,参见数据维护例程。


英文版