


Excel 按顺序去重再编号
Excel的A有重复数据:
A |
|
1 |
Cow |
2 |
Chicken |
3 |
Horse |
4 |
Butterfly |
5 |
Cow |
现在要去除重复,用自然数按顺序进行编号,结果写在相邻列:
A |
B |
|
1 |
Cow |
1 |
2 |
Chicken |
2 |
3 |
Horse |
3 |
4 |
Butterfly |
4 |
5 |
Cow |
1 |
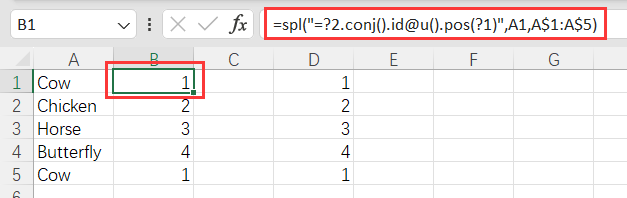
使用 SPL XLL,输入公式并向下拖:
=spl("=?2.conj().id@u().pos(?1)",A1,A$1:A$5)
也可以动态数组公式,一次性搞定
=spl("=(y=(x=?1.conj()).id@u()),x.(y.pos(~))",A1:A5)
conj将片区合并成一维数组,id 去重,@u 不重新排序,pos 求成员位置。


大佬,最后一条语句中 id@u() 右边少写了右括号。
这个解法很直观,如果在 Power Query 里用去重后再循环定位,效率肯定非常低,相比较而言,spl 的去重和定位效率要高很多。
但有个疑问,考虑一种比较极端的情况,如果序列中的重复值很少很少,甚至是没有重复,且数量较多,比如 5 万条无重复甚至更多,那用这个去重再定位的写法,时间复杂度是不是就很高了,会不会是 O(n 平方),还是 O(m*n)。所以,有没有其他的方法或者算法来实现?恳请大佬得空时赐予高招🙏
英文版
A.new(#:N,~:V).group@u(V).conj(~.run(V=get(1,#))).sort(N).(V)
这个复杂度是 N*logN 级别的
谢谢老贼出手👍 👍 👍 …果然起飞😄 😄 😄
对排序我有心理阴影,比如像 PowerQuery 里的 List.Sort 和 List.Distinct 稍微数据多一点就卡到不行。这下重新认识了。
我也写了一个,但要另辟空间 d,相当于一个字典,速度也还可以。
我不会算这种另辟空间的时间复杂度,恳请老贼得空时指点一下🙏 🙏
这个算复杂度意义不大,不停 insert 的工程复杂度比理论复杂度造成的“慢”更严重。关注性能时不要一条条 insert,集合运算要“一把抓”。
而且 fin@b 比 hash 慢(GROUP 和索引都会用 hash)
用 find 办法,是先 id@u 后 key@i 建索引,再用 pfind 找位置。但会算两次 hash,和排序可能有得一比,得试。
之前那个 sort 也可以用 align,因为都是序号,这样理论复杂度低。但 sort 整数也很快,未必能测出区别来。
不用排序大概这样可以 B=A.(1),A.group@pu().run(.run(B(~)=get(1,#))),B
自己试试
算复杂度纯粹是为了学习 (其实是为了吹牛 x😂 …哈哈)
大神这一席话,我彻底懵圈了,
集合运算要一把抓,这个我倒是能联想到 pandas 里的矢 (向) 量运算,效率很明显;
使用 find@b,我是想着 insert 缺少第一参数时,会自动按主键排序,正好产生一个有序可以用二分 @b;
align 第 2 次看你提起这个用法了,上次好像是关于 group 还是什么问题,当时没在意;
要重新认识 spl 的 sort😄
我捋捋先…谢谢老贼指点解惑🙏 🙏
谢谢老贼指点,帅到飞起来👍 👍 👍
以下是你写的两种高效方法,我搬来欣赏一下😄 :
1、
2、
@279400248
大神,之前您教的用 group@p 排序的方法用上了,太牛了,incredibly efficient, 五体投地🙏 🙏
如下图左侧所示,根据班级分组按分数高低中式排名,不改变源表顺序。😄 😄