


用 SPL 编写 AWS lambda 函数
1. 前言
利用AWS Lambda函数,可以运行代码而无需预置或管理服务器,可以直接从任何Web或移动应用程序调用函数获得运算结果,是非常便利的函数服务。在函数代码中可以读取业务数据,进行复杂运算处理后向调用者输出结果。然而数据处理和计算是一个复杂的过程,工作量大,编写、调试将会耗费大量的时间。SPL是数据计算领域的优秀工具,它能连接多种数据库、各种格式的数据文件等数据源,提供非常丰富的数据计算函数,可以用很简洁的代码编写您需要进行的计算功能,并且提供方便的可视化分步调试功能。用SPL来编写lambda函数以处理和计算数据,将会大大减少函数代码的编写工作量,提高开发效率。
2. 函数 runSPL 编写
2.1 函数功能
runSPL函数用于启动SPL运行环境,运行编写好的SPL脚本,并将结果以json格式返回给函数调用端。
2.2 函数参数
runSPL接收2个参数splx和parameters,splx指定编写好的脚本文件的位置,parameters是splx脚本所需要的参数,格式为json串。
2.3 源代码
[RunSpl.java]
package com.scudata.lib.shell;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.net.URI;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.json.JSONObject;
import software.amazon.awssdk.auth.credentials.AwsBasicCredentials;
import software.amazon.awssdk.auth.credentials.StaticCredentialsProvider;
import software.amazon.awssdk.http.SdkHttpClient;
import software.amazon.awssdk.http.apache.ApacheHttpClient;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.S3ClientBuilder;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.scudata.app.config.ConfigUtil;
import com.scudata.app.config.RaqsoftConfig;
import com.scudata.app.config.RemoteStoreConfig;
import com.scudata.cellset.datamodel.PgmCellSet;
import com.scudata.common.Logger;
import com.scudata.dm.Env;
import com.scudata.dm.FileObject;
import com.scudata.dm.JobSpaceManager;
import com.scudata.ecloud.ide.GMCloud;
import com.scudata.ecloud.util.InitialUtil;
import com.scudata.ide.spl.Esprocx;
import com.scudata.lib.ctx.ImS3File;
import com.scudata.lib.lambda.ImUtils;
public class RunSpl implements RequestHandler<Map<String, Object>, Object> {
private static S3Client s3Client;
private com.scudata.dm.Context splCtx;
static {
InputStream stream = null;
try {
Logger.info("spl start........");
//读取部署包中的SPL配置文件
String xml = "/opt/java/config/raqsoftConfig.xml";
File f = new File(xml);
if (f.exists()) {
stream = new FileInputStream(f);
RaqsoftConfig rc = ConfigUtil.load(stream, true);
InitialUtil.loadAcloudFunctions(); //加载Qfile等函数
GMCloud.initQJDBC( rc ); //加载配置文件中的远程存储设置
List<RemoteStoreConfig> list = rc.getRemoteStoreList();
if( list != null && list.size() > 0 ) {
RemoteStoreConfig rsc = list.get( 0 );
JSONObject jo = new JSONObject( rsc.getOption() );
initS3(jo.getString("accessKey"), jo.getString("secretKey"), jo.getString("region"), jo.getString("endPoint"));
}
}
} catch (Throwable e) {
Logger.error("init SPL config error: " + e);
} finally {
try {
stream.close();
} catch (Throwable th) {}
}
}
public Object handleRequest(Map<String, Object> event, Context context) {
String ret = "";
try {
return doHandle(event, context);
}
catch( Throwable e) {
ret = e.getMessage();
Logger.error(e.getMessage());
}
return ret;
}
//初始化访问S3的配置
private static void initS3(String accessKey, String secretKey, String region, String endPoint) throws Exception {
SdkHttpClient httpClient = ApacheHttpClient.builder().build();
if (accessKey == null && secretKey == null) {
ImUtils.getS3Instance(region);
return;
}
AwsBasicCredentials awsCreds = AwsBasicCredentials.create(accessKey, secretKey);
StaticCredentialsProvider credentialsProvider = StaticCredentialsProvider.create(awsCreds);
S3ClientBuilder builder = S3Client.builder().httpClient(httpClient);
if (region != null && !region.trim().isEmpty()) {
Region reg = Region.of(region);
builder.region(reg);
}
if (endPoint != null && !endPoint.trim().isEmpty()) {
builder.endpointOverride(URI.create(endPoint));
}
s3Client = builder.credentialsProvider(credentialsProvider).build();
ImUtils.setS3Client(s3Client);
}
//函数处理方法:event中接收splx和parameters两个参数,执行指定的脚本并返回运算结果
private Object doHandle(Map<String, Object> event, Context context) throws Exception {
String bucket = null;
String objName = null;
splCtx = Esprocx.prepareEnv(); //运算脚本的上下文环境
Object o = event.get("parameters");
parseParameterToCtx( o );
boolean isS3File = false;
String splx = "";
o = event.get("splx");
if (o != null && o instanceof String) {
splx = o.toString();
//splx以s3://开头的表示是存储在S3上的文件
if( splx.toLowerCase().startsWith( "s3://" ) ) {
String[] vs = ImUtils.splitS3String( splx );
if (vs.length == 2) {
bucket = vs[0];
objName = vs[1];
}
isS3File = true;
}
}
else throw new Exception( "Function paramter value of splx is invalid." );
File splxFile = null;
if ( isS3File ) {
//从S3上下载脚本到/tmp/bucket/objName
ImS3File s3File = new ImS3File(bucket + "/" + objName, "utf-8");
splxFile = s3File.getLocalFile();
System.out.println( "splxFile=" + splxFile);
if (splxFile == null || !splxFile.exists()) {
throw new Exception( bucket + "/" + objName + " is not existed" );
}
}
else {
splxFile = new File( splx );
}
FileObject fo = new FileObject( splxFile.getAbsolutePath(), "p" );
PgmCellSet pcs = fo.readPgmCellSet();
try {
//执行脚本
pcs.setContext( splCtx );
pcs.calculateResult();
}
finally {
JobSpaceManager.closeSpace( splCtx.getJobSpace().getID() );
}
Object ret = pcs.nextResult();
Logger.info("spl end ....");
Object jsonVal = ImUtils.dataToJsonString(ret);
return jsonVal; //以json格式返回运算结果
}
//将参数串中的参数设置到上下文环境splCtx中
private void parseParameterToCtx( Object param ) {
if (param == null) return;
if (param instanceof String) { // for jsonString
String jsonVal = param.toString();
JSONObject json = new JSONObject(jsonVal);
Iterator<String> keys = json.keys();
while( keys.hasNext() ) {
String key = keys.next();
splCtx.setParamValue( key, json.get( key ) );
}
}
}
}
3. runSPL 部署
登录AWS帐户后,进入lambda服务页面。
3.1 创建层
lambda层(Layer)为函数提供可引用的资源,例如jar包或配置文件。runSPL创建4个层:
1、 myLayerLambdaS3:部署访问S3和lambda API所需要jar文件,压缩成lambda_s3.zip文件部署包,jar文件放入zip文件的java/lib目录中,这些jar来源于esProc 外部包中的S3Cli和LambdaCli,可在SPL官网下载
2、 myLayerSpl:部署运行SPL所需要的jar文件,压缩成spl.zip文件部署包,jar文件放入zip文件的java/lib目录中,这些jar来自安装后的SPL企业版安装目录下lib中,除以下4个外,其余是SPL引用的第三方jar包:
esproc-bin-xxx.jar
esproc-ext-xxx.jar
esproc-ent-xxx.jar
ecloud-xxx.jar
其中xxx是日期,尽量获取最新日期的包。
3、 mySqlJdbc:部署连接Amazon RDS MySQL数据库的JDBC程序包,只有一个mysql-connector-j-8.3.0.jar文件,可从https://dev.mysql.com/downloads/connector/j/下载,放入rds-mysql.zip文件中java/lib目录。如果访问别的数据库,就用相应数据库的JDBC包。
4、 runsplConfig:部署SPL配置文件raqsoftConfig.xml以及其它相关文件。本示例中包括要用到的本地脚本文件orders.splx和本地组表数据文件orders.ctx,压缩成config.zip文件部署包,raqsoftConfig.xml文件放入java/config目录中,orders.splx和orders.ctx放在根目录中。
raqsoftConfig.xml文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<Config Version="3">
<Runtime>
<DBList encryptLevel="0">
<DB name="rds_mysql">
<property name="url" value="jdbc:mysql://mysql-free2.c3oygm4kw7lr.rds.cn-north-1.amazonaws.com.cn:3306/tpch?useCursorFetch=true"/>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="type" value="10"/>
<property name="user" value="admin"/>
<property name="password" value="esp…..p"/>
<property name="batchSize" value="0"/>
<property name="autoConnect" value="false"/>
<property name="useSchema" value="false"/>
<property name="addTilde" value="false"/>
<property name="caseSentence" value="false"/>
</DB>
</DBList>
<esProc>
<charSet>GBK</charSet>
<splPathList>
<splPath>/tmp</splPath>
</splPathList>
<dateFormat>yyyy-MM-dd</dateFormat>
<timeFormat>HH🇲🇲ss</timeFormat>
<dateTimeFormat>yyyy-MM-dd HH🇲🇲ss</dateTimeFormat>
<mainPath>/tmp</mainPath>
<tempPath/>
<bufSize>65536</bufSize>
<parallelNum>32</parallelNum>
<cursorParallelNum>8</cursorParallelNum>
<blockSize>1048576</blockSize>
<nullStrings>nan,null,n/a</nullStrings>
<fetchCount>9999</fetchCount>
<extLibsPath></extLibsPath>
<customFunctionFile/>
<RemoteStores>
<RemoteStore name="S3" type="S3" cachePath="/tmp" minFreeSpace="0" blockBufferSize="0">
{"dataKey":"","endPoint":"https://s3.cn-north-1.amazonaws.com.cn", "secretKey":"aYI3JBZOuRGk…….vNhjDhoVQU0yN","accessKey":"AKIA……IIIXO","region":"cn-north-1","type":"s3","bCacheEnable":true}
</RemoteStore>
</RemoteStores>
</esProc>
<Logger>
<Level>DEBUG</Level>
</Logger>
</Runtime>
</Config>
其中<DB>节是访问Amazon RDS MySql云数据库的配置信息,此节内容要根据访问的云数据库的信息编写,也可以是其它云平台的其它类型的数据库。如果不需要访问数据库,也可以不配置此节。splPath和mainPath必须配置成/tmp,因为lambda虚拟机中只有/tmp目录是可写的,S3远程脚本和远程数据文件下载过来后存放在/tmp中。cursorParallelNum配置SPL脚本中多路并行函数的并行数。RemoteStore是访问你的S3的配置信息(如果不需要用到S3,也可以不配置),cachePath也配置为/tmp。
每个层的创建过程都类似的,下面以myLayerLambdaS3层创建为例讲解:
如下图所示,进入lambda服务页面后,点击左边导航菜单Layer,然后点击右边的Create layer按钮。
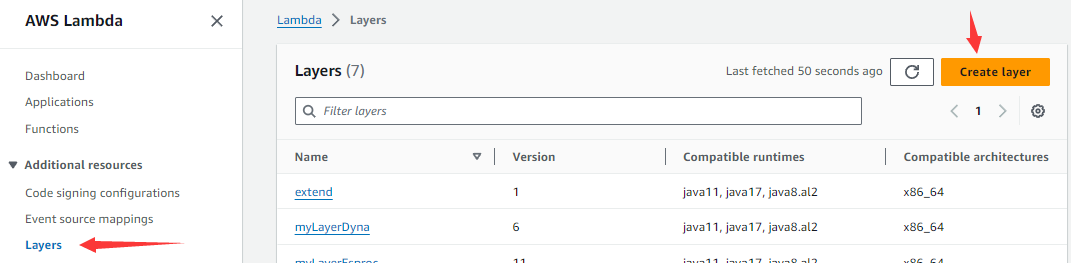
然后进入下图所示的页面:
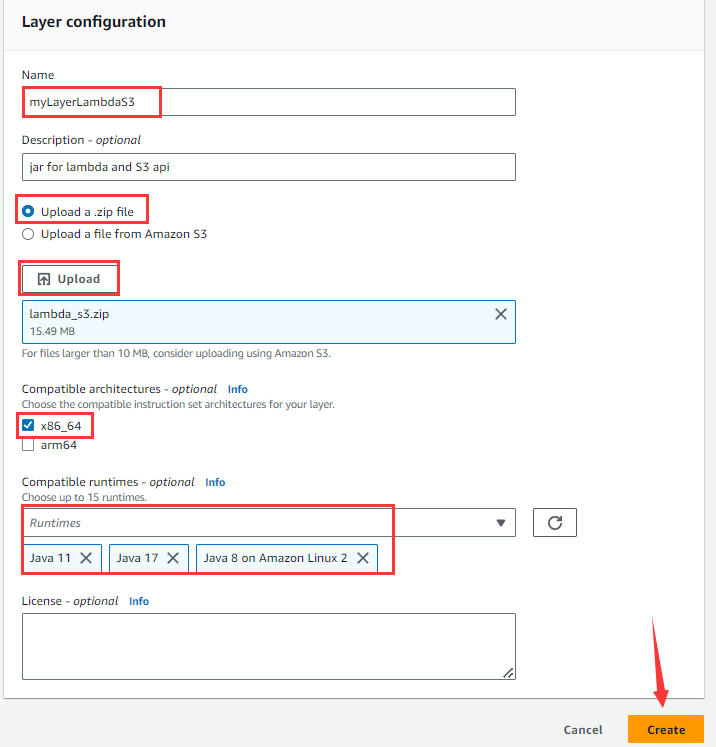
输入Name、Description(可不写),选择Upload a .zip file,点击Upload按钮,选择压缩好的lambda_s3.zip,选择x86_64架构,Compatible runtimes选择Java17、Java11和Java8,最后点击Create。
如果zip压缩包大于50M,则不能直接在这里上传,需要先将zip上传到S3保存,然后在这个页面选择Upload a file from Amazon S3,并输入zip文件在S3上的URL地址。
如果层的zip部署包有修改,那么需要在层列表页面中点击这个层,然后点击Create version按钮,重新上传zip部署包。
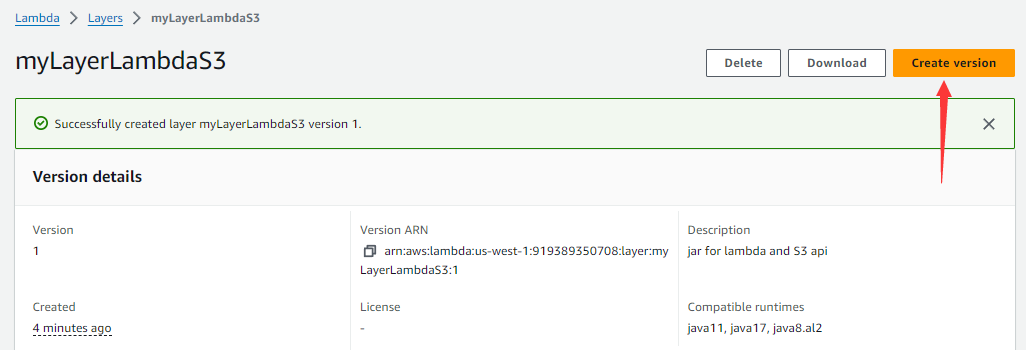
全部层创建好以后,层列表如下;
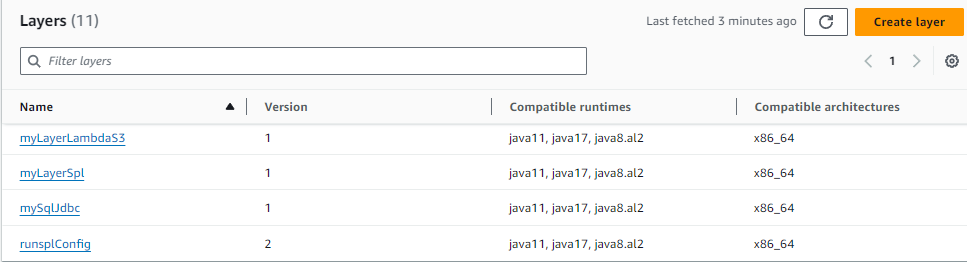 其中 runsplConfig层在测试过程中已经创建过新版本了。
其中 runsplConfig层在测试过程中已经创建过新版本了。
3.2 创建函数
编译runSPL函数相关的Java类,然后将所有class文件打包成runSpl.jar文件。
在lambda服务页面选择左边导航菜单Functions,然后点击右边的Create function按钮。

然后进入下图所示的创建函数页面:
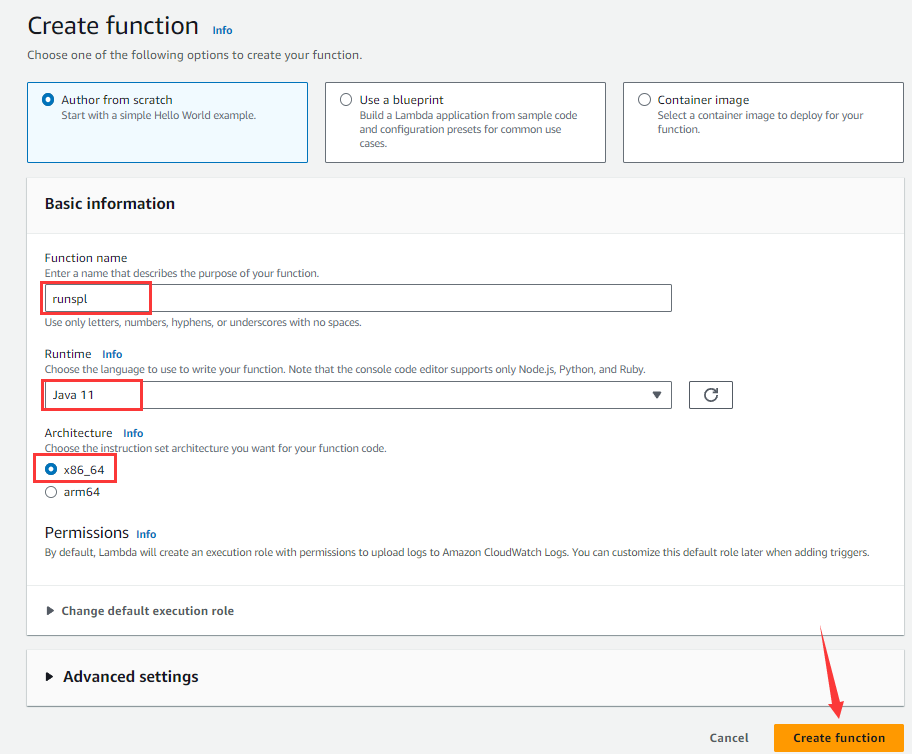
输入函数名runspl,Runtime选择Java 11,选择x86_64 Architecture,然后点击Create function按钮进入下图页面。
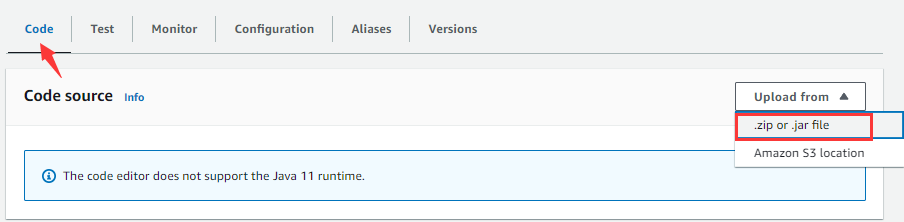
在Code tabpage中点击Upload from下拉列表,选择".zip or .jar file",弹出下图窗口:
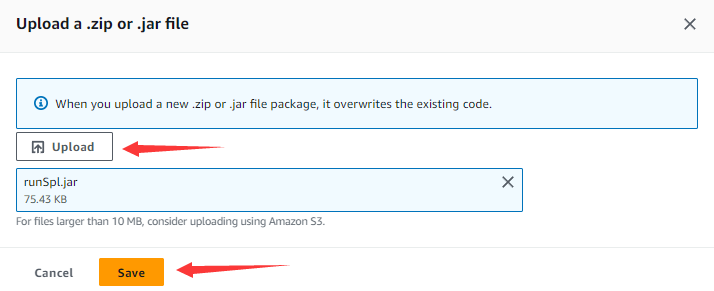
点击Upload按钮,选择已经打好的runSpl.jar文件,点击Save按钮。
在Code tabpage中,点击Runtime settings中的Edit按钮:
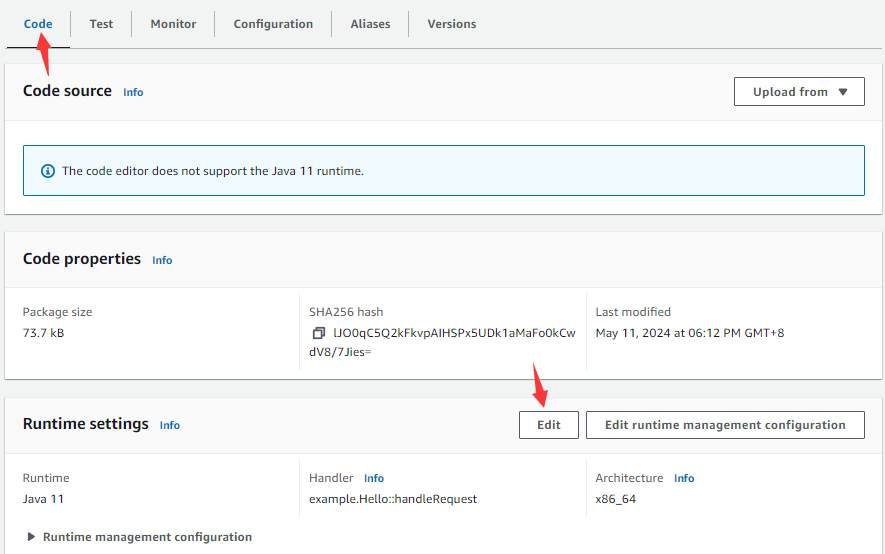
进入下图页面:
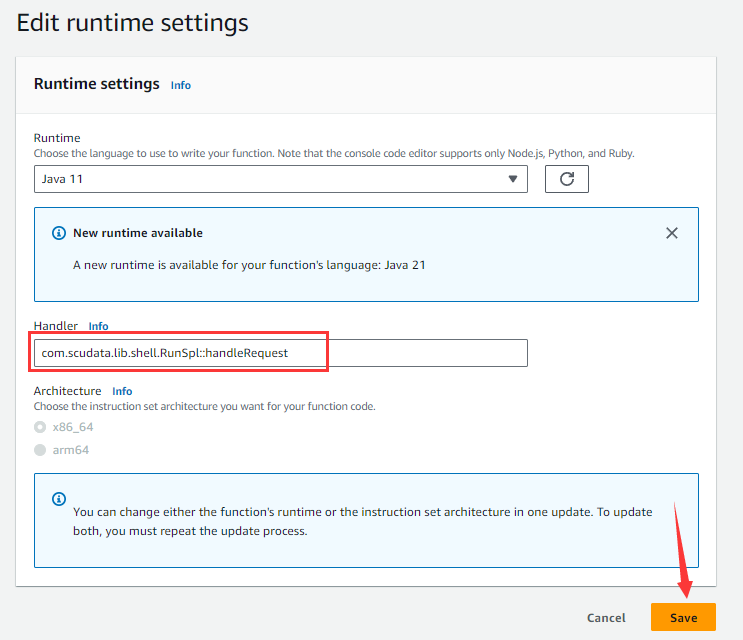
在Handler输入框填写函数的类名和处理方法名,点击Save按钮。返回Code tabpage以后,点击Add a layer按钮
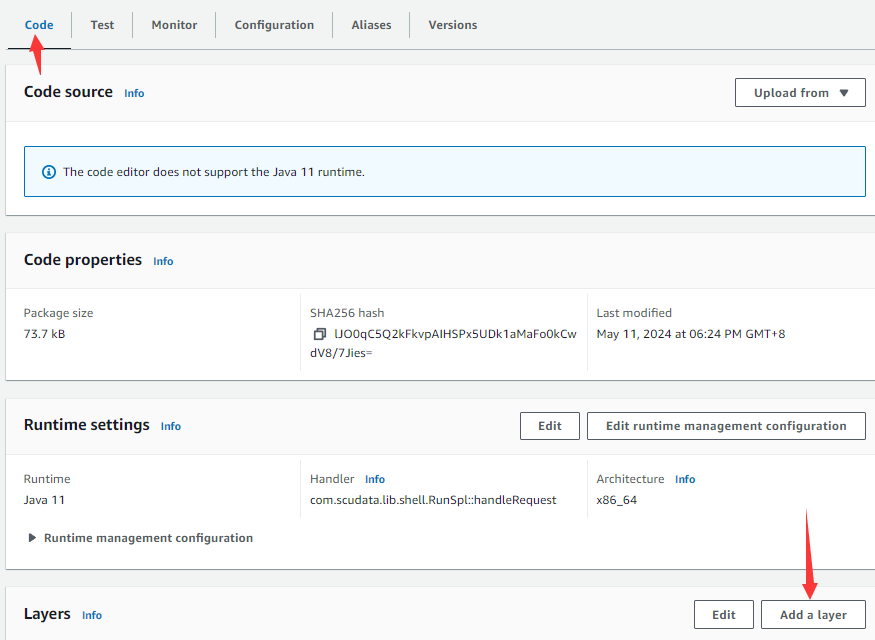
进入下图添加层页面:
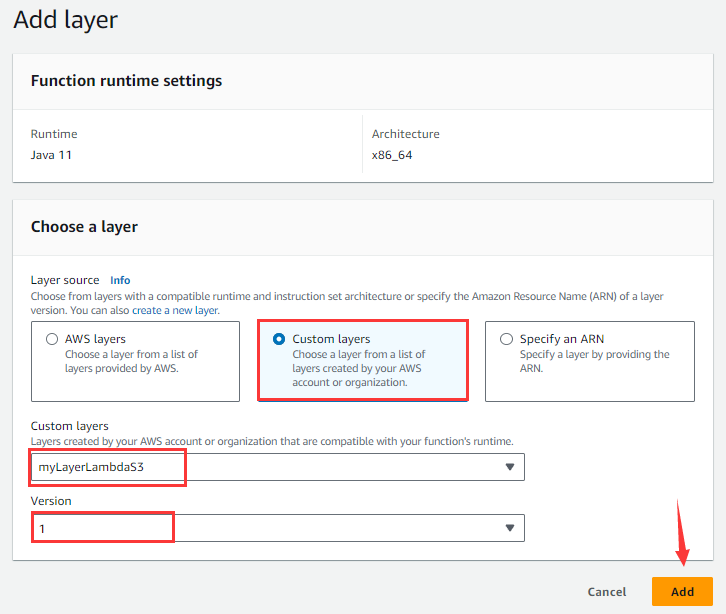
选择Custom layers,从下拉框Custom layers选择myLayerLambdaS3层,Version选择1,点击Add按钮。
重复添加层的操作,依次添加myLayerSpl、mySqlJdbc、runsplConfig等层。
然后进入Configuration tabpage:
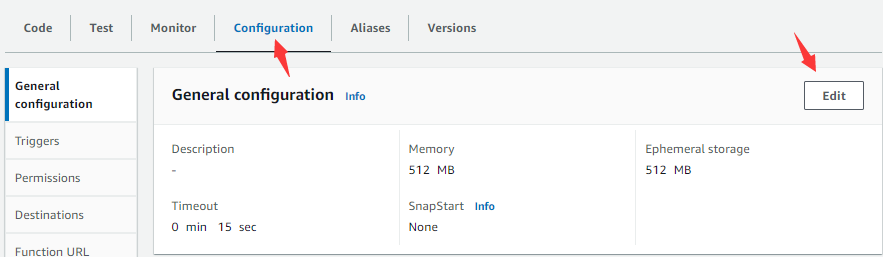
点击Edit按钮:
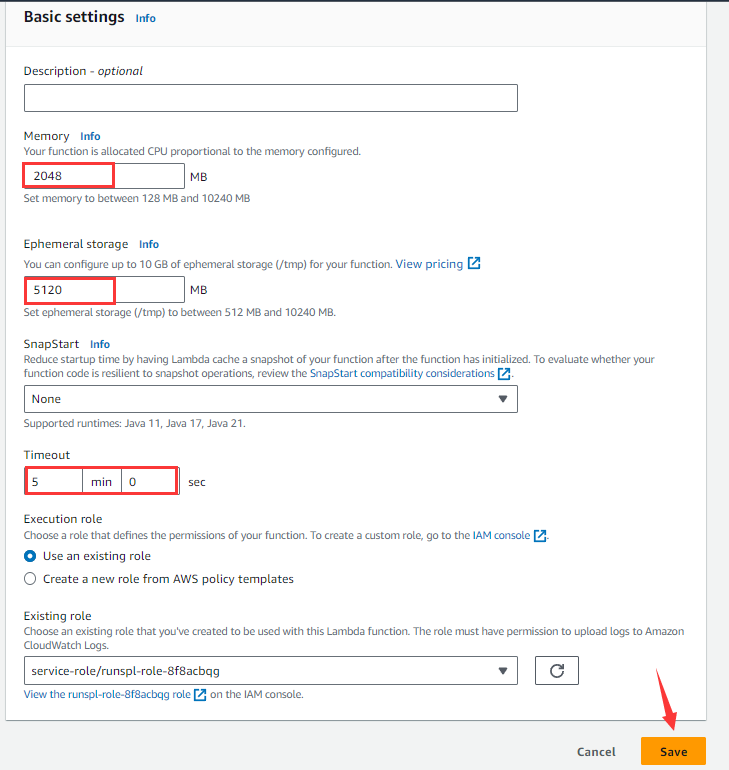
根据实际需求修改函数需要使用的Memory、Ephemeral storage、Timeout(前2者的大小与AWS收取运行费用额有关),点击Save按钮。
4. 调用函数
4.1 调用方法
写一个用Java程序调用runSPL:
public static String callRunSpl( String splx, String paramJson ) throws Exception {
Region region = Region.CN_NORTH_1;
AwsCredentials c = AwsBasicCredentials.create( "AKIATA……IIIXO", "aYI3JBZOuR……3FvNhjDhoVQU0yN" );
StaticCredentialsProvider credential = StaticCredentialsProvider.create(c);
LambdaClient awsLambda = LambdaClient.builder().credentialsProvider(credential)
.httpClient(ApacheHttpClient.builder().socketTimeout( Duration.ofMinutes( 10 ) ).build()).region(region).build();
JSONObject jo = new JSONObject();
jo.put( "splx", splx );
if( paramJson != null ) jo.put( "parameters", paramJson );
SdkBytes payload = SdkBytes.fromUtf8String( jo.toString() );
InvokeRequest request = InvokeRequest.builder()
.functionName( " arn:aws:lambda:us-west-1:91……708:function:runspl " )
.payload(payload).build();
InvokeResponse res = awsLambda.invoke( request );
String result = res.payload().asUtf8String();
awsLambda.close();
return result;
}
方法中的两个参数splx和paramJson分别对应runSPL函数中的参数splx和parameters。
第2行中的region是创建runSPL函数时使用AWS帐户所在的区域,第3行中是登录帐户的accessKey和secretKey,functionName方法中被调用函数的名称来源于下图所示:
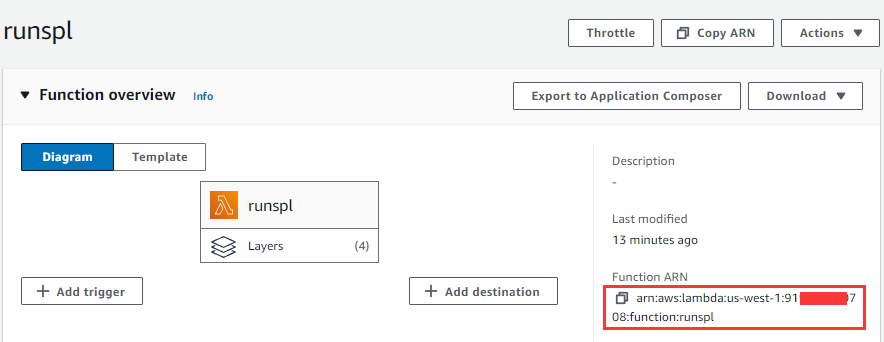
4.2 S3脚本用MySQL表数据计算
在Amazon RDS(Amazon Relational Database Service)云数据库管理系统中创建一个MySql数据库实例,并创建TPCH中的orders表,向表中导入数据(略去创建和导入数据的过程,使用JDBC访问其它云数据库的用法与本例类同)。编写使用orders表中数据进行计算的脚本rds-mysql.splx如下:
A |
|
1 |
=connect("rds_mysql") |
2 |
=A1.cursor@m("SELECT O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE FROM ORDERS where O_ORDERKEY<3000000") |
3 |
=A2.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
4 |
=A1.close() |
5 |
return A3 |
此脚本不需要参数,将脚本文件放在S3的un-bucket103存储桶中,函数调用语句如下:
String result = callRunSpl("s3://un-bucket103/rds-mysql.splx", null);
返回的result结果如下:
[{"year":1992,"status":"F","amount":17215923334.65},
{"year":1993,"status":"F","amount":17081696141.77},
{"year":1994,"status":"F","amount":17240680768.02},
{"year":1995,"status":"F","amount":3312513758.50},
{"year":1995,"status":"O","amount":10389864034.13},
{"year":1995,"status":"P","amount":3559186116.08},
{"year":1996,"status":"O","amount":17300963945.13},
{"year":1997,"status":"O","amount":17076455987.72},
{"year":1998,"status":"O","amount":10169293696.22}]
4.3 S3脚本用S3中组表数据文件计算
orders.ctx组表数据文件放在S3上的un-bucket103存储桶中,编写使用此组表中数据进行计算的脚本s3_orders.splx如下:
A |
|
1 |
=Qfile("un-bucket103/orders.ctx") |
2 |
=date(startDate) |
3 |
=date(endDate) |
4 |
=A1.open().cursor@m(O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE;O_ORDERDATE>=A2 && O_ORDERDATE<=A3) |
5 |
=A4.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
6 |
return A5 |
此脚本定义了2个参数表示查询订单的开始日期和结束日期:
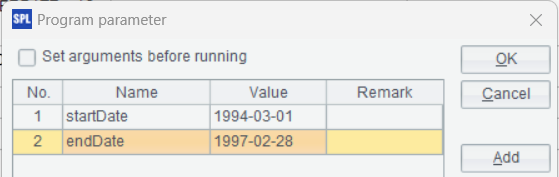
将脚本文件放在S3的un-bucket103存储桶中,函数调用语句如下:
String result = callRunSpl("s3://un-bucket103/s3_orders.splx", "{\"startDate\":\"1995-01-01\",\"endDate\":\"1997-12-31\"}");
返回的result结果如下:
[{"year":1995,"status":"F","amount":6.614961429260002E9},
{"year":1995,"status":"O","amount":2.082205436133004E10},
{"year":1995,"status":"P","amount":7.109117393009993E9},
{"year":1996,"status":"O","amount":3.460936476086E10},
{"year":1997,"status":"O","amount":3.437363341303998E10}]
4.4 本地脚本使用本地组表数据文件计算
orders.ctx组表数据文件放在runsplConfig层部署包config.zip的根目录中,编写使用此组表中数据进行计算的脚本orders.splx如下:
A |
|
1 |
=file("/opt/orders.ctx") |
2 |
=date(startDate) |
3 |
=date(endDate) |
4 |
=A1.open().cursor@m(O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE;O_ORDERDATE>=A2 && O_ORDERDATE<=A3) |
5 |
=A4.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
6 |
return A5 |
zip部署包会解压到运行runSPL函数的机器/opt目录中,所以组表文件路径是/opt/orders.ctx,访问本地文件,使用file函数。除此之外,此脚本前例一样。
此脚本文件也部署在config.zip压缩包中(也可以放在S3),函数调用语句如下:
String result = callRunSpl("/opt/orders.splx", "{\"startDate\":\"1995-01-01\",\"endDate\":\"1997-12-31\"}");
返回的result与前例相同。


英文版