

merge 函数计算异常
这个 bug 我稳定复现,两个 sqlite 数据库,里面的表都是一样的,只更新了表内容。
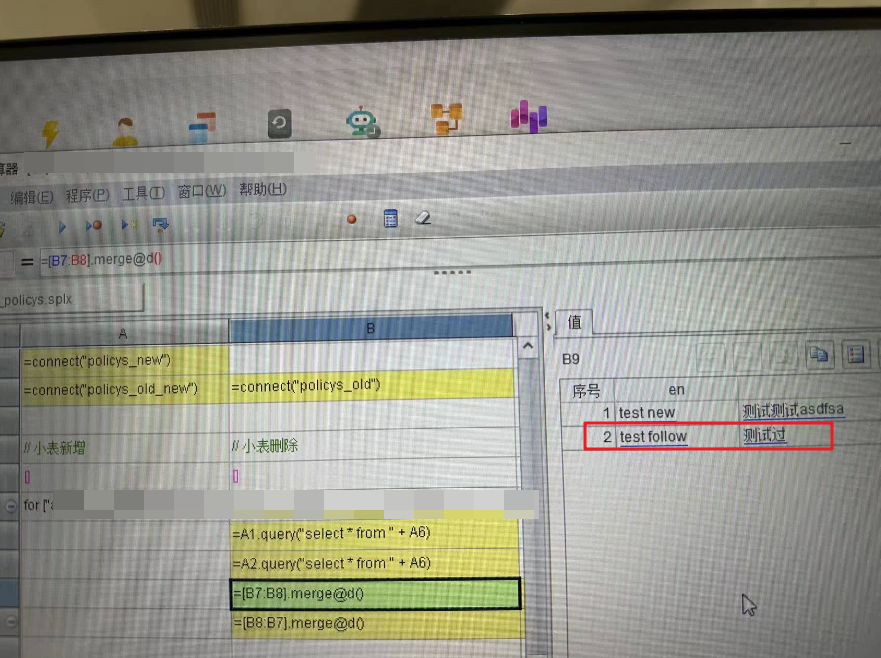
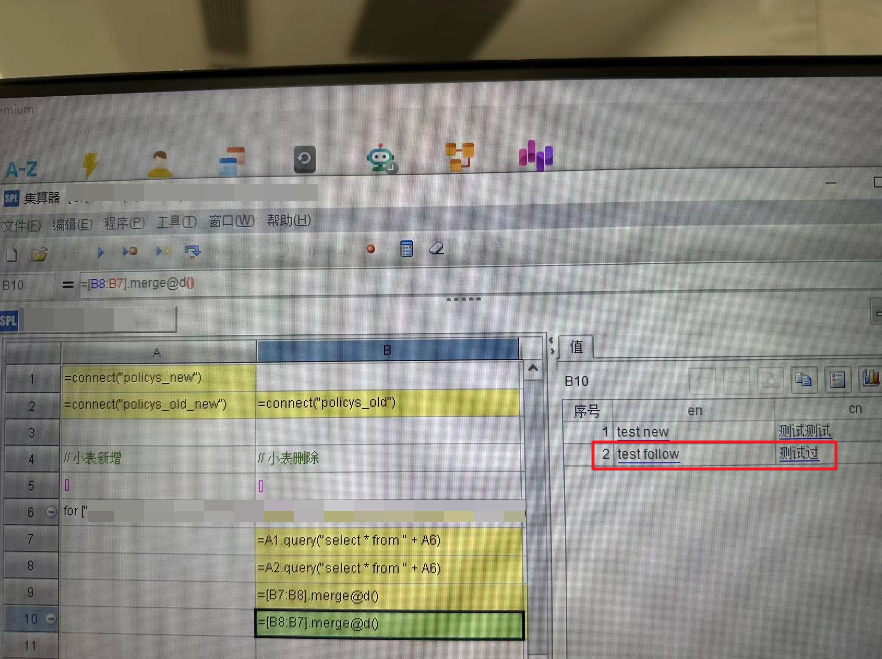
任选两个数据库中对应的两张表,表的最后一列以中文结尾时,在这一列的某个单元格中追加任意字母或者数字(此处为 "asdfsa")。此时再运行这个 splx 程序,merge@d不仅显示了被修改的行,后面的几个相邻的行大概率会被merge@d函数错认为发生了改变。
已经进行以下排查:
- 出现问题的都是相邻的行;
- 图中情况下,语句=[B9:B10].maerge@i()得到的结果是null;
- 当第一行的 "测试测试 123" 重新改为 "测试测试"(即两张表数据完全一致)后,这两行都能被merge@d正确处理,B9 与 B10 的结果都为null;
- 集算器版本 2024-02-01;
- 数据源未设置任何扩展属性,两个数据库的数据源 URL 都是jdbc:sqlite:C:/<filepath>/<name>.db。
问题紧急,麻烦尽快回复!


确认问题时,建议尽量把场景弄得更单一些。比如写两个常数序列(序表)看看是不是还有这个现象,而不要从数据库中取。
如果常数序列就有问题,那基本上可以确认是算法引擎有误,排错的程序员可以只关注这个环节,不用复制数据库环境了。
如果数据库取出来的数据才有问题,那很可能是数据库接口或存储的问题,比如是不是给补了空格等等,排错同学也只要关心数据库接口问题了。
另外,merge 函数缺省认为数据是(对于关键列)是有序的。SQL 读数如果不加 ORDER BY 不会保证这一点,很可能有随机性。可以读出的序表都列出来看看。
merge 函数默认要求数据按合并字段有序。
从返回值来看数据是无序的,可以使用 merge@do 选项来指明数据是无序的。