


BI 的前置计算
某机构上了一套分布式数据仓库,历史数据逐步装进了仓库,然后,基于数据仓库构建了 BI 系统(主要是多维分析)。刚开始,一切都顺利,但随着时间推移,基于中央数据仓库的应用越来越多,几年下来积累了数十个应用。这些应用都需要依赖数据仓库计算,导致中央数据仓库的负担越来越重,BI 系统的响应开始变得迟钝起来。对于交互性很强的多维分析业务来讲,这是很难容忍的。

咋办呢?
扩容是不现实的,这已经是个分布式系统了,节点数也差不多到了 MPP 型数据仓库的极限,再增加节点并不会有明显的性能提升了。
更换数据仓库也不可能,就算有测试出性能更好的产品也不敢换。几十个应用起码要全部重新测试一轮,否则谁也不能保证换了数据仓库后这些应用还能正常工作。这要协调很多部门才能动起来。而且,对多维分析测试表现好的产品,对其它应用也未必会更好,还可能导致其它应用的响应速度变得更恶劣了。
中央数据仓库的选择,对于很多机构而言是个重大的政治任务,不大可能仅为某一个应用的问题而轻易更换。
中央数据仓库暂不能动,就只能从应用端想办法。一个常见方案是采用前端计算,即把需要的数据放到应用端,由应用程序直接计算,不再请求中央数据仓库。技术上经常采用的手段是在应用端放一个前置数据库用来提供存储和计算能力。
但是,简单放一个普通数据库却解决不了这里的问题:
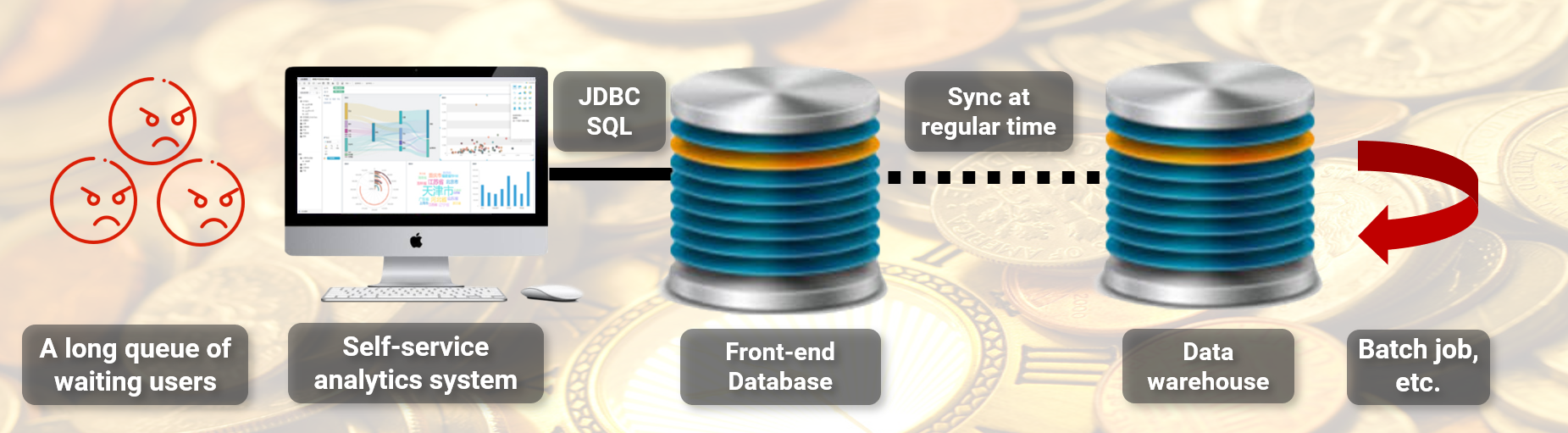
- BI 系统需要分析过去多年的全量数据,如果把涉及 BI 业务的数据都搬出来,那将会是和中央数据仓库规模在同一个数量级上的数据,这相当于要再重建一个分布式数据系统了,这个成本不可能接受了。
- 如果只放较频繁访问的近期数据,那么确实可以用单个数据库存储。不过,我们却不能预测用户要分析什么时段的数据,虽然不频繁,但远期历史数据仍然有被访问的可能性。除非在 BI 应用端做较大改动,要求用户根据访问时段选择不同的数据库,禁止跨时段分析,但这样的用户体验就有点恶劣了,而且要对 BI 系统做较大改动。
- 还有个 SQL 翻译的问题。这里采用的 BI 系统是第三方厂商提供的半商品化软件,一次分析任务只能同时接一个数据库,也就只会根据这个数据库生成相应语法的 SQL 语句。如果要同时接入两个数据库,则需要同时生成两套 SQL 语法。虽然用于多维分析的 SQL 语句都很规整,但仍然会有部分数据库特有的函数语法(特别是日期时间相关的),这又需要改造前端 BI 系统了。
- 该机构惯用的商业数据库是个行式存储数据库,即使针对较小规模的近期频繁数据也难以满足性能要求。这里需要更换成专业的列存数据仓库,但想找一个轻量级的解决方案并不很容易。
在这种场景就适合使用集算器来充当前端计算引擎。
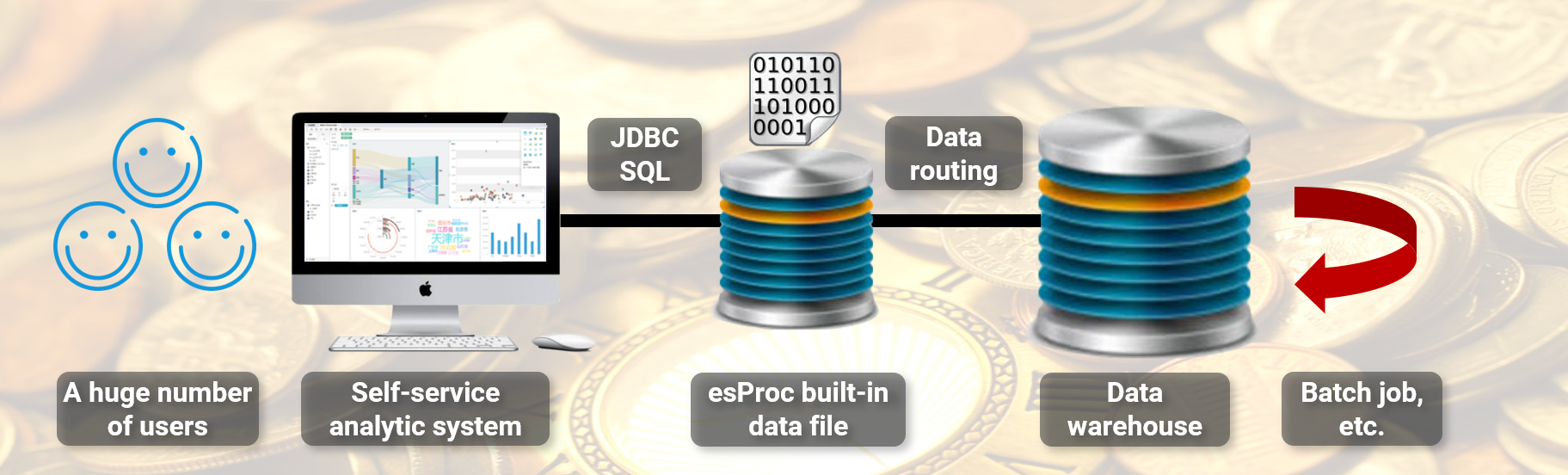
频繁访问的近期数据量不大,单台服务器已经足够存储,不必采用复杂的分布式体系;集算器的组表提供了列存压缩方案,可以提供高性能的遍历统计运算;集算器提供了简单 SQL 接口,可以直接和 BI 系统对接;上面这些都是常规数据库也能提供的,只是集算器更轻量级一些(它甚至可以直接嵌入到 BI 应用中工作)。
关键的是,集算器提供了开放的计算能力,程序员可以拿到 SQL 语句后用 SPL 分拆其中 WHERE 子句中的时间段参数,识别出该查询涉及的数据范围是哪些。如果只用到本地数据,则由集算器实施计算;如果还涉及更远期的历史数据,则仍将查询发给中央数据仓库完成计算,过程还可以用 SPL 将 SQL 语句翻译成数据仓库接受的语法,完美地实现了可编程的数据网关功能。
这样,前端 BI 系统几乎不用做修改就可以实现后台数据的冷热分离。由于绝大多数频繁访问被集算器接管,要继续转给中央数据仓库的查询请求变得非常少,整体运算性能会有大幅度提高,前端交互响应变得很顺畅。
这是个真实的案例(有个别特征进行了整理以突出典型性)。不过,这里的性能优化并没有涉及到 SPL 的算法优势,主要是应用结构方面的调整。实现这个方案,是不是采用了集算器这个产品并不重要,我们一直提倡的、要把计算从数据库中解放出来的理念才是关键的。开放的计算本身就是一个重要能力,而不是一定要和数据库绑在一起,数据计算需要自己的中间件。


英文版