


热数据缓存例程
概述
数据维护例程可以实现数据的定期维护和更新,对于实时热数据,只能在查询的时候临时读取,再和历史数据归并后返回。
这就要求实时热数据的查询能快速返回结果,且能接受频繁的并发访问,这对业务系统来说是较大的负担。如果能把实时热数据单独存储在内存中,查询时直接从内存中读取返回,就可以极大地加快查询速度,且和业务系统剥离开来,不影响业务系统的正常运行。
本例程提供的就是此场景下的解决方案。
相关术语:
数据源:原始的数据存储或产生数据的来源。
热数据:近期新产生的数据
生命周期:热数据需保留的时长,超出这个时长将被自动删除
应用方案
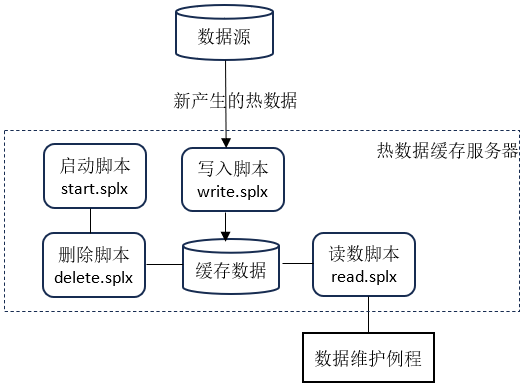
1、 写入脚本write.splx用于将新产生的热数据添加到缓存中,并同时备份到文件
2、 定期执行删除脚本delete.splx,将超过生命周期的数据自动删除,删除后的结果数据也同步备份到文件
3、 读数脚本read.splx以表名、过滤条件、排序规则为输入参数,返回满足条件的数据
4、 启动脚本start.splx在服务器启动时执行,把硬盘上备份的配置信息、表数据读入内存,并启动后台线程定期执行删除脚本。
配置信息
配置信息存储在以"HotConfig.json"命名的文件中,文件在主目录下
[{ TableName:"one", LifeCycle:60, TimeField:"tdate", SortField:"account,tdate"}, {……}, ……] |
TableName 表名
LifeCycle 生命周期,单位秒
TimeField 时间戳字段,精确到毫秒
SortField 排序字段
用户接口
start.splx
启动热缓存服务时执行,把配置信息读入内存全局变量;把硬盘上备份的热缓存数据读入内存全局变量,会自动读取缓存目录下的所有文件;启动删除线程。
输入参数:
无
返回值:
无
addConfig.splx
新增一张表的配置信息,将新表配置添加到内存全局变量,同时备份至文件。
输入参数:
config 新表的配置信息,格式为
{TableName:"…",LifeCycle:…,TimeField:"…",SortField:"…"}
返回值:
无
write.splx
将新数据添加到内存全局变量,如果原变量不存在则创建,存在则按排序字段归并;同时归并结果备份到文件
输入参数:
tbl 表名
data 新数据
返回值:
无
read.splx
根据过滤条件和排序规则,返回数据。如排序规则为空则按原序返回。
输入参数:
tbl 表名
filter 过滤条件
sort 排序规则
返回值:
满足条件的数据组成的排列
存储结构

HotConfig.json为存储配置信息的文件
backup目录下存储所有表的备份数据,其内容示例如下:

表示有两个表的备份文件,表名分别是multi和one
应用举例
某集团设计的电力监控统计系统,需要按固定频率实时采集多个传感器上测量的数据,每秒约产生20万条数据,新数据希望保留30秒才可删除。
配置文件名signal.json,内容如下:
{ TableName:"signal",
LifeCycle:30,
TimeField:"sTime",
SortField:"id,sTime"}
1、 启动热缓存服务,执行start.splx
A |
|
1 |
=call("start.splx") |
2、 添加signal表的配置信息
A |
|
1 |
{ TableName:"signal", LifeCycle:30, TimeField:"sTime", SortField:"id,sTime"} |
2 |
=call("addConfig.splx",A1) |
3、 调用write.splx,定时添加新数据
A |
|
1 |
=call("write.splx","signal",newData) |
4、 调用read.splx,获得满足条件的数据
A |
|
1 |
=call("read.splx","signal","sTime<1711987200 && sTime>=1711900800)") |
全局变量
HotConfig 配置信息
tbl 以表名作为全局变量,在内存中存储该表的所有数据
tbl 以表名作为全局锁,用于该表数据的增删,由于增删都是直接赋值,是原子操作,所以查询不加锁
代码解析
start.splx
启动热缓存服务时执行,把配置信息读入内存全局变量;把硬盘上备份的热缓存数据读入内存全局变量,会自动读取缓存目录下的所有文件;启动删除线程。
输入参数:
无
返回值:
无
A |
B |
C |
D |
|
1 |
=file("HotConfig.json") |
|||
2 |
if(A1.exists()) |
>env(HotConfig, json(A1.read())) |
||
3 |
for HotConfig |
=file("backup/"+B3.TableName+".btx") |
||
4 |
if(C3.exists()) |
=C3.import@b() |
||
5 |
>env(${B3.TableName},D4) |
|||
6 |
else |
>env(HotConfig,[]) |
||
7 |
=call@nr("delete.splx") |
|||
A1 存储配置信息的文件
A2 如果文件存在:
B2 读取配置信息,赋值给全局变量HotConfig
B3 按配置信息的行循环,每行对应一张表:
C3 当前表的备份文件
C4 如果备份文件存在:
D4 读取备份文件的数据
D5 将数据赋值给以表名命名的全局变量
A6 否则:
B6 将空序列赋值给全局变量HotConfig
A7 启动删除线程
addConfig.splx
新增一张表的配置信息,将新表配置添加到内存全局变量,同时备份至文件。
输入参数:
config 新表的配置信息,格式为
{TableName:"…",LifeCycle:…,TimeField:"…",SortField:"…"}
返回值:
无
A |
|
1 |
=env(HotConfig,HotConfig|config) |
2 |
=file("HotConfig.json").write(json(HotConfig)) |
A1 将新表的配置信息添加到全局变量HotConfig中
A2 将配置信息备份到文件
delete.splx
自动删除时长超过LifeCycle的数据,每n秒运行一次,删除后的结果备份到文件
输入参数:
n 删除间隔,单位秒
返回值:
无
A |
B |
C |
|
1 |
for HotConfig |
||
2 |
if ifv(${A1.TableName}) |
||
3 |
=${A1.TableName}.select(long(now())-${A1.TimeField}>${A1.LifeCycle}*1000) |
||
4 |
=lock(A1.TableName) |
||
5 |
=env(${A1.TableName},${A1.TableName}\C3) |
||
6 |
=file("backup/"+A1.TableName+".btx").export@b(${A1.TableName}) |
||
7 |
=lock@u(A1.TableName) |
||
8 |
=sleep(n*1000) |
||
9 |
goto A1 |
||
A1 按全局变量HotConfig循环
B2 如果以当前表命名的全局变量存在:
C3 选出时长超过LifeCycle的数据
C5 将时长超过LifeCycle的数据删除后,剩余的数据赋值给以当前表命名的全局变量
C6 将剩余数据备份到文件
write.splx
将新数据添加到内存全局变量,如果原变量不存在则创建,存在则按排序字段归并;同时归并结果备份到文件
输入参数:
tbl 表名
data 新数据
返回值:
无
A |
B |
|
1 |
=HotConfig.select@1(TableName==tbl) |
|
2 |
if(A1) |
=lock(tbl) |
3 |
>if(!ifv(${tbl}),env(${tbl},data),env(${tbl},[${tbl},data].merge(${A1.SortField}))) |
|
4 |
=file("backup/"+tbl+".btx").export@b(${tbl}) |
|
5 |
=lock@u(tbl) |
|
6 |
else |
end tbl+"不存在" |
A1 选出当前表的配置信息
A2 如果当前表存在:
B3 如果以当前表名命名的全局变量存在,则将新数据和原数据按排序字段归并后重新赋值给全局变量,否则将新数据直接赋值给全局变量
B4 将全局变量里的数据备份到文件
read.splx
根据过滤条件和排序规则,返回数据。如排序规则为空则按原序返回。
输入参数:
tbl 表名
filter 过滤条件
sort 排序规则
返回值:
满足条件的数据组成的排列
A |
B |
C |
|
1 |
if ifv(${tbl}) |
=${tbl}.select(${filterExp}) |
|
2 |
if(sortExp) |
>B1=B1.sort(${sortExp}) |
|
3 |
return B1 |
||
4 |
else |
return null |
A1 如果以当前表名命名的全局变量存在:
B1 将当前表的数据按过滤条件过滤
B2 如果排序表达式不为空,则将过滤结果再按排序表达式排序
B3 返回过滤排序后的结果


英文版