


求助: 集算器测试 TPCH(Q9) 时发现的问题
大佬们,我在学习这篇文章的时候: 用 TPCH 练习性能优化 Q9 发现用 SQL 得到的结果跟用集算器得到的结果不同(我用的是 TPCH dbgen(sf=1) 的数据量)。
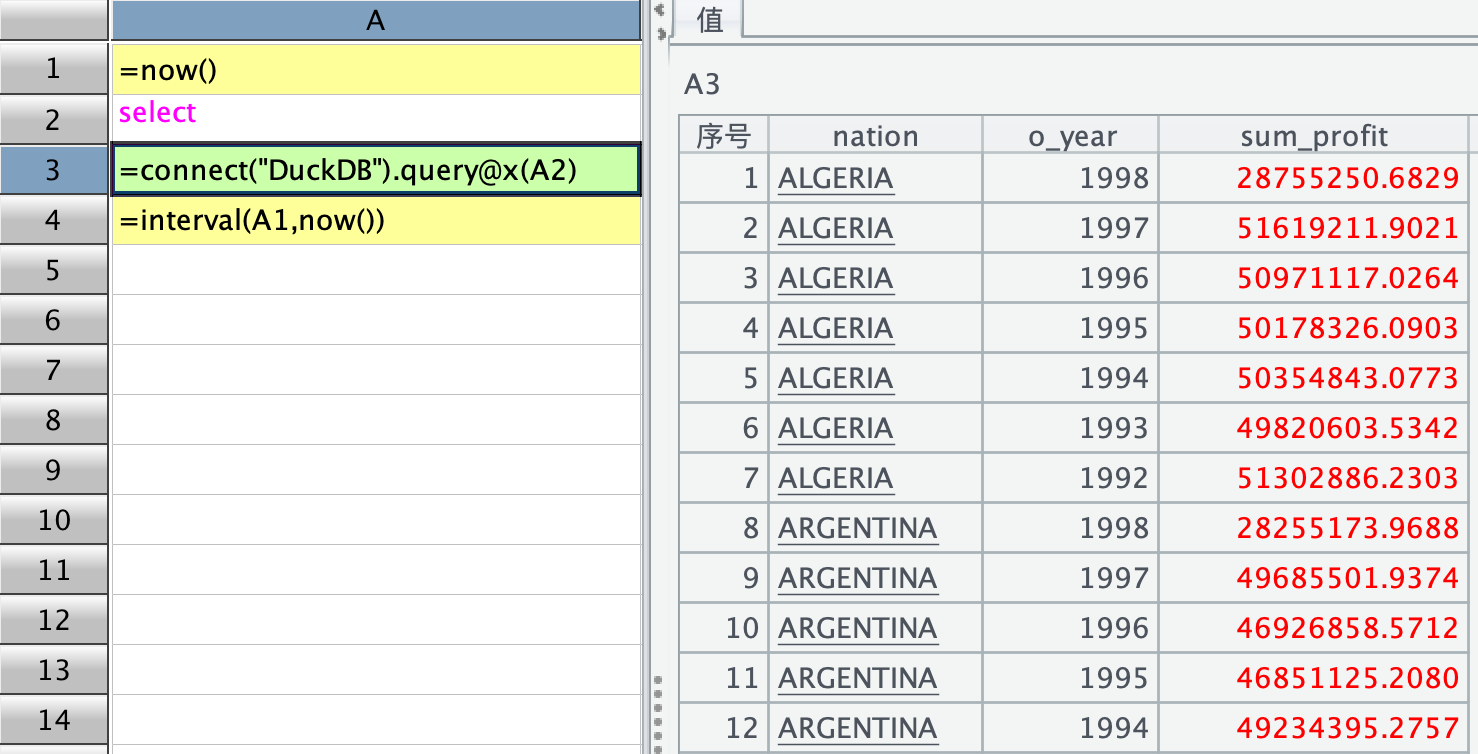
如下所示,SQL 结果是这样的,下图中 A2 所在格子的语句就是文章中提供的 SQL 语句:
然后,用文中提供的 SPL 语句得到的结果比上述 SQL 结果要小很多,如下所示:
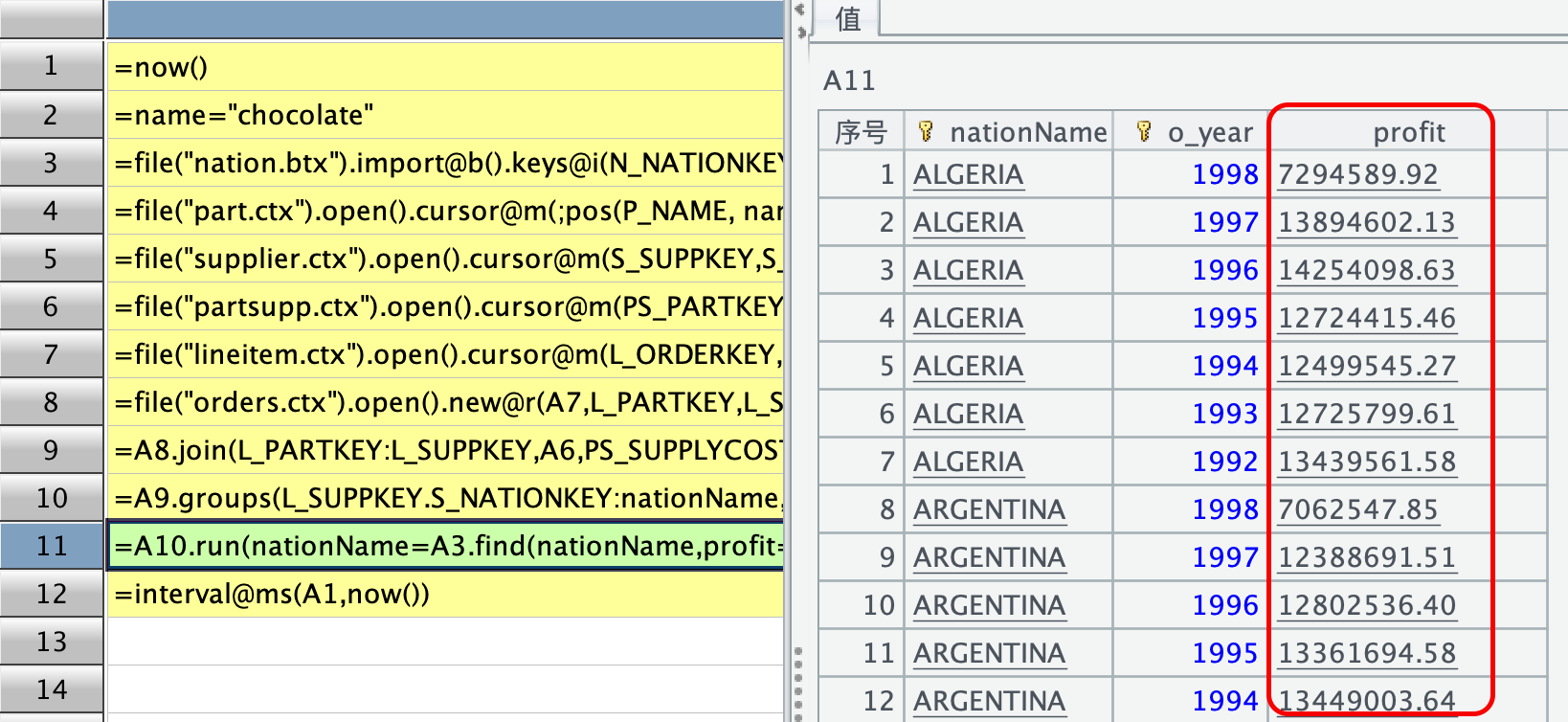
我排查之后发现,极有可能是 A8 所在的代码格中 new@r()出现问题了,过滤掉了一部分有效的数据。按本例中测试数据量来说,orders 表有 150 万行,A7 中 lineitem 表过滤后有 32 万 8370 行,但经 A8 中的 new@r() 关联过滤之后只剩下 8 万 7716 行。此例中,orders 表是主表,lineitem 表是 orders 的子表,按照主表.new@r(子表) 的功能来看,结果集的行数应该不可能少于子表的行数,我也搞不清楚,只是无根据地猜测 new@r() 过滤掉了部分有效的数据。我按照 SPL 语句的意思,推测 A8 中的主子关联最终目的是为了得到 orders 表中的 O_ORDERDATE 列,于是从 A8 开始用 join 重新写了 SPL,此时得到的结果跟 SQL 跑出来的结果是一样的,截图和 SPL 语句如下:
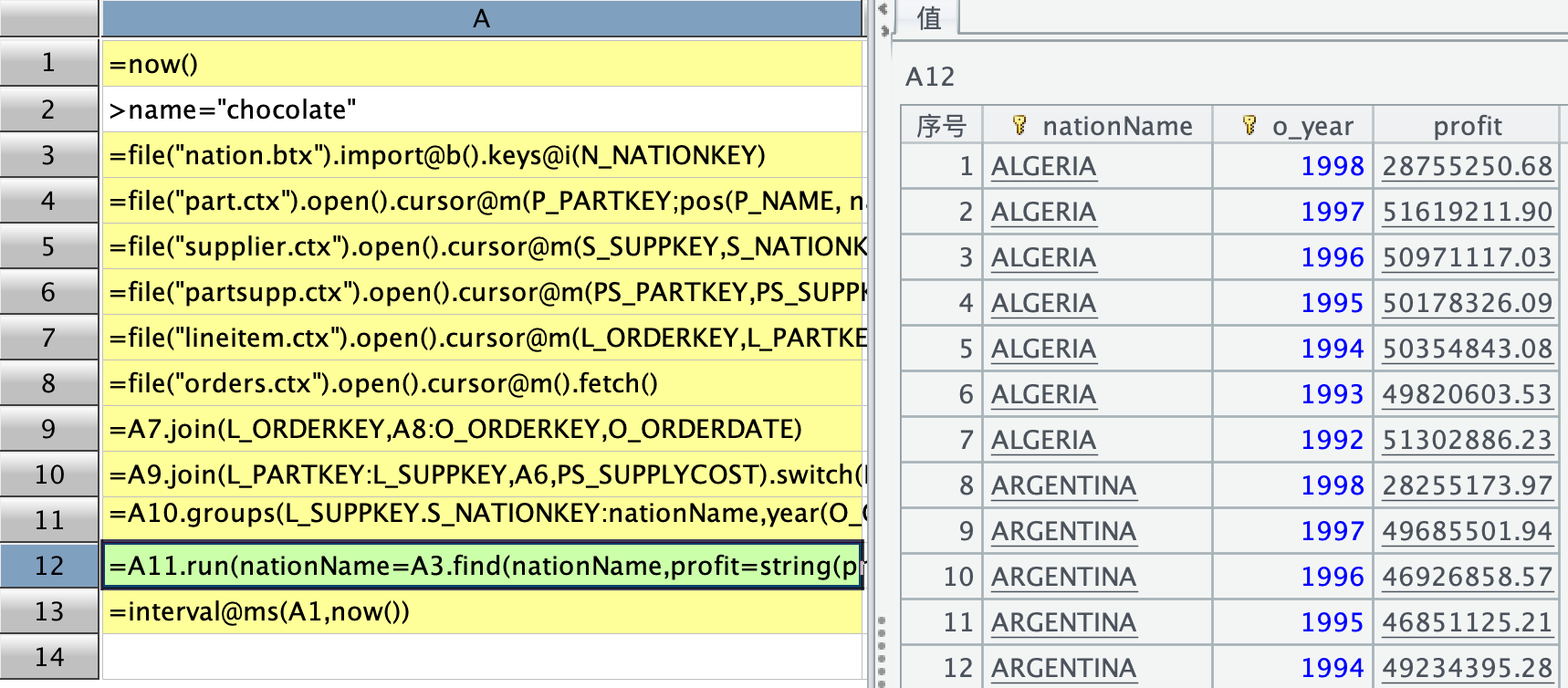
| A | |
| 1 | =now() |
| 2 | >name="chocolate" |
| 3 | =file("nation.btx").import@b().keys@i(N_NATIONKEY) |
| 4 | =file("part.ctx").open().cursor@m(P_PARTKEY;pos(P_NAME, name)).fetch().keys@im(P_PARTKEY) |
| 5 | =file("supplier.ctx").open().cursor@m(S_SUPPKEY,S_NATIONKEY).fetch().keys@im(S_SUPPKEY) |
| 6 | =file("partsupp.ctx").open().cursor@m(PS_PARTKEY,PS_SUPPKEY,PS_SUPPLYCOST;A4.find(PS_PARTKEY)).fetch().keys@im(PS_PARTKEY,PS_SUPPKEY) |
| 7 | =file("lineitem.ctx").open().cursor@m(L_ORDERKEY,L_PARTKEY,L_SUPPKEY,L_QUANTITY,L_EXTENDEDPRICE,L_DISCOUNT;A4.find(L_PARTKEY)) |
| 8 | =file("orders.ctx").open().cursor@m().fetch() |
| 9 | =A7.join(L_ORDERKEY,A8:O_ORDERKEY,O_ORDERDATE) |
| 10 | =A9.join(L_PARTKEY:L_SUPPKEY,A6,PS_SUPPLYCOST).switch(L_SUPPKEY,A5) |
| 11 | =A10.groups(L_SUPPKEY.S_NATIONKEY:nationName,year(O_ORDERDATE):o_year;sum(L_EXTENDEDPRICE*(1-L_DISCOUNT)-PS_SUPPLYCOST*L_QUANTITY):profit) |
| 12 | =A11.run(nationName=A3.find(nationName,profit=string(profit,"0.00")).N_NAME).sort(nationName,-o_year) |
| 13 | =interval@ms(A1,now()) |
但又出现了另一个问题,上述代码格 A8、A9 中,A8 所在的 orders 是主表,也是维表,有 150 万行,相对于 A7 中 32 万多行的结果来说,符合较小事实表与大维表关联的场景,于是就琢磨着用游标.joinx@cq(关联字段,实表: 关联字段,实表中的字段) 来写,代码如下:
| A | |
| 1 | =now() |
| 2 | >name="chocolate" |
| 3 | =file("nation.btx").import@b().keys@i(N_NATIONKEY) |
| 4 | =file("part.ctx").open().cursor@m(P_PARTKEY;pos(P_NAME, name)).fetch().keys@im(P_PARTKEY) |
| 5 | =file("supplier.ctx").open().cursor@m(S_SUPPKEY,S_NATIONKEY).fetch().keys@im(S_SUPPKEY) |
| 6 | =file("partsupp.ctx").open().cursor@m(PS_PARTKEY,PS_SUPPKEY,PS_SUPPLYCOST;A4.find(PS_PARTKEY)).fetch().keys@im(PS_PARTKEY,PS_SUPPKEY) |
| 7 | =file("lineitem.ctx").open().cursor@m(L_ORDERKEY,L_PARTKEY,L_SUPPKEY,L_QUANTITY,L_EXTENDEDPRICE,L_DISCOUNT;A4.find(L_PARTKEY)) |
| 8 | =file("orders.ctx").open() |
| 9 | =A7.joinx@cq(L_ORDERKEY,A8:O_ORDERKEY,O_ORDERDATE) |
| 10 | =A9.join(L_PARTKEY:L_SUPPKEY,A6,PS_SUPPLYCOST).switch(L_SUPPKEY,A5) |
| 11 | =A10.groups(L_SUPPKEY.S_NATIONKEY:nationName,year(O_ORDERDATE):o_year;sum(L_EXTENDEDPRICE*(1-L_DISCOUNT)-PS_SUPPLYCOST*L_QUANTITY):profit) |
| 12 | =A11.run(nationName=A3.find(nationName,profit=string(profit,"0.00")).N_NAME).sort(nationName,-o_year) |
| 13 | =interval@ms(A1,now()) |
但结果中出现了 null:
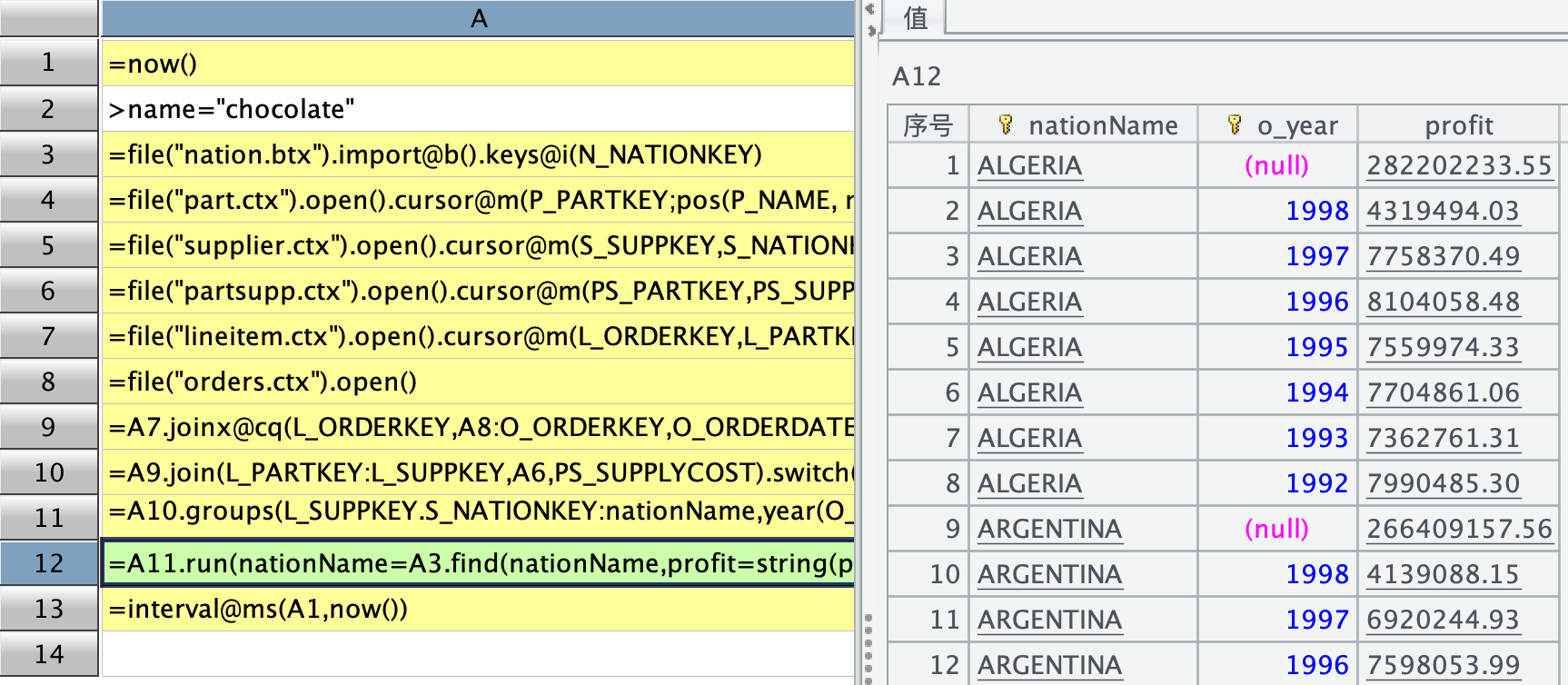
经排查后发现,这些 null 实际上是在 joinx@cq 时没有关联上数据,在 A9 中随便找一个 null 对应的日期值去 orders 表里查,都能查得到。还有一点,这种方法得到每一个 nationname 对应的 profit 总量跟 SQL 跑出来的结果是一样的,所以,猜测 joinx@cq 时有部分有意义的数据没有关联上。
所以,我求助的问题是:
1、new@r 在本例中要如何使用才能得到跟 SQL 一样的结果?(当然也有可能是 SQL 结果出错了)
Q18 中 用 TPCH 练习性能优化 Q18 也有用 new,结果比 SQL 少了 5 行。用 join 时跟 SQL 执行结果一致。
2、小事实表.joinx@cq(大维表) 时,是不是会缺失关联数据?(也有可能是我用错了)
不管怎样,结果有出入。
恳请大佬们有空时帮忙看看这个 Q9 案例和涉及到的关联用法 new@r、joinx@cq,给予指导解惑,谢谢!
本案例测试数据集用的是 TPCH(sf=1),数据不多,但不好打包上传。需要的话请加我 QQ:12674014,烦请备注集算器字样。


你的 QQ:12674014 搜不到。加我 QQ 吧,65002112
大佬们,实在抱歉,关于第一个问题new@r ,是我操作失误摆了乌龙。
经 liwei 大佬指点,主子表 new@r 时要求 orders 表和 lineitem 表对主键有序。
我重新生成排序后的 orders 表,SPL 和 SQL 结果就一致了 (我记得当时也都是排序后生成的 ctx 文件)。
第 2 个问题 joinx@cq 还是会有 null 值出现,不知道哪里用错了。恳请大佬们得闲时再帮忙看看🙏
大佬们,帖子中第二个问题 joinx@cq,我好像找到问题了:
1、按照官方函数文档中的说明,需要用游标 cs.joinx@cq(C:…, 实表外键) 进行外键关联,其中参数 C 是游标 cs 中的字段,当 cs 对 C 有序时,可以用选项 @c 来提升速度。都没问题,A7 中的源文件 lineitem 是对主键有序的,但用了多路游标 ctx.cursor@m(,filter) 过滤之后,是不是就会被认为无序了?所以此时用 joinx@cq 时就会因为无序而得到 null 值。如果不用多路游标 cursor@m,直接写成 ctx.cursor(,filter),joinx@cq 就会认为过滤后的 cs 是有序的就会得到正确结果。
2、实际上 joinx 的对象也可以用序表,序表.joinx@cq(C…, 实表外键),也就是说如果把上述 A7 经多路游标 cursor@m() 之后 fetch 出来,joinx@c 也会认为数据是有序的,也能得到正确结果。
所以,问题出在 cursor@m 多路游标这里,要么用 cursor@m().fetch().joinx@cq(, 实表), 要么 cursor().joinx@cq(, 实表),要么不要使用 @c 选项。
就是这么个情况,恳请大佬测试确认一下🙏