


求助: 集算器的数值显示问题
大佬们,麻烦看一下这样的数值显示是否正常?
比如,在集算器 IDE 格子中输入一些数值,会发现一个问题,只要是千万级以上,再带上小数点的,不管小数点后是 00 或者是有意义的数,就会显示成科学计数,如下图中 A2:A4 所示。如果是小于千万级的小数和其它整数都会正常显示,我说的正常是所见即所得,如下图中的 A6:A9 所示。

如果要想科学计数正常显示,必须要用 decimal 转换类型,float,number 均不能达到效果。
这种 "所见非所得" 的数值显示形式在实践中会带来两个问题:
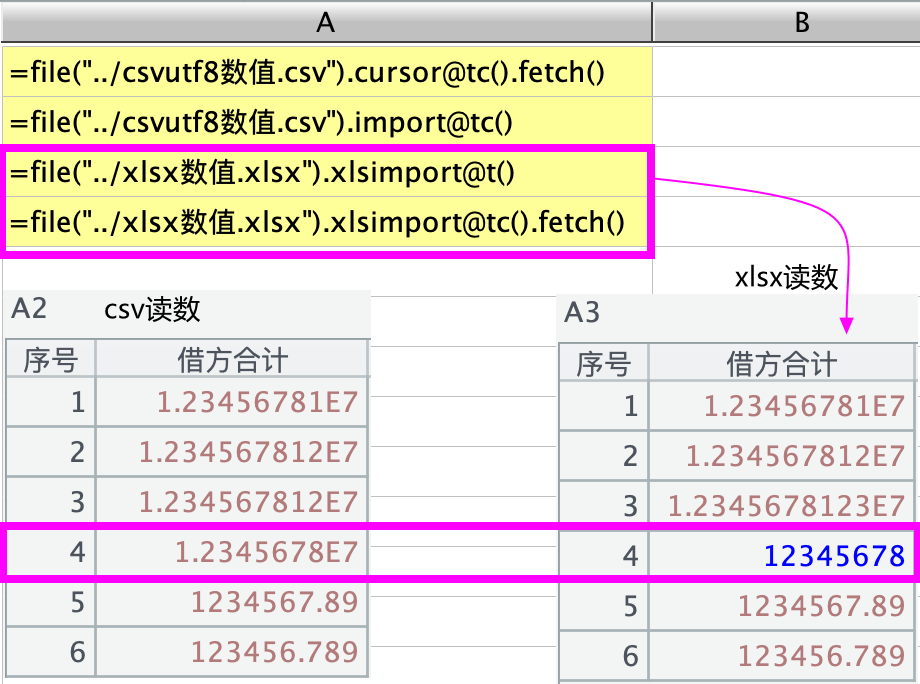
1、读取文件时的显示问题。如果从文件读取这部分数据,xlsx 格式也好,csv 格式也好,也会显示成这种科学计数的效果,如下图所示。稍有不同的是从 excel 文件读取时,会把千万级整数正常显示,而从 csv 文件读取时会把千万级整数解析成带小数点 00 的数,从而显示成科学计数的形式。可以从下图中的 A4 带红框处观察结果:
2、输出文件时,会变成科学计数的形式输出,如下图所示,右边的文件是由左边的输出转存得到的,txt 也是类似的效果:
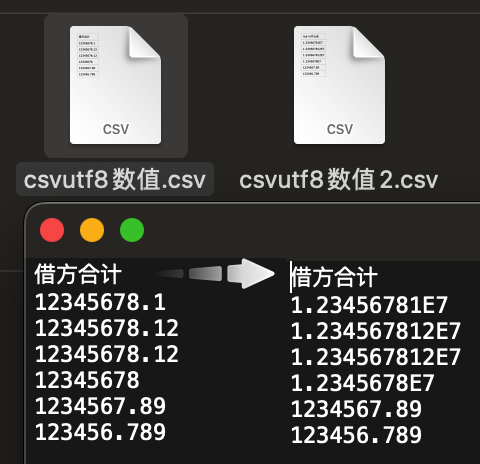
所以,In my humble opinion,这样的显示形式不是很方便,况且也只是个千万级的小数形式,这种量级的数值在实践中还是蛮普遍的。
为什么会纠结于值的显示形式?最近要把一些 csv 文件转码成 utf-8 编码导入数据库,因为数据库只接受 utf-8 编码的 csv 文件。市面上一些转码软件很不靠谱,总有识别不了的字符,导致过程中总有一些让人崩溃的事情出现。辗转求助于 SPL,使用打开 csv 再转存为 utf-8,虽然这种打开后再转存的方法不是很高明,但像 powershel 的 get-content 也是一行一行读,慢的很。还有 iconv 专门用于转码的命令也靠不住,很多识别不了的字符。SPL 很靠谱,在效率和转码问题上都很靠谱,关键时刻起到了 "救命" 的作用。唯一有个瑕疵就是数值的显示,总会变成科学计数的形式。导入后按一个表一个表去改,显然这种方法是不科学的,属于 choiceless choice,同样的,在源头一列一列去改,也是不科学,不知道数值列到底是哪些,起不到批量处理的作用。
再顺带另一个显示问题,在读取 excel 文件时,用 xlsimport@t 直接取取出来,数值显示正常:
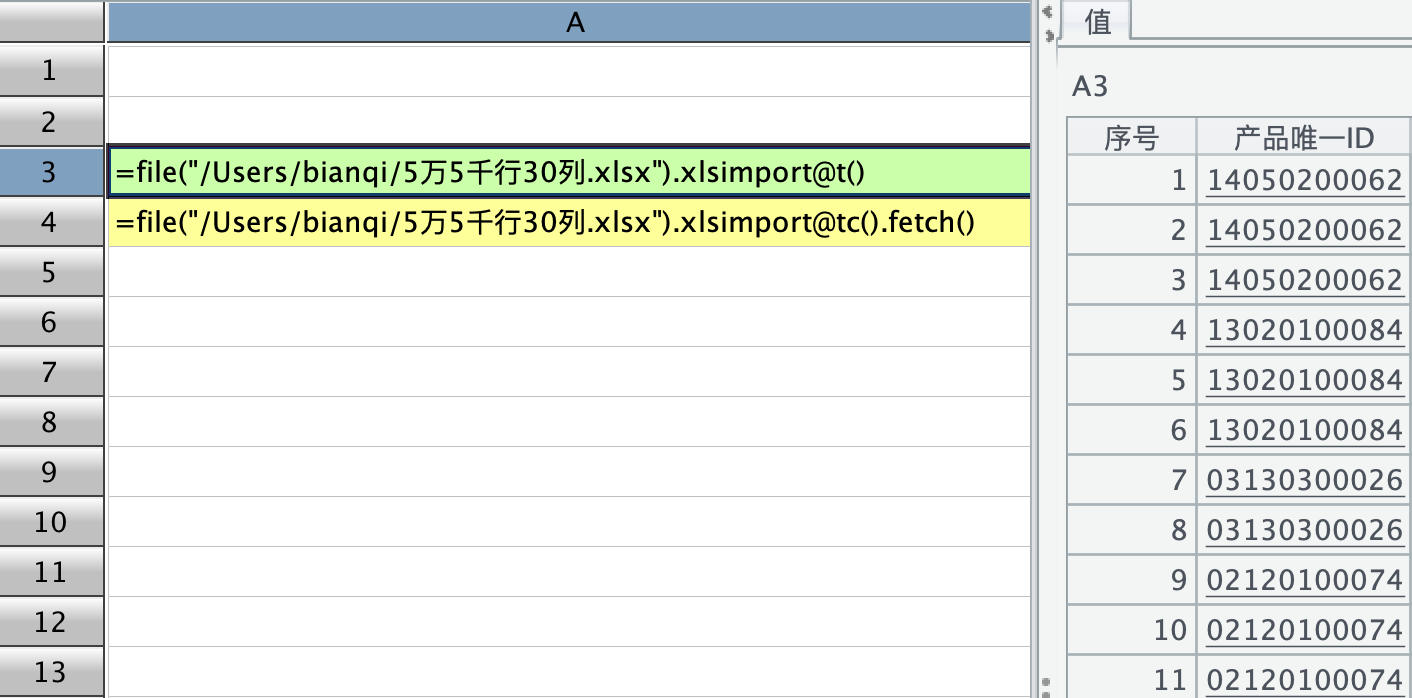
然后用,xlsimport@tc().fetch(),读成游标的形式再 fetch 出来时,显示就变了,好像 fetch 会 parse 解析:
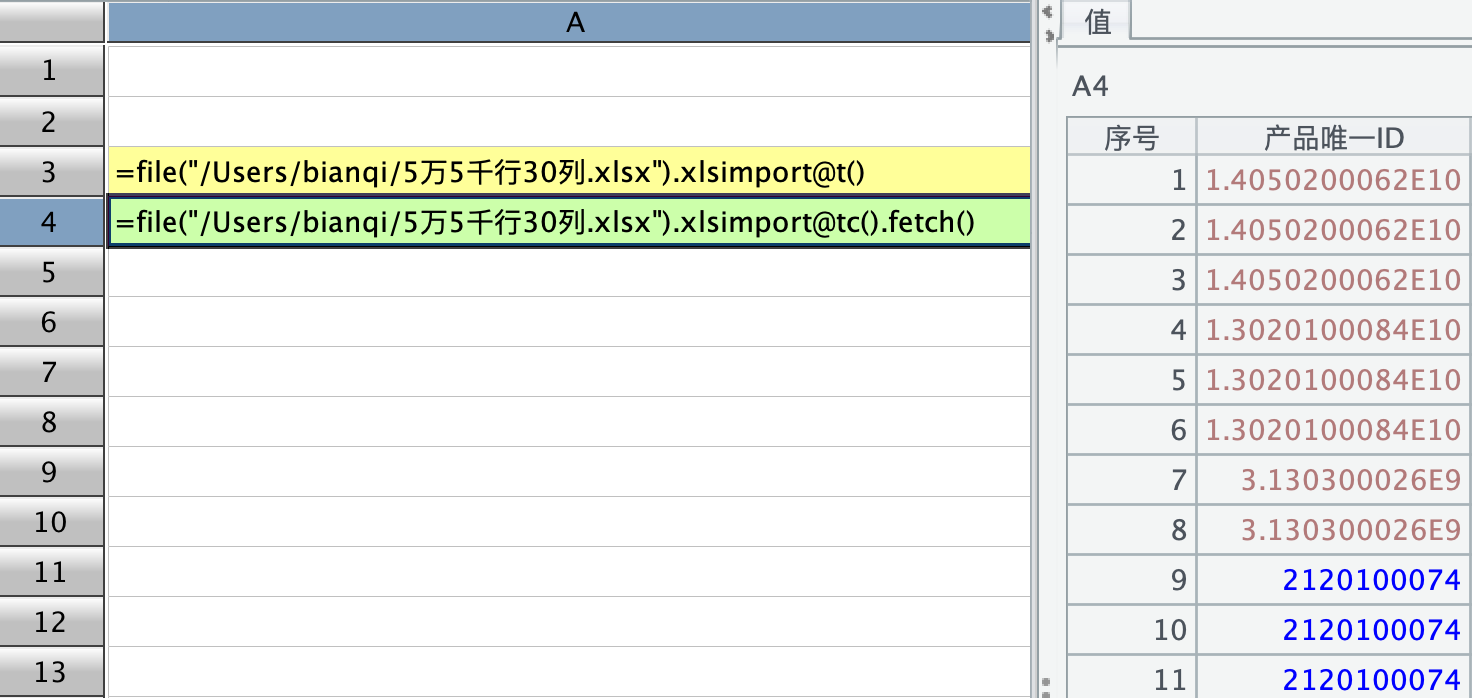
恳请大佬们得闲时看看上述千万级带小数数值显示的问题,给予指导帮助🙏 谢谢!


因为 csv 文件本身没有数据类型,为了优化解析速度,在类型解析时会优先参照上一行的同一列的数据的数据类型。
也就是说如果 a 列第一行的值是 12.3,第二行的值是 22,则第一行的值会被解析成 double,第二行会优先按照 double 来解析 22。
先回复其中关于 xlsimport 的两个问题。
1) f.import 和 f.xlsimport 导入后整数那行类型不同。
是因为导入 csv 时,如果没有指定列类型,会优先使用第一行的数据类型。比如 12345678 是整数,也可以解析成第一行的数据类型 Double。
而 excel 每个单元格都有独立的单元格属性,没有使用导入文本文件的策略,是每个格子独立解析的。
2) f.xlsimport()和 f.xlsimport@c().fetch() 结果不同。这个应该是程序有问题,会尽快修复。
double 的显示值 java 会根据数值的大小采用不同的方式,在数值较大时会采用科学计数法。
显示值对于集算器来说是不重要的,只是调试的时候才会参照一下
@leavedy
感谢大佬回复🙏
double 类型小数点前位数超过 7 位就会显示成科学计数,也就是千万级的 double 都会自动显示成科学计数,而超大整数又不会显示成科学计数。这个对前端不友好 (不晓得说的对不对哈),我说的前端就是用户看得到的界面(my two cents:所见即所得总归是好的)😄
@WuNan
感谢大佬关注🙏
关于 xlsimport 我还发现一个问题,比如上了一定行数 (几万行几十列) 的 xlsx 文件,用 xlsimport@t 直接读取时会比先游标后 fetch 的方法 xlsimport@c().fetch()要慢。我试了好几次,都有这样的现象,有时直接 xlsimport 会死机,而游标 fetch 又没有问题,至少能 fetch 出来。
整数不会采用科学表示法,只有浮点数才有可能采用科学表示法,jdk 就是这么做的我们也无能为力。
如果 csv 文件里的数字串采用科学表示法能够上传到数据库的话就忽略这个问题了,如果不能再想办法。
xlsimport@c 更快这个现象是正常的。
xlsimport@c 是通过解析 xml 文件来获取数据的,游标形式内存占用较小。cursor.fetch 会将数据全部读入内存,能 fetch 成功说明你的数据可以全部放到内存中。SPL 支持游标计算的,通常不用将全部数据内存化。
普通的 xlsimport 是将 excel 文件对象化,而不仅仅是数据,所以内存占用非常大,大数据量时不建议使用。
谢谢大佬,不操心了,我想其它路子解决。😄
csv 真的是用户不友好的典范😄(DuckDB 这个数据库 read_csv 时设计了 28 个参数来解析 csv😄)
Get it,谢谢大佬指点解惑🙏 我老白问题比较多,哈哈😄
@WuNan
大佬,下午好,我看到程序 jar 包有更新,发现 xlsimport@tc().fetch() 有了改变,但跟 xlsimport@t() 还是不一样,游标 fetch 之后会把文本串中的前导 0 给整没了,以下截图供参考:
请问这样显示是行还是不行?
测试的 excel 文件中是怎么设置 0 开头的数值的?
我试了下直接输入 03130300026,excel 自动把开头的 0 给去掉了。
设置单元格类型为文本,xlsimport 和 fetch 都会读取成字符串。
@WuNan 大佬,不好意思,没有问题了。
我真服了 excel 这个老六,原始文件必须打开后保存一下,然后就没有问题了。如下图所示,从左至右分别是原始 excel 文件,中间的是没有打开保存后 fetch 出来的格式,最右边是打开,啥也不干,再保存后 fetch 出来的格式。哎…各种无语…微软自己的 PowerQuery 对有些 excel 文件也要打开一次后保存才能正常读。
谢谢大佬,周末愉快!🙏
明白了。不客气!