


数据维护例程
概述
组表是SPL重要的文件存储格式。为保证高性能,组表常常要求数据有序存储,但数据的产生次序通常和组表要求的次序不同,在维护组表数据时需要调整数据的次序。另外,组表在写入时不能同时读取,而有些查询计算任务在数据维护期间不能停机,也需要有相应的手段来保证。
本例程将给出上述问题的解决方案。
相关术语:
单组表:数据存在一个组表文件中。
复组表:数据存入多个分表中,形成复组表。
追加型:数据只会追加,不会修改、删除。
更新型:数据可能增加、修改、删除。
冷模式:查询服务会定期停机,期间可进行数据维护。
热模式:查询服务不停机,数据维护必须同时进行。
数据源:原始的数据存储或产生数据的来源。
新数据:将被追加和更新进现有组表的新产生数据。
热数据:最后一次数据维护时刻之后产生的实时新数据。
混乱期:由于各种(网络)延迟原因导致最近一段时间内产生的新数据未必全进了数据源,此时读取数据源新数据的时候很可能读不全,这段时间的长度称为混乱期。即混乱期之前的数据一定都可以从数据源中读出。
场景说明
应用特征
1. 支持追加型和更新型,追加型的组表无主键,可以有维字段;更新型的组表有主键,用于修改和删除。
2. 新数据来源可以从外部数据源读取,按指定规则编写新数据脚本,可能返回序表或游标以适应不同规模的新数据
3. 复组表分层:将数据按时间区间分层存储,比如当天之前的数据按一天一个分表存储,当天的数据按一小时一个分表存储,当前小时的数据按10分钟一个分表存储,这样就把分表分成了日、时、分钟三层。日层称为最高层;分钟层称为最低层,也是数据直接写入的层,所以也称写入层。小时层则是中间层。日层分表的时间区间是一天,小时层分表的时间区间是一小时,分钟层的时间区间是10分钟。完整的数据由当天之前的日分表、当天之内的小时分表和当前小时的分钟分表构成的复组表。
4. 例程中提供查询脚本,以时间区间作为输入参数,查询出与时间区间有交集的分表构成复组表对象返回;更新型不需要时间参数,直接返回所有分表构成的复组表对象。查询时可以附加热数据,但只支持小量数据(序表),调用按指定规则编写的热数据脚本可获取热数据。
5. 更新型多分表时,提供手动归并脚本,将已完成的分表归并进第一个分表(称为主分表)。
6. 新表初次维护前,或者间隔太长时间没有维护,需要先调用初始化脚本,将历史数据一次性写入组表,然后才能启用查询服务,进行正常的周期运行。
冷模式
1. 查询服务的停机时长足够完成一次数据维护。
2. 支持单组表和复组表,总数据量小到重写整个组表时间短于数据维护时间段时,可以使用单组表。
3. 复组表时,分表按月划分时间区间,只有一层。
4. 两次数据维护的间隔原则上不短于一天(可以更长)。例程中提供冷更新脚本以主动调用发起维护动作。
5. 新数据也可以来自准备好的文件,依旧由新数据脚本根据时间参数选择和读取文件并返回序表或游标。
热模式
1. 数据维护期间组表可被访问,需要有相应的手段保证数据的访问不出错。
2. 两次数据维护的间隔可能短到分钟级。
3. 只支持复组表,无论数据量大小。
4. 数据分层:为了在维护周期内尽快完成数据的维护,设计将数据分层存储,由写入线程将新数据快速写入最低层分表,分表很小,能在维护周期内快速完成新数据的写入。
5. 由归并线程将最低层分表归并入中间层分表,完成即可启用新的中间层分表,原有最低层分表可删除。归并线程完成最低层分表归并后,会继续将中间层分表往最高层分表归并,完成后启用新的最高层分表,原有中间层分表可删除。
6. 写入层次和写入周期:新数据直接写入的分表的时间区间单位称为写入层次。比如,数据每10分钟写入一次,分表的时间区间为10分钟,那么写入层次就是分钟,写入周期就是10,写入周期始终以写入层次作为时间单位。写入层次支持秒、分钟、小时、日。
7. 最高层次:分表被逐层向上归并成大分段区间分表,最高层分表的时间区间单位称为最高层次。比如,最高层分表的时间区间为一个月,则最高层次就是月。最高层次支持日、月。当最高层次是月时,向日层归并的时候,日分表的数据直接归并入对应的月分表,日分表并不实际存在。
8. 本例程不支持处理混乱期之前的遗漏数据,读数时只读取混乱期之前产生的数据,数据源将保证混乱期前的数据是完整的。
9. 提供一个启动脚本,同时启动写入线程和归并线程,分别根据数据的写入周期和归并周期,循环执行数据的写入和归并。
应用结构图
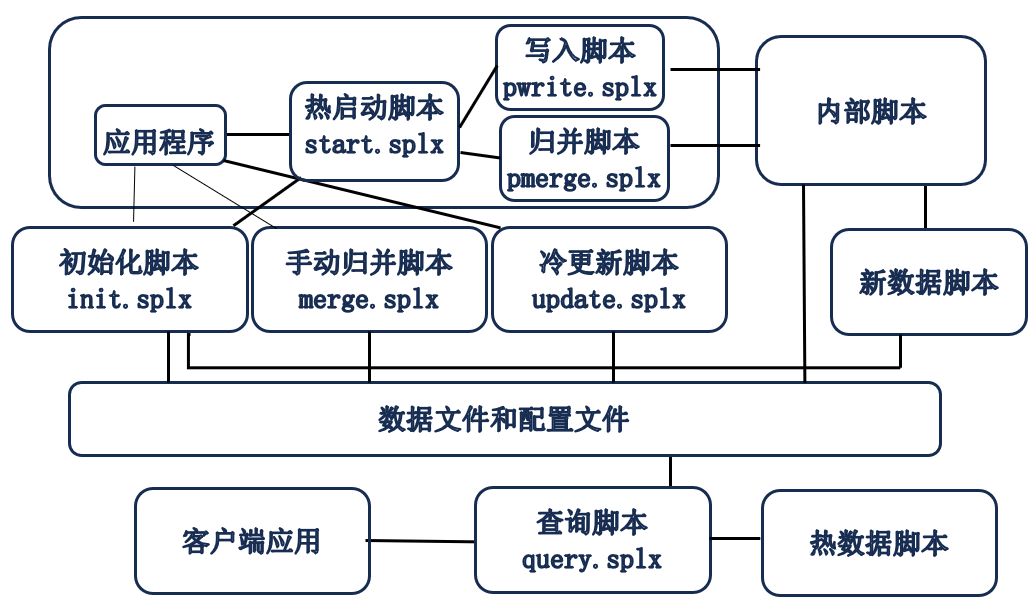
计算脚本:查询脚本query.splx,维护脚本init.splx,merge.splx,update.splx和内部脚本,以及用户编写的新数据和热数据脚本统称为计算脚本。
主程序:应用程序、热启动脚本start.splx、写入脚本pwrite.splx、归并脚本pmerge.splx统称为主程序,始终运行在一个进程中,在应用程序所在进程部署一套即可。
单进程模式:主程序和计算脚本运行在同一进程中。
多进程模式:主程序和计算脚本分别运行在不同进程中,每次执行计算脚本的服务器可能是临时分配的。多个进程均可访问到数据源,并共享某套存储,生成的组表将会上载到共享存储中,供其它进程中的查询脚本访问。
内部维护脚本:包括zoneT.splx, zoneZ.splx, writeHistory.splx, writeHot.splx, mergeHot.splx, modConfig.splx,这些脚本和用户接口init.splx, update.splx, merge.splx, query.splx以及用户实现的新数据脚本、热数据脚本部署在一起。
数据文件和配置文件:只部署一套,多进程模式下共享。
用户接口
配置信息
配置文件名:表名.json
| [{ "Filename":"test.ctx", "DataPath":"test/", "DimKey":"account,tdate", "TimeField":"tdate", "OtherFields":"ColName1,ColName2", "NewDataScript":"read1.splx", "HotDataScript":"read2.splx", "LastTime":"2024-01-01 00:00:00", "Updateable":true, "DeleteKey":"Deleted", "Zones":null, "ChoasPeriod":5, "DiscardZones":null, "WritePeriod":5, "MultiZones":true, "WriteLayer":"s", "HighestLayer":"M", "BlockSize":{"s":65536,"m":131072,"H":262144, "d":1048576} 或者1048576 }] |
"Filename":组表文件名,SPL约定分表物理文件名为 分表号.Filename
"DataPath":组表存储路径
"DimKey":组表的维字段,即组表会按这些字段排序,更新型时用作主键,有多个字段时用英文逗号分隔
"TimeField":时间字段,读数脚本用时间字段过滤出满足传入时间区间的数据
"OtherFields":其它字段名,有多个时用英文逗号分隔
"NewDataScript":读新数据的脚本文件名
"HotDataScript":读热数据的脚本文件名,如果查询时不需要热数据,则此参数置空
"LastTime":最后读数时间,初始值填历史数据的起始时间,执行写入脚本时会自动修改,一旦开始使用,此配置信息不可再次修改
"Updateable":是否更新型,未填或填false表示追加型,如果填true,还需要配置:
"DeleteKey":组表的删除标记字段名,如果不需要删除,则置空
"Zones":分表号列表,程序自动产生,初始配置成null
"MultiZones": true表示复组表,false表示单组表,如果填true,还需要配置:
"WriteLayer":写入层,分别用字母s,m,H,d代表秒、分钟、小时、天
"HighestLayer":最高层,分别用字母d和M代表天和月
"BlockSize":分表创建时的区块大小。当MultiZones为true时需按层设置,设置格式为{"s":65536,"m":131072,"H":262144, "d":1048576};当MultiZones为false时设置单值,如1048576。低层分表数据量小,区块设小点节约内存;高层分表数据量大,区块设大点读数快。最小一般不小于65536,最大不超过1048576,单位是字节
"ChoasPeriod":混乱期,单位秒,热模式下必须配置此参数,冷模式置为null,如果热模式,还需要配置:
"DiscardZones":被归并结束等待删除的分表号列表,程序自动计算,初始配置为null
"WritePeriod":写入周期,单位是写入层,给start里的循环调用脚本使用
新数据脚本
用户需要实现的读数脚本,被写入脚本调用,返回指定表、时间区间(一般为左闭右开,可自行根据业务需求决定)内的所有新数据。
根据业务需求,可以从数据库等原始的数据来源读取数据,也可以从准备好的数据文件等地方读取。如果从数据库读取,请根据配置信息中的时间字段名以及此脚本传入的时间区间参数过滤数据;如果从数据文件读取,请根据表名、传入的时间区间匹配数据文件名。
数据的字段顺序,根据前述的配置信息,由(DimKey|DeleteKey)&TimeField&OtherFields组成,为保证字段顺序一致,建议从配置文件中读出。
数据要求按配置信息中的DimKey排序。
输入参数:
tbl 表名
start 起始时间
end 结束时间,缺省为当前时刻
返回值:
传入时间区间内的数据组成的序表或游标。
热数据脚本
和新数据脚本接口一致。
初始化脚本init.splx
新表初始化,或补写历史数据(新表或中断维护较长时间)。冷模式下需要主动发起调用;热模式下会由start.splx自动调用。
输入参数:
tbl 表名
热模式启动脚本start.splx
热模式启动脚本,先调用初始化脚本,如新表初次使用或者中断维护时间过长,会自动补写数据;然后分别启动写入线程和归并线程,根据配置信息周期性执行写入和归并。本脚本和pwrite.splx、pmerge.splx必须运行在一个进程中,共享全局变量。
输入参数:
tbl 表名
冷更新脚本update.splx
以上一次的读数截止时间和这次新传入的读数截止时间作为输入参数去调用新数据脚本,获得新数据。用上一次的读数截止时间算出新的分表号,将原分表和新数据归并后写入新分表,然后删除原分表。如果是月初且需要多分表时,则直接启用新分表。此脚本只能在查询服务停机的时候执行。
输入参数:
tbl 表名
end 读数截止时间
手动归并脚本merge.splx
更新型多分表时,将传入时间之前完成的月分表归并入主分表,如时间参数为空,则将最后读数时间之前完成的月分表归并入主分表。此脚本只能在查询服务停机的时候执行。
输入参数:
tbl 表名
t 时间,此参数如不为空,则归并此时刻之前完成的分表,否则归并最后读数时间之前完成的分表
查询脚本query.splx
追加型以时间区间作为输入参数,查询出与时间区间有交集的分表构成复组表对象返回;更新型不需要时间参数,直接返回所有分表构成的复组表对象。
如果需要热数据,用上一次的读数截止时间和输入参数end或now()(end为null),作为输入参数调用热数据脚本,将分表和热数据组成复组表返回。如果不需要热数据,直接返回分表组成的复组表。
输入参数:
tbl 表名
start 起始时间,为空表示end之前的所有分表
end 结束时间,为空表示start之后的所有分表
返回值:
分表和热数据(如果需要)组成的复组表。
存储结构
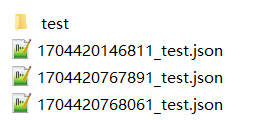
*_test.json:配置文件,用"修改时间的long值_表名.json"作为文件名
test: 存储组表的路径,在配置文件里配置
test目录下的组表文件示例如下:
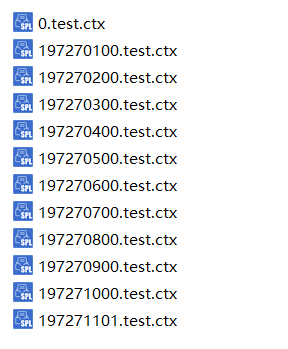
分表号用当前分表所属时间区间的起始时间计算。
计算规则:天/月层/单组表的分表号格式为yyyyMMdd,对于月层/单组表,dd的取值为最后一次归并的日子;小时和分钟层的分表号为dddddHHmm,其中dddddd为当前日期和1970-01-01之间间隔的天数,HH为小时分量+1,mm为分钟分量+1,小时层的mm为00。秒层的分表号为long(t)\1000。
全局变量
表名QConfig:查询脚本使用,用于存储配置信息
表名QLastReadTime:查询脚本使用,上次读的配置文件的时间,如有新的满足条件的配置文件则重读
表名Config:热模式启动脚本使用,用于存储配置信息
应用举例
冷模式追加型单组表
某商超的商品表,总数据量预计在千万量级,可以单个分表存储。每天新增数据量在几十万量级,无修改删除。每日23时到次日2时期间执行数据维护。
配置文件名Commodity.json,内容如下:
[{ "Filename":"Commodity.ctx", "DataPath":"Commodity/", "DimKey":"CommodityID", "TimeField":"InputDate", "OtherFields":"Name,QuantityPerUnit,SupplierID,UnitPrice,UnitsInStock,UnitsOnOrder", "NewDataScript":"read1.splx", "HotDataScript":"read2.splx", "LastTime":"2023-01-01 00:00:00", "MultiZones":false, "Updateable":false, "BlockSize":1048576, "ChoasPeriod":null, "Zones":null }] |
新数据脚本示例1:read1.splx(从文件读,假设文件命名规则为 表名+日期.txt,当天截止时间之后的数据存入第二天的文件中,每日23时为当天的截止时间):
A |
|
1 |
=periods@o(start,end).(string(~,"yyyyMMdd")).to(2,) |
2 |
=(((config.DimKey.split@c()|if(config.Updateable,config.DeleteKey,null))&config.TimeField)&config.OtherFields.split@c()).concat@c() |
3 |
=A1.(file(tbl+~+".txt").cursor@t(A2).sortx(config.DimKey)).mergex(config.DimKey) |
4 |
return A3 |
A1 根据起止时间,算出需要读文件的日期,这里默认start所属日的数据文件上一次已经读过了
A2 根据规则拼出返回数据的字段名
A3 读取数据文件,按规则排序,如果多个文件,拼成单路游标返回
新数据脚本示例2:read1.splx(从数据库读):
A |
|
1 |
>config=json(file(tbl+".json").read()) |
2 |
=(((config.DimKey.split@c()|if(config.Updateable,config.DeleteKey,null))&config.TimeField)&config.OtherFields.split@c()).concat@c() |
3 |
=connect("mysql") |
4 |
=A3.query("select"+A2+"from"+tbl+"where"+config.TimeField+">=?"+if(end,"and"+config.TimeField+"<?","")+" order by "+config.DimKey,start${if(end,",end","")}) |
5 |
=A3.close() |
6 |
return A4 |
A1 读配置文件
A2 根据规则拼出返回数据的字段名
A4 根据表名、字段名、排序字段、时间过滤条件等,拼出SQL语句并执行查询,这里时间过滤条件采用左闭右开
热数据脚本:read2.splx
参考新数据脚本示例2。
第一次使用新表前先初始化:
A |
|
1 |
=call("init.splx","Commodity") |
每日23时执行一次写入操作,调度写入脚本如下:
A |
B |
|
1 |
=now() |
=23 |
2 |
=[year(A1),month(A1),day(A1),hour(A1)] |
|
3 |
>A2(4)=if(A2(4)>=B1,B1,B1-24) |
|
4 |
=datetime(A2(1),A2(2),A2(3),A2(4),0,0) |
|
5 |
=call("update.splx","Commodity",A4) |
|
A1-A4 把当前时刻按23点取整
查询脚本:
A |
|
1 |
=call("query.splx","Commodity",null,now()) |
因为是单组表,不需要根据时间过滤分表号,因此查询时不传入起始时间参数;由于本例需要返回热数据,所以传入结束时间参数,用于读取热数据。
冷模式更新型复组表
某商超的订单表,有增删改的需求,月数据量在一千万以内,需要用多个分表存储。每日23时至次日6时为封账时间,在此期间往分表追加一次新数据即可。查询时希望查询速度尽可能快,需要热数据和分表归并形成复组表一起返回。
配置文件名orders.json,内容如下:
[{ "Filename":"orders.ctx", "DataPath":"orders/", "DimKey":"userid,orderTime", "TimeField":"lastModifyTime", "OtherFields":"orderid,amount,paymentMode", "NewDataScript":"readOrders.splx", "HotDataScript":"readOrders.splx", "LastTime":null, "MultiZones":true, "WriteLayer":"d", "HighestLayer":"M", "Updateable":true, "DeleteKey":"Deleted", "BlockSize":{"d":1048576}, "Zones":null }] |
MultiZones配置为true,表示需要多个分表存储。
WriteLayer配置为d,表示每天写入一次
HighestLayer配置为M,表示分表按月划分区间
新数据脚本readOrders.splx:
A |
|
1 |
>config=json(file(tbl+".json").read()) |
2 |
=(((config.DimKey.split@c()|if(config.Updateable,config.DeleteKey,null))&config.TimeField)&config.OtherFields.split@c()).concat@c() |
3 |
=connect("mysql") |
4 |
=A3.query("select"+A2+"from"+tbl+"where"+config.TimeField+">=?"+if(end,"and"+config.TimeField+"<?","")+" order by "+config.DimKey,start${if(end,",end","")}) |
5 |
=A3.close() |
6 |
return A4 |
A1 读配置文件
A2 根据规则拼出返回数据的字段名
A4 根据表名、字段名、排序字段、时间过滤条件等,拼出sql语句并执行查询,这里时间过滤条件采用左闭右开
第一次使用新表前先初始化:
A |
|
1 |
=call("init.splx","orders") |
每日23时执行一次写入操作,调度写入脚本如下:
A |
B |
|
1 |
=now() |
=23 |
2 |
=[year(A1),month(A1),day(A1),hour(A1)] |
|
3 |
>A2(4)=if(A2(4)>=B1,B1,B1-24) |
|
4 |
=datetime(A2(1),A2(2),A2(3),A2(4),0,0) |
|
5 |
=call("update.splx","orders",A4) |
|
A1-A4 把当前时刻按23时取整
查询脚本:
A |
|
1 |
=call("query.splx","orders") |
更新型不需要过滤分表号,不传入结束时间参数则表示热数据读至now()。
调用手动归并脚本:
A |
|
1 |
=call("merge.splx","orders",now()) |
热模式追加型复组表
某电商平台,全天24小时服务,其订单表每天新增数据量一千万条左右,只有新增,无删改需求。查询时除了所有分表文件,还需要实时查询热数据,和分表归并形成复组表一起返回。
本例数据量大,每时每刻均可能产生新数据,查询大部分是按天或者按周,偶尔领导才有可能按月统计,做月间的对比。所以写入层配置为分钟,最高层配置为天。
配置文件名orders.json,内容如下:
| [{ "Filename":"orders.ctx", "DataPath":"orders/", "DimKey":"userid,orderDate", "TimeField":"orderDate", "OtherFields":"orderid,amount,paymentMode,address,mobile,deliveryTime,deliveryFee", "NewDataScript":"read1.splx", "HotDataScript":"read2.splx", "LastTime":"2024-01-01 00:00:00", "ChoasPeriod":5, "Updateable":false, "WriteLayer":"m", "HighestLayer":"d", "BlockSize":{"m":131072,"H":262144, "d":1048576}, "Zones":null, "DiscardZones":null }] |
调用start.splx,启动数据维护:
A |
|
1 |
=call("start.splx","orders") |
查询脚本:
A |
|
1 |
=call("query.splx","orders",datetime("2024-01-01 00:00:00"),,datetime("2024-01-07 00:00:00")) |
实现方案与代码解析
以下代码为单机模式下编写。
init.splx
新表初始化,或补写历史数据(新表或中断维护较长时间)。冷模式下需要主动发起调用;热模式下会由start.splx自动调用。
输入参数:
tbl 表名
返回值:
tbl的配置信息
A |
B |
C |
|
1 |
=directory("*_"+tbl+".json").sort(~:-1) |
||
2 |
>config=json(file(A1(1)).read()) |
||
3 |
if(!config.Zones) |
||
4 |
>config.Zones=create(s,m,H,d).insert(0,[],[],[],[]) |
||
5 |
if(config.ChoasPeriod) |
||
6 |
>config.DiscardZones=create(s,m,H,d).insert(0,[],[],[],[]) |
||
7 |
=file(A1(1)).write(json(config)) |
||
8 |
=file(config.DataPath/config.Filename:0) |
||
9 |
if(!A8.exists()) |
||
10 |
=config.DimKey.split@c() |
||
11 |
=B10.("#"+trim(~)).concat@c() |
||
12 |
if(!B10.pos(config.TimeField)) |
||
13 |
=(config.TimeField&config.OtherFields.split@c()).concat@c() |
||
14 |
else |
>C13=config.OtherFields |
|
15 |
=if(config.MultiZones,config.BlockSize.d,config.BlockSize) |
||
16 |
if(config.Updateable && config.DeleteKey) |
||
17 |
=A8.create@yd(${B11},${config.DeleteKey},${C13};;B15) |
||
18 |
else |
>C17=A8.create@y(${B11},${C13};;B15) |
|
19 |
=C17.close() |
||
20 |
=register("zoneT","zoneT.splx") |
||
21 |
=register("zoneZ","zoneZ.splx") |
||
22 |
=call("writeHistory.splx",tbl) |
||
23 |
return A22 |
||
A1 列出所有配置文件,逆序排序
A2 读第一个配置文件
A3 如果Zones为空(即新表第一次使用)
B4-B7 初始化Zones和DiscardZones,并存回配置文件
A8 0分表
A9-B19 如果0分表不存在,则创建0分表
A20-A21 注册集算器函数zoneT和zoneZ
A22 补写历史数据(新表初次使用时一次性读写历史数据,或中断维护较长时间,一次性补写中断期间的历史数据),并返回新的配置信息
A23 返回配置信息
zoneT.splx
把时间转换成对应层的分表号。
输入参数:
tm 时间
L 目标层,取值为s,m,H,d,分别表示秒、分钟、小时、日层
返回值:
tm对应L层的分表号
A |
B |
|
1 |
1970-01-01 |
|
2 |
if(L=="d") |
return year(tm)*10000+month(tm)*100+day(tm) |
3 |
else if(L=="H") |
return (tm-A1)*10000+(hour(tm)+1)*100 |
4 |
else if(L=="m") |
return (tm-A1)*10000+(hour(tm)+1)*100+minute(tm)+1 |
5 |
else |
return long(tm)\1000 |
A1 基准时间
A2-B2 日层返回格式为yyyyMMdd的分表号
A3-B3 小时层返回格式为dddddHH00的分表号,其中ddddd是tm和A1间隔的天数,HH为小时分量+1
A4-B4 分钟层返回格式为dddddHHmm的分表号,其中ddddd是tm和A1间隔的天数,HH为小时分量+1,mm为分钟分量+1
A5-B5 秒层返回long(时间)\1000
zoneZ.splx
把低层分表号转换为高层分表号。
输入参数:
z 低层分表号
L 目标层,取值为m,H,d,分别表示分钟、小时、日层
l 低层层次,取值为s,m,H,分别表示秒、分钟、小时
返回值:
z对应L层的分表号
A |
B |
C |
|
1 |
if(l=="s" || L=="m") |
||
2 |
=datetime(z*1000) |
||
3 |
=zoneT(B2,L) |
||
4 |
else |
if(L=="H") |
return (z\100)*100 |
5 |
else |
=z\10000 |
|
6 |
1970-01-01 |
||
7 |
=C6+C5 |
||
8 |
return year(C7)*10000+month(C7)*100+day(C7) |
||
A1-B3 如果低层是秒,先把秒层分表号换算成日期时间,然后再算出目标层的分表号
B4-C4 如果目标层是小时,则直接把末尾两位数变00
C5-C8 如果目标层是日,先根据基准日期算出实际的日期,然后返回yyyyMMdd格式的分表号
writeHistory.splx
补读昨天及以前的历史数据,此脚本被init.splx调用,服务器启动时执行一次,过程中不再执行
输入参数:
tbl 表名
A |
B |
C |
D |
E |
|
1 |
=directory("*_"+tbl+".json").sort(~:-1) |
||||
2 |
>config=json(file(A1(1)).read()) |
||||
3 |
=if(!config.LastTime || ifdate(config.LastTime),config.LastTime,datetime(config.LastTime)) |
||||
4 |
=if(config.ChoasPeriod,elapse@s(now(),-config.ChoasPeriod),now()) |
||||
5 |
=datetime(date(A4),time("00:00:00")) |
||||
6 |
if(config.MultiZones && !config.Updateable && A5>A3) |
||||
7 |
=config.Zones.H.new(~:zd,zoneZ(~,"d","H"):zu)| config.Zones.m.new(~:zd,zoneZ(~,"d","m"):zu)| config.Zones.s.new(~:zd,zoneZ(~,"d","s"):zu) |
||||
8 |
=B7.group(zu;~.(zd):zd) |
||||
9 |
= zoneT(A4,"d") |
||||
10 |
>B8=B8.select(zu<B9) |
||||
11 |
=config.HighestLayer=="M" |
||||
12 |
if(B11) |
>B8=B8.group(zu\100;~.m(-1).zu,~.(zd).conj():zd) |
|||
13 |
=config.Zones.d.m(-1) |
||||
14 |
for B8 |
=C13\100==B14.zu\100 |
|||
15 |
if(B11 && C14, C13,null) |
||||
16 |
=file(config.DataPath/config.Filename:C15|B14.zd) |
||||
17 |
>d=B14.zu%100,m=(B14.zu\100)%100,y=B14.zu\10000 |
||||
18 |
=if(B11,datetime(y,m+1,1,0,0,0),datetime(y,m,d+1,0,0,0)) |
||||
19 |
=min(A5,C18) |
||||
20 |
=call(config.NewDataScript,tbl,A3,C19) |
||||
21 |
=zoneT(elapse(C19,-1),"d") |
||||
22 |
=file(config.DataPath/config.Filename:C21) |
||||
23 |
=C16.reset@y${if(config.Updateable,"w","")}(C22:config.BlockSize.d;C20) |
||||
24 |
>config.Zones.H=config.Zones.H\B14.zd, config.Zones.m=config.Zones.m\B14.zd, config.Zones.s=config.Zones.s\B14.zd, config.Zones.d=(config.Zones.d\C15)|C21, A3=C19 |
||||
25 |
=(C15|B14.zd).(movefile@y(config.DataPath/~/"."/config.Filename)) |
||||
26 |
if(A5>A3) |
if(B11) |
=periods@m(A3,A5) |
||
27 |
=config.Zones.d.m(-1) |
||||
28 |
else |
>D26=periods(A3,A5) |
|||
29 |
for D26.to(2,) |
||||
30 |
=elapse(C29,-1) |
||||
31 |
=year(D30)*10000+month(D30)*100+day(D30) |
||||
32 |
=file(config.DataPath/config.Filename:D31) |
||||
33 |
=call(config.NewDataScript,tbl,A3,C29) |
||||
34 |
=if(B11 && D27\100==D31\100,D27,0) |
||||
35 |
=file(config.DataPath/config.Filename:D34) |
||||
36 |
=D35.reset@y${if(config.Updateable,"w","")}(D32:config.BlockSize.d;D33) |
||||
37 |
if(D34!=0) |
=movefile@y(config.DataPath/D34/"."/config.Filename) |
|||
38 |
>config.Zones.d=config.Zones.d\D34 |
||||
39 |
>A3=C29, config.Zones.d=config.Zones.d|D31 |
||||
40 |
>config.LastTime=A3 |
||||
41 |
else if(!config.MultiZones && A5>A3) |
||||
42 |
=elapse(A5,-1) |
||||
43 |
>newZone=year(B42)*10000+month(B42)*100+day(B42) |
||||
44 |
>oldZone=if(config.Zones.d.len()>0,config.Zones.d.m(-1),0) |
||||
45 |
=file(config.DataPath/config.Filename:oldZone) |
||||
46 |
=file(config.DataPath/config.Filename:newZone) |
||||
47 |
=call(config.NewDataScript,tbl,A3,A5) |
||||
48 |
=B45.reset@y${if(config.Updateable,"w","")}(B46:config.BlockSize;B47) |
||||
49 |
if(oldZone!=0) |
=movefile@y(config.DataPath/oldZone/"."/config.Filename) |
|||
50 |
>config.Zones.d=[newZone] |
||||
51 |
>config.LastTime=A5 |
||||
52 |
else if(config.Updateable) |
||||
53 |
=0 | config.Zones.d | config.Zones.H | config.Zones.m| config.Zones.s |
||||
54 |
=file(config.DataPath/config.Filename:B53) |
||||
55 |
=file(config.DataPath/config.Filename:1) |
||||
56 |
=call(config.NewDataScript,tbl,A3,A5) |
||||
57 |
=B54.reset@y${if(config.Updateable,"w","")}(B55:config.BlockSize.d;B56) |
||||
58 |
=movefile@y(config.DataPath/1/"."/config.Filename,0/"."/config.Filename) |
||||
59 |
=(config.Zones.d | config.Zones.H | config.Zones.m| config.Zones.s).(movefile@y(config.DataPath/~/"."/config.Filename)) |
||||
60 |
>config.Zones.d=[],config.Zones.H=[],config.Zones.m=[],config.Zones.s=[] |
||||
61 |
>config.LastTime=A5 |
||||
62 |
=file(long(now())/"_"/tbl/".json").write(json(config)) |
||||
63 |
return config |
||||
A1-A2 读配置文件
A3 上次读数时间
A4 混乱期时刻
A5 用混乱期时刻算出此次读数截止时间
A6 如果是追加型复组表,则按最高层分表的时间区间,挨个读数
先处理已有低层分表的时间区间
B7 读取小时层、分钟层和秒层的分表,并算出其对应的日层分表号
B8 将B7按其对应的日层分表号分组
B9 用混乱期时刻算出其对应的日层分表号
B10 选出昨天及之前的分表
B11 最高层是否为月
B12 如果最高层是月
C12 将B8重新按月分组,保留每个月的最大分表号
C13 读出现有最高层分表号中的最后一个分表号
B14 按B8循环
C14 判断当前的新分表号和C13是否同一个月
C15 如果最高层是月且满足C14,则将C13也用于归并
C16 用低层分表和C15产生复组表
C17-C18 用当前组对应的最高层分表号,算出其对应的时间区间的结束值
C19 取A5和C18的较小值,作为此次读数的截止时间
C20 读取新数据
C21 用C19算出新分表号
C22 产生新分表
C23 将新数据和低层分表一起归并后写入新分表
C24 将归并过的分表号从配置信息中删除,新分表号添加到配置信息,更新A3为新的读数截止时间
C25 将归并过的分表从硬盘删除
B26 如果还有未读的历史数据,则接着处理无低层分表存在的时间区间
C26-D28 如果最高层是月,则算出A3到A5之间每月的结束时刻,否则算出每日的结束时刻
C29 从D26的第二个成员开始循环(第一个成员为起始时间)
D30-D36 按最高层分表的时间区间,逐个读数写入分表
D37-E38 如果有被归并的月分表,则将其删除,同时从分表号列表中删除
D39 更新A3为新的读数截止时间,将新产生的分表号添加到分表号列表
B40 更新配置信息中的上次读数时间
A41 如果是单组表
B42-B48 读取新数据,将新数据和原分表归并后,写入新分表
B49 删除原分表
B50 将新分表号存入配置信息
B51 更新配置信息中的上次读数时间
A52 如果是更新型
B53-B57 读取新数据,将新数据和所有低层分表归并后,写入1分表
B58 将1分表改名为0分表并覆盖之
B59 删除所有归并过的低层分表
B60 将所有归并过的低层分表号从配置信息中删除
B61 更新配置信息中的上次读数时间
A62 将配置信息写入新的配置文件
A63 返回配置信息
start.splx
热模式启动脚本,先调用初始化脚本,如新表初次使用或者中断维护时间过长,会自动补写数据;然后分别启动两个线程:写入和归并,根据配置信息,周期循环执行写入和归并。本脚本和pwrite.splx、pmerge.splx必须运行在一个进程中,共享全局变量。
输入参数:
tbl 表名
A |
|
1 |
=call("init.splx",tbl) |
2 |
=env(${tbl}Config,A1) |
3 |
=call@r("pwrite.splx",tbl) |
4 |
=call@r("pmerge.splx",tbl) |
A1 调用初始化脚本
A2 声明全局变量${tbl}Config,并将配置信息赋值给它
A3 启动写入线程
A4 启动归并线程
pwrite.splx
根据配置信息中定义的写入周期,循环调用写入脚本,执行新数据的写入操作。此脚本被热模式启动脚本start.splx调用。
输入参数:
tbl 表名
A |
B |
C |
|
1 |
=elapse@s(now(),-${tbl}Config.ChoasPeriod) |
||
2 |
=if(ifdate(${tbl}Config.LastTime),${tbl}Config.LastTime,datetime(${tbl}Config.LastTime)) |
||
3 |
>e=A1 |
||
4 |
>i=1 |
||
5 |
if(${tbl}Config.WriteLayer=="s") |
||
6 |
=datetime(year(A1),month(A1),day(A1),hour(A1),minute(A1),second(A1)) |
||
7 |
=datetime(year(A2),month(A2),day(A2),hour(A2),minute(A2)+1,0) |
||
8 |
>e=min(B6,B7) |
||
9 |
>i=1 |
||
10 |
else if(${tbl}Config.WriteLayer=="m") |
||
11 |
=datetime(year(A1),month(A1),day(A1),hour(A1),minute(A1),0) |
||
12 |
=datetime(year(A2),month(A2),day(A2),hour(A2)+1,0,0) |
||
13 |
>e=min(B11,B12) |
||
14 |
>i=60 |
||
15 |
else if(${tbl}Config.WriteLayer=="H") |
||
16 |
=datetime(year(A1),month(A1),day(A1),hour(A1),0,0) |
||
17 |
=datetime(year(A2),month(A2),day(A2)+1,0,0,0) |
||
18 |
>e=min(B16,B17) |
||
19 |
>i=3600 |
||
20 |
else if(${tbl}Config.WriteLayer=="d") |
||
21 |
>e=datetime(year(A1),month(A1),day(A1),0),0,0) |
||
22 |
if(${tbl}Config.HighestLayer=="M") |
||
23 |
=datetime(year(A2),month(A2)+1,0,0,0,0) |
||
24 |
>e=min(e,C23) |
||
25 |
>i=24*3600 |
||
26 |
else |
return |
end tbl+"写入层定义错误" |
27 |
if(e>A2) |
||
28 |
=call("writeHot.splx",tbl,e,${tbl}Config) |
||
29 |
=lock(tbl+"Config") |
||
30 |
=call@r("modConfig.splx",tbl,e, B28) |
||
31 |
=env(${tbl}Config,B30) |
||
32 |
=lock@u(tbl+"Config") |
||
33 |
goto A1 |
||
34 |
else |
=elapse@s(A2,${tbl}Config.WritePeriod*i+${tbl}Config.ChoasPeriod) |
|
35 |
=sleep(max(interval@ms(now(),B34),0)) |
||
36 |
goto A1 |
||
A1 混乱期时刻
A2 上次读数的截止时间
A5-A26 根据不同写入层的时间单位,对A1取整,并利用A2算出其对应的上层分表时间区间的结束值,两者取较小值,作为此次的读数截止时间,赋值给变量e
A27 如果e大于A2
B28 调用写入脚本,执行写入操作
B29-B32 加锁,将B28返回的配置信息修改内容更新至配置文件,返回新的配置信息,并更新全局变量
B33 回到A1,进行下一轮的写入操作
A34 否则:
B34-B36 算出到下一轮可写入时刻需要等待的时长,休眠,然后回到A1,进行下一轮的写入操作
pmerge.splx
根据配置信息中定义的层信息,循环调用归并脚本,执行归并操作。此脚本被热模式启动脚本start.splx调用。
输入参数:
tbl 表名
A |
B |
|
1 |
>tm=max(elapse@s(now(),-${tbl}Config.ChoasPeriod-3600), if(ifdate(${tbl}Config.LastTime),${tbl}Config.LastTime,datetime(${tbl}Config.LastTime))) |
|
2 |
=${tbl}Config.WriteLayer |
|
3 |
if A2=="s" |
=datetime(year(tm),month(tm),day(tm),hour(tm),minute(tm)+1, ${tbl}Config.WritePeriod) |
4 |
else if A2=="m" |
>B3=datetime(year(tm),month(tm),day(tm),hour(tm)+1, ${tbl}Config.WritePeriod,0) |
5 |
else if A2=="H" |
>B3=datetime(year(tm),month(tm),day(tm)+1, ${tbl}Config.WritePeriod,0,0) |
6 |
else |
return |
7 |
=call("mergeHot.splx",tbl,${tbl}Config) |
|
8 |
=lock(tbl+"Config") |
|
9 |
=call("modConfig.splx",tbl,null, A7) |
|
10 |
=env(${tbl}Config,A9) |
|
11 |
=lock@u(tbl+"Config") |
|
12 |
=sleep(max(0,long(B3)-long(now())) |
|
13 |
goto A1 |
|
A1 用max(now-混乱期-一小时, 上次读数时间)算出此轮归并的基准时间
A3-B6 根据写入层的时间单位,算出下轮归并的时刻
A7 调用归并脚本,执行归并操作
A8-A11 加锁,将A7返回的配置信息修改内容更新至配置文件,返回新的配置信息,并更新全局变量
A12 根据前面算出的下轮归并时刻,休眠
A13 回到A1,执行下一轮归并操作
writeHot.splx
用上一次的读数截止时间和这一次新传入的读数截止时间作为时间区间,去调用新数据脚本,获得新数据。用起始时间算出分表号,将新数据直接写入新分表。
输入参数:
tbl 表名
end 读数截止时间
config 配置文件信息
返回值:
由字段new, discard组成的序表,两个字段分别表示:新产生的分表号、被归并完成待删除的分表号
A |
B |
C |
|
1 |
=if(ifdate(config.LastTime),config.LastTime,datetime(config.LastTime)) |
||
2 |
if(end>elapse@s(now(),-config.ChoasPeriod)|| end<=A1) |
||
3 |
return |
end |
|
4 |
=call(config.NewDataScript,tbl,A1,end) |
||
5 |
=config.DimKey.split@c() |
||
6 |
=A5.("#"+trim(~)).concat@c() |
||
7 |
if(!A5.pos(config.TimeField)) |
||
8 |
=(config.TimeField&config.OtherFields.split@c()).concat@c() |
||
9 |
else |
>B8=config.OtherFields |
|
10 |
>newZone=zoneT(A1,config.WriteLayer) |
||
11 |
=file(config.DataPath/config.Filename:newZone) |
||
12 |
=(config.WriteLayer=="d" && config.HighestLayer=="M") |
||
13 |
if(A12) |
=config.Zones.${config.WriteLayer}.m(-1) |
|
14 |
= B13 && B13\100==newZone\100 |
||
15 |
=create(new,discard).insert(0,create(${config.WriteLayer}).insert(0,[]),create(${config.WriteLayer}).insert(0,[])) |
||
16 |
if(A12 && B14) |
||
17 |
=file(config.DataPath/config.Filename:B13) |
||
18 |
=B17.reset@y${if(config.Updateable,"w","")}(A11:config.BlockSize.WriteLayer;A4) |
||
19 |
>A15.discard.${config.WriteLayer}.insert(0,B13) |
||
20 |
else |
if(config.Updateable && config.DeleteKey) |
|
21 |
=A11.create@yd(${A6},${config.DeleteKey},${B8};;config.BlockSize.${config.WriteLayer}) |
||
22 |
else |
>C21=A11.create@y(${A6},${B8};;config.BlockSize.${config.WriteLayer}) |
|
23 |
=C21.append@i(A4) |
||
24 |
=C21.close() |
||
25 |
>A15.new.${config.WriteLayer}.insert(0,newZone) |
||
26 |
return A15 |
||
A1 上次读数时间
A2-C3 如果传入的读数截止时间不合理,直接返回
A4 用上次读数时间和这次新传入的读数截止时间作为参数,调用新数据脚本
A5-B9 拼出维字段和其它字段备用
A10 用上次读数时间算出新分表号
A11 新分表文件
A12-B14 如果写入层是日,最高层是月,则从分表号列表中读取最后一个分表号,看看和当前的新分表号是否同一个月的
A15 产生由new、discard字段组成的序表,用于存储新产生的分表号和归并完待删除的分表号
A16 如果写入层是日,最高层是月,且当前存在同月的分表号:
B17-B19 则将原月分表与新数据一起归并写入新的月分表,原月分表放入待删除列表
A20 否则:
B20-B24 创建新的分表,将新数据写入新分表
A25 新分表号添加到A15中
A26 返回A15
mergeHot.splx
用max(now-混乱期-1小时,上次读数时间)作为判断依据,将此时刻之前准备好的低层分表归并后写入其对应的高层分表,只有当高层分表对应的低层分表全部准备好后,才执行此操作。
输入参数:
tbl 表名
config 配置信息
返回值:
由字段new, discard组成的序表,两个字段分别表示:新产生的分表号、被归并完成待删除的分表号
A |
B |
C |
D |
|
1 |
if(config.WriteLayer=="d") |
|||
2 |
return |
end |
||
3 |
else if(config.WriteLayer=="s") |
|||
4 |
>L=["m","H","d"] |
|||
5 |
else if(config.WriteLayer=="m") |
|||
6 |
>L=["H","d"] |
|||
7 |
else |
>L=["d"] |
||
8 |
>tm=max(elapse@s(now(),-config.ChoasPeriod-3600), if(ifdate(config.LastTime),config.LastTime,datetime(config.LastTime))) |
|||
9 |
=create(new,discard).insert(0,create(s,m,H,d).insert(0,[],[],[],[]),create(s,m,H,d).insert(0,[],[],[],[])) |
|||
10 |
for L |
= zoneT(tm,A10) |
||
11 |
=if(A10=="d":"H",A10=="H":"m";"s") |
|||
12 |
>zz = config.Zones.${B11}|A9.new.${B11} |
|||
13 |
if zz.len()>0 |
|||
14 |
=zz.group(zoneZ( ~, A10,B11):zu;~:zd) |
|||
15 |
=C14.select(zu<B10) |
|||
16 |
if(C15.len()==0) |
|||
17 |
next A10 |
|||
18 |
=(A10=="d" && config.HighestLayer=="M") |
|||
19 |
if(C18) |
=config.Zones.${A10}.m(-1) |
||
20 |
>C15=C15.group(zu\100;~.m(-1).zu,~.(zd).conj():zd) |
|||
21 |
for C15 |
=(D19\100==C21.zu\100) |
||
22 |
=if(C18 && D21,D19,null) |
|||
23 |
=file(config.DataPath/config.Filename:D22|C21.zd) |
|||
24 |
=file(config.DataPath/config.Filename:C21.zu) |
|||
25 |
=D23.reset@y${if(config.Updateable,"w","")}(D24:config.BlockSize.${A10}) |
|||
26 |
=A9.new.${B11}^C21.zd |
|||
27 |
=C21.zd\D26 |
|||
28 |
>A9.new.${B11}=A9.new.${B11}\D26 |
|||
29 |
=D26.(movefile@y(config.DataPath/~/"."/config.Filename)) |
|||
30 |
>A9.discard.${B11}=A9.discard.${B11}|D27, A9.new.${A10}=A9.new.${A10}|C21.zu, A9.discard.${A10}=A9.discard.${A10}|D22 |
|||
31 |
return A9 |
|||
A1-B7 算出需要循环的层
A8 用max(now-混乱期-一小时, 上次读数时间)作为归并的基准时间
A9 产生由new、discard字段组成的序表,用于存储新产生的分表号和归并完待删除的分表号
A10 按L循环
B10 用基准时间算出对应目标层的分表号
B11-B12 读出低层的分表号列表
B13 如果低层分表号不为空
C14 将低层分表号按其对应的高层分表号分组
C15 选出高层分表号小于B10的组(这样的组对应的低层分表全部准备完毕)
C16-D17 如果C15为空,则继续往上层循环
C18-D20 如果目标层是日,最高层是月,则取出目标层最后一个分表号备用,同时把C15重新按月分组
C21 按C15循环
D21-D25 如果目标层是日、最高层是月,且当前月分表号存在,则将当且月分表与低层分表一起归并写入新的月分表,否则只归并低层分表
D26 归并完的分表号和新产生分表号的交集
D27 将D26从归并完的分表号列表里删除
D28 将D26从新产生的分表号列表里删除
D29 将D26对应的文件从硬盘删除
D30 将新产生的分表号和归并完的分表号添加到A9
A31 返回A9
modConfig.splx
每一次调用写入脚本或者归并脚本后,接收到返回值,将返回值传给修改配置脚本,执行配置文件的修改。此脚本执行时必须加锁,保证串行执行。
输入参数:
tbl 表名
LastTime 上次读数截止时间
Zones 待修改的分表号列表,直接使用写入脚本或归并脚本的返回值
返回值:
新的tbl配置信息
A |
B |
C |
|
1 |
=directory("*_"+tbl+".json").sort(~:-1) |
||
2 |
>config=json(file(A1(1)).read()) |
||
3 |
if(LastTime) |
||
4 |
>config.LastTime=LastTime |
||
5 |
if(!LastTime || Zones.discard.#1.len()>0) |
||
6 |
=config.DiscardZones.fname() |
||
7 |
for B6 |
||
8 |
=config.DiscardZones.${B7}.(movefile(config.DataPath/~/"."/config.Filename)) |
||
9 |
=C8.pselect@a(~==false) |
||
10 |
>config.DiscardZones.${B7}=config.DiscardZones.${B7}(C9) |
||
11 |
=Zones.discard.fname() |
||
12 |
for A11 |
||
13 |
>config.DiscardZones.${A12}=config.DiscardZones.${A12}|Zones.discard.${A12} |
||
14 |
>config.Zones.${A12}=config.Zones.${A12}\Zones.discard.${A12} |
||
15 |
=Zones.new.fname() |
||
16 |
for A15 |
||
17 |
>config.Zones.${A16}=config.Zones.${A16}|Zones.new.${A16} |
||
18 |
=file(long(now())/"_"/tbl/".json").write(json(config)) |
||
19 |
=long(elapse@s(now(),-120)) |
||
20 |
=A1.select(#>2 && long(left(~,13))<A19) |
||
21 |
=A20.(movefile@y(~)) |
||
22 |
return config |
||
A1 列出配置文件,逆序排序
A2 读第一个配置文件
A3-B4 如果传入的新的读数时间不为空,则更新至config
A5-C10 如果传入的新的读数时间为空,或者待删除分表号不为空(说明是归并),则先删除原弃用分表号
A11-B14 将新的弃用分表号从列表中删除,且从硬盘删除
A15-B17 将新分表号添加到列表
A18-A21 将配置文件按时间排序,将序号大于2且时间早于2分钟之前的配置文件删除
A22 返回新的配置信息
update.splx
以上一次的读数截止时间和这次新传入的读数截止时间作为输入参数去调用新数据脚本,获得新数据。用新的读数截止时间算出新的分表号,将原分表和新数据归并后写入新分表,然后删除原分表。如果是月初且需要多个分表存储,则直接启用新分表。此脚本只能在查询服务停机的时候执行。
输入参数:
tbl 表名
end 读数截止时间
A |
B |
C |
|
1 |
=directory("*_"+tbl+".json").sort(~:-1) |
||
2 |
>config=json(file(A1(1)).read()) |
||
3 |
=if(config.LastTime,datetime(config.LastTime),null) |
||
4 |
if((A3 && end<elapse(A3,1)) || end>now()) |
||
5 |
return |
end "读数截止时间不合理" |
|
6 |
=call(config.NewDataScript,tbl,A3,end) |
||
7 |
=elapse(end,-1) |
||
8 |
>newZone=year(A7)*10000+month(A7)*100+day(A7) |
||
9 |
>oldZone=if(config.Zones.d.len()>0,config.Zones.d.m(-1),0) |
||
10 |
=config.BlockSize |
||
11 |
if(config.MultiZones && config.HighestLayer=="M") |
||
12 |
if(oldZone!=0 && oldZone\100!=newZone\100) |
||
13 |
>oldZone=0 |
||
14 |
>A10=config.BlockSize.d |
||
15 |
=file(config.DataPath/config.Filename:newZone) |
||
16 |
=file(config.DataPath/config.Filename:oldZone) |
||
17 |
=A16.reset@y${if(config.Updateable,"w","")}(A15:A10;A6) |
||
18 |
if(oldZone!=0) |
=movefile@y(config.DataPath/oldZone/"."/config.Filename) |
|
19 |
>config.Zones.d=(config.Zones.d\oldZone)|newZone |
||
20 |
>config.LastTime=end |
||
21 |
=file(long(now())/"_"/tbl/".json").write(json(config)) |
||
A1-A2 读配置文件
A3 上一次读数时间
A4-C5 如果传入的截止时间参数和上一次读数时间相差不到一天,或者晚于当前时间,则中止并提示截止时间不合理
A6 调用新数据脚本,用上一次读数时间和这次的截止时间作为时间区间参数,读取新数据
A7-A8 用这次的读数截止时间计算新分表号
A9-C13 如果是复组表且最高层为月,现有的最后一个分表号和当前新分表号不同月,则启用新分表,原分表号置为0
A15 新分表文件
A16 原分表文件
A17 将原分表和新数据归并后写入新分表
A18-B18 删除原分表
A19 更新分表号列表
A20 更新上次读数时间
A21 将配置信息写入文件
merge.splx
更新型时,将传入时间之前完成的日/月分表归并入主分表,如时间参数为空,则将最后读数时间之前完成的日/月分表归并入主分表。此脚本只能在查询服务停机的时候执行。
输入参数:
tbl 表名
t 时间,此参数如不为空,则归并此时刻之前完成的分表,否则归并最后读数时间之前完成的分表
说明:
此脚本于冷模式下执行,被归并完的分表将直接被删除。
A |
|
1 |
=directory("*_"+tbl+".json").sort(~:-1) |
2 |
>config=json(file(A1(1)).read()) |
3 |
=config.Zones.d |
4 |
=if(t,t,datetime(config.LastTime)) |
5 |
=year(A4)*10000+month(A4)*100+day(A4) |
6 |
=A3.select(~<A5) |
7 |
=file(config.DataPath/config.Filename:(0|A6)) |
8 |
=file(config.DataPath/config.Filename:1) |
9 |
=A7.reset@w(A8:config.BlockSize.d) |
10 |
=movefile@y(config.DataPath/1/"."/config.Filename,0/"."/config.Filename) |
11 |
=A6.(movefile@y(config.DataPath/~/"."/config.Filename)) |
12 |
>config.Zones.d=config.Zones.d\A6 |
13 |
=file(A1(1)).write(json(config)) |
A1 列出所有配置文件,逆序排序
A2 读第一个配置文件
A3 最高层的分表号
A4 如果传入时间参数为空,则使用上次读书截止时间
A5 用A4算出其对应最高层的分表号
A6 选出小于A5的最高层分表号
A7-A9 将0分表和A6分表一起归并入临时分表1
A10 将1分表改名为0分表并覆盖之
A11 删除归并完的分表
A12 将归并完的分表号从列表中删除
A13 将配置信息写回文件
query.splx
追加型以时间区间作为输入参数,查询出与时间区间有交集的分表构成复组表对象;更新型不需要时间参数,直接用所有分表构成复组表对象。
如果需要热数据,用上一次的读数截止时间和输入参数end,作为输入参数去调用热数据脚本,将分表和热数据组成复组表返回。如果不需要热数据,直接返回分表组成的复组表。
输入参数:
tbl 表名
start 起始时间
end 结束时间
返回值:
分表和热数据(如果需要)组成的复组表。
A |
B |
C |
D |
|
1 |
=now() |
|||
2 |
=directory("*_"+tbl+".json").sort(~:-1) |
|||
3 |
=long(elapse@s(A1,-60)) |
|||
4 |
=A2.select@1(#>1 || long(left(~,13))<A3) |
|||
5 |
=long(left(A4,13)) |
|||
6 |
=lock(tbl+"Config") |
|||
7 |
if(!ifv(${tbl}QLastReadTime)|| A5>${tbl}QLastReadTime) |
|||
8 |
=env(${tbl}QConfig, json(file(A4).read())) |
|||
9 |
=env(${tbl}QLastReadTime,A5) |
|||
10 |
=lock@u(tbl+"Config") |
|||
11 |
=if(ifdate(${tbl}QConfig.LastTime),${tbl}QConfig.LastTime,datetime(${tbl}QConfig.LastTime)) |
|||
12 |
if(${tbl}QConfig.Updateable || !${tbl}QConfig.MultiZones) |
|||
13 |
>result=0|${tbl}QConfig.Zones.d| ${tbl}QConfig.Zones.H| ${tbl}QConfig.Zones.m |
|||
14 |
else |
=zoneT(datetime(${tbl}QConfig.LastTime),"s") |
||
15 |
>z=${tbl}QConfig.Zones.s|B14 |
|||
16 |
>sz=zoneT(start,"s") |
|||
17 |
>ez=zoneT(end,"s") |
|||
18 |
>sp = z.pselect@z(~<=sz) |
|||
19 |
>ep = ifn(z.pselect( ~>ez), z.len())-1 |
|||
20 |
=ifn(sp,1) |
|||
21 |
=if (sp >= z.len() || B20>ep,0,z.to(B20, ep)) |
|||
22 |
if(sp) |
>result=B21 |
||
23 |
else |
=zoneZ(z(1),"m","s") |
||
24 |
>z=${tbl}QConfig.Zones.H| ${tbl}QConfig.Zones.m|C23 |
|||
25 |
>sz=zoneT(start,"m") |
|||
26 |
>ez=zoneT(end,"m") |
|||
27 |
>sp = z.pselect@z(~<=sz) |
|||
28 |
>ep = ifn(z.pselect( ~>ez), z.len())-1 |
|||
29 |
=ifn(sp,1) |
|||
30 |
=if (sp >= z.len() || C29>ep,0,z.to(C29, ep)) |
|||
31 |
if(sp) |
>result=C30&B21 |
||
32 |
else |
=zoneZ(z(1),"d") |
||
33 |
>z=${tbl}QConfig.Zones.d|D32 |
|||
34 |
>sz=zoneT(start,"d") |
|||
35 |
>ez=zoneT(end,"d") |
|||
36 |
>sp = z.pselect@z(~<=sz) |
|||
37 |
>ep = ifn(z.pselect( ~>ez), z.len())-1 |
|||
38 |
=ifn(sp,1) |
|||
39 |
=if (sp >= z.len() || D38>ep,0,z.to(D38, ep)) |
|||
40 |
>result=D39&C30&B21 |
|||
41 |
=file(${tbl}QConfig.DataPath/${tbl}QConfig.Filename:result).open() |
|||
42 |
if(${tbl}QConfig.HotDataScript && end>A11) |
|||
43 |
=call(${tbl}QConfig.HotDataScript,tbl,A11,end) |
|||
44 |
=A41.append@y(B43) |
|||
45 |
return B44 |
|||
46 |
else |
return A41 |
||
A2 列出所有配置文件按产生时间逆序
A3 算出1分钟之前时刻的long值
A4 选出文件序号大于1或者产生时间在A3之前的第一个文件
A5 文件A4的产生时间
A6 读配置文件锁
A7 如果上次读取时间为空,或者有新的满足读取条件的配置文件产生:
B8 读出配置文件,赋值给全局变量${tbl}QConfig
B9 将读取时间赋值给全局变量${tbl}QLastReadTime
A10 解锁
A11 上次读数截止时间
A12-B13 如果是更新型或者单组表:将所有分表号按时间顺序拼成序列赋值给result
A14 如果是复组表追加型:
B14 上次读数截止时间对应的秒层分表号
B15 先将秒层的分表号末尾拼上B14
B16-B17 算出查询起止时间对应的秒层分表号
B18 从后往前找到第一个小于等于查询起始时间的分表号位置
B19 从前往后找到第一个大于查询结束时间的分表号位置减1
B20 如果查询起始时间早于第一个分表号,则起始位置赋值1
B21 选出和查询时间区间有交集的分表号列表,没有则用0
B22-C22 如果查询起始时间晚于第一个分表号,则直接将B21赋值给result
B23 否则:
C23 用秒层第一个分表号算出对应的分钟层分表号
C24 先将小时、分钟层的分表号按时间顺序拼成序列,末尾拼上C23
C25-C26 算出查询起止时间对应的分钟层分表号
C27 从后往前找到第一个小于等于查询起始时间的分表号位置
C28 从前往后找到第一个大于查询结束时间的分表号位置减1
C29 如果查询起始时间早于第一个分表号,则起始位置赋值1
C30 选出和查询时间区间有交集的分表号列表,没有则用0
C31-D31 如果查询起始时间晚于第一个分表号,则直接将C30&B21赋值给result
C32 否则:
D32 用小时分钟层的第一个分表号算出对应的日分表号
D33 读出日分表号,末尾拼上D32
D34-D35 算出查询起止时间对应的日层分表号
D36 从后往前找到第一个小于等于查询起始时间的分表号位置
D37 从前往后找到第一个大于查询结束时间的分表号位置减1
D38 如果查询起始时间早于第一个分表号,则起始位置赋值1
D39 选出和查询时间区间有交集的分表号列表,没有则用0
D40 将D39&C30&B21赋值给result
A41 用result产生复组表并打开
A42 如果需要热数据且end大于上次读数截止时间:
B43 用上次读数截止时间和end作为输入参数,调用热数据脚本,获得热数据
B44 将热数据和A41归并产生复组表


英文版