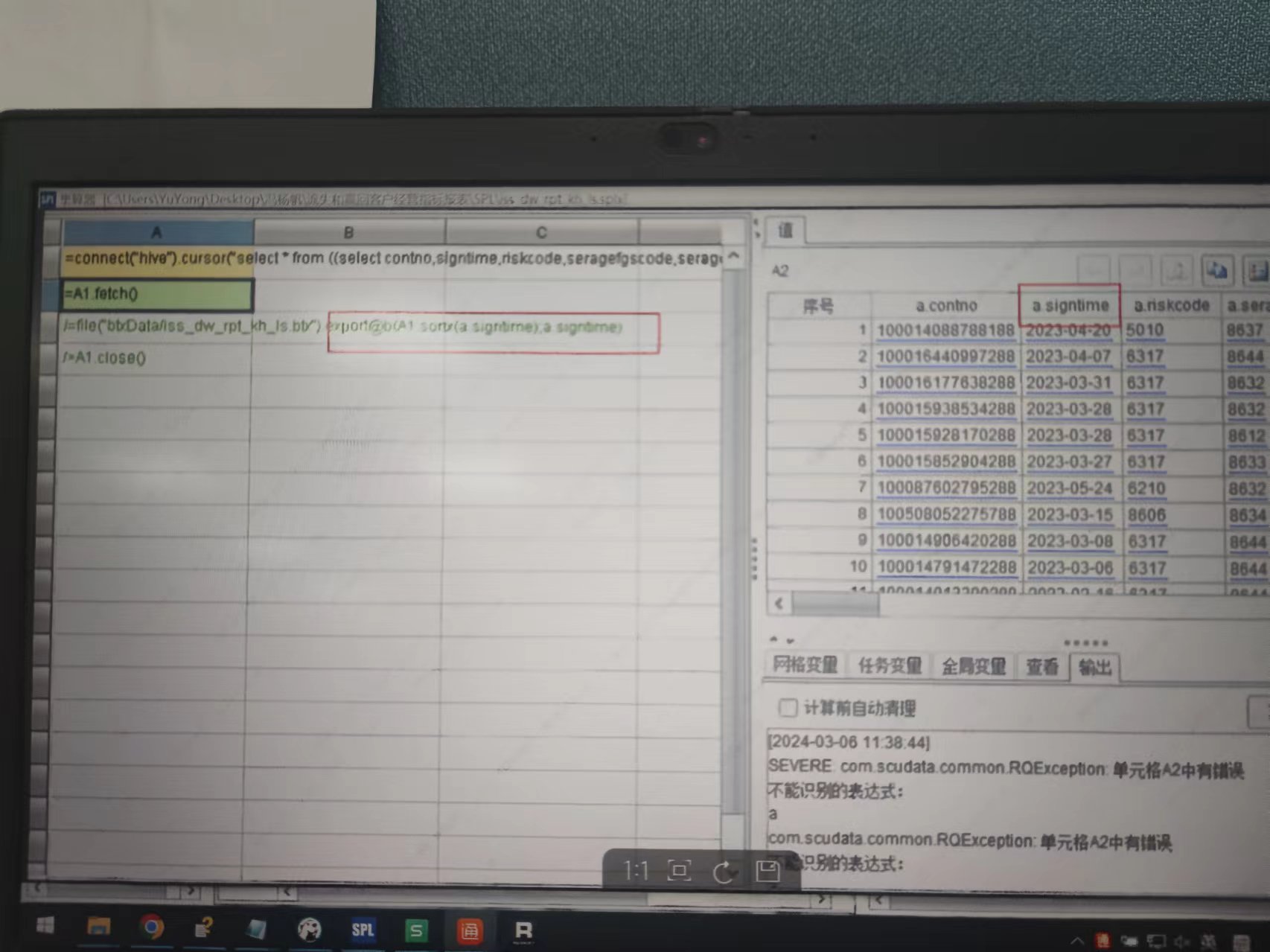
"[图片] 存入的数据为 a,b 两张表关联(a,b 两张表都存在 signtime 这个字段,已将 b 表的 signtime 别名改为 signtime_b) 目前 A3 报错,要么不识别 .."
存入的数据为 a,b 两张表关联(a,b 两张表都存在 signtime 这个字段,已将 b 表的 signtime 别名改为 signtime_b)目前 A3 报错,要么不识别 signtime(export@b(A1.sortx(signtime);signtime)),要么不识别 a(export@b(A1.sortx(a.signtime);a.signtime))该如何处理
是不是字段里有特殊符号😄 a.signtime 两边加上单引号试试,‘a.signtime’ ‘signtime.a’
fetch 结果的字段名怎么带“a.”?点是集算器的运算符,字段名中如果有点则引用的时候需要用单引号括起来。
嗯,’a.signtime’可以,感谢
因为存入的数据是两张表关联的,a,b 是别名,不过在数据库工具中查询都没有这个 a.,集算器中却有,加了 '' 确实解决了
有没有办法把 a.,b. 给去掉呢?SQL 是这样的select * from ((select * from xxx where xx=xx)aleft join (select * from xxx) bon a.xx=b.xx)b 表和 a 表同名的字段都给起了其他别名
SQL 结果集肯定会有前缀来区分,但通常会用 a_xxx, b_xxx 这种别名,不会用点。检查一下数据库驱动是不是有什么可以配置的地方。SPL 就是取 JDBC 结果集中的列名。
仅供参考,两种方法,把点. 改成下划线 _:1、select 语句中一个一个写别名不要用 *,select a.signtime as a_signtime,….. 显然这个不怎么科学,字段多就很麻烦;2、集算器里改,A1是数据库游标db.cursor(),不是db.cursor@x (),接下来:A2 代码格:=A1.fetch(1).fname().(~/“:”/replace(~,“.”,“_”)).concat@c()A3 代码格:=A1.reset().rename(${A2})这里 A1.reset() 游标回转应该是可以的,都是猜的😄
好的
我试了下,在最外边那个查询那儿,把 * 改成了全部的字段名称就可以了,就是比较麻烦,一大段字段
实在人👍 实实在在敲代码😂
老贼,下午好😄 简单 sql 中 join 之后字段名也是用点隔开的,请看以下截图:
似乎没有人关注过 join 之后字段名用点隔开的问题,周围问了一圈都不知道如何在源头设置。😂
在最新版的集算器中,db.query 和 db.cursor 都添加了 @c 选项用于清理字段名。这个选项的作用是清理字段名中包含的表名,但是如果去除表名后出现了重名,则会在前面附加表名以做区分;同时,使用这个选项后,还会把字段名中的特殊字符如小数点、加减乘除等符号都置换为下划线。也就是说,现在可以用 =connect(“hive”).cursor@c(…) 去获得规范化字段名后的结果了。另外,用 spl 执行多表连接时,和使用数据库 jdbc 是有区别的,因为并不能返回标准的 ResultSet,也就无法存储同时包含表名和字段名的列信息,所以只能用 Table.Field 作为连接后的字段名结果。如果想将字段名中的小数点换为下划线,可以使用 rename 函数,如 >tab.rename(${tab.fname().(~ +“:”+replace( ~ ,“.”,“_”)).concat@c()})
事事有回应,件件有着落…SPL 666👍 👍 👍
c 选项起作用了。但可能也分数据库,我连了一个非主流数据库 DuckDB,join 的时候字段不会出现表别名😄
这种表别名的获取,只能从 JDBC 中取得,出现这样的结果,说明这个数据库做的 JDBC 并不够完整,返回的 ColInfo 里面没有 TableName 信息,所以会出现这种情况。这就没什么办法了,在执行连接后没有办法区分结果数据集的字段是来源于哪个表的,只能考虑在 sql 中定义别名了,或者在连接前保证没有重名字段。
谢谢大佬回复🙏这个数据库本身的问题就不管他了。😄感谢!





是不是字段里有特殊符号😄 a.signtime 两边加上单引号试试,‘a.signtime’ ‘signtime.a’
fetch 结果的字段名怎么带“a.”?
点是集算器的运算符,字段名中如果有点则引用的时候需要用单引号括起来。
嗯,’a.signtime’可以,感谢
因为存入的数据是两张表关联的,a,b 是别名,不过在数据库工具中查询都没有这个 a.,集算器中却有,加了 '' 确实解决了
有没有办法把 a.,b. 给去掉呢?
SQL 是这样的
select * from (
(select * from xxx where xx=xx)a
left join (select * from xxx) b
on a.xx=b.xx
)
b 表和 a 表同名的字段都给起了其他别名
SQL 结果集肯定会有前缀来区分,但通常会用 a_xxx, b_xxx 这种别名,不会用点。检查一下数据库驱动是不是有什么可以配置的地方。SPL 就是取 JDBC 结果集中的列名。
仅供参考,两种方法,把点. 改成下划线 _:
1、select 语句中一个一个写别名不要用 *,select a.signtime as a_signtime,….. 显然这个不怎么科学,字段多就很麻烦;
2、集算器里改,A1是数据库游标db.cursor(),不是db.cursor@x (),接下来:
A2 代码格:=A1.fetch(1).fname().(~/“:”/replace(~,“.”,“_”)).concat@c()
A3 代码格:=A1.reset().rename(${A2})
这里 A1.reset() 游标回转应该是可以的,都是猜的😄
好的
我试了下,在最外边那个查询那儿,把 * 改成了全部的字段名称就可以了,就是比较麻烦,一大段字段
实在人👍 实实在在敲代码😂
老贼,下午好😄 简单 sql 中 join 之后字段名也是用点隔开的,请看以下截图:
似乎没有人关注过 join 之后字段名用点隔开的问题,周围问了一圈都不知道如何在源头设置。😂
在最新版的集算器中,db.query 和 db.cursor 都添加了 @c 选项用于清理字段名。这个选项的作用是清理字段名中包含的表名,但是如果去除表名后出现了重名,则会在前面附加表名以做区分;同时,使用这个选项后,还会把字段名中的特殊字符如小数点、加减乘除等符号都置换为下划线。也就是说,现在可以用 =connect(“hive”).cursor@c(…) 去获得规范化字段名后的结果了。
另外,用 spl 执行多表连接时,和使用数据库 jdbc 是有区别的,因为并不能返回标准的 ResultSet,也就无法存储同时包含表名和字段名的列信息,所以只能用 Table.Field 作为连接后的字段名结果。如果想将字段名中的小数点换为下划线,可以使用 rename 函数,如 >tab.rename(${tab.fname().(~ +“:”+replace( ~ ,“.”,“_”)).concat@c()})
事事有回应,件件有着落…SPL 666👍 👍 👍
c 选项起作用了。但可能也分数据库,我连了一个非主流数据库 DuckDB,join 的时候字段不会出现表别名😄
这种表别名的获取,只能从 JDBC 中取得,出现这样的结果,说明这个数据库做的 JDBC 并不够完整,返回的 ColInfo 里面没有 TableName 信息,所以会出现这种情况。这就没什么办法了,在执行连接后没有办法区分结果数据集的字段是来源于哪个表的,只能考虑在 sql 中定义别名了,或者在连接前保证没有重名字段。
谢谢大佬回复🙏
这个数据库本身的问题就不管他了。😄
感谢!