


pivot@s 聚合时第 3 参数的用法
开门见山,关于 pivot@s 聚合时第 3 参数的用法,我有 3 个问题恳请大佬们给予指导。如下:
1、3 参聚合时可否引用 2 参中的变量名;
2、3 参聚合值可否进一步运算,支持复杂聚合表达式;
3、3 参聚合时不能引用 #n 来表示字段,只能用字段名。
实战场景如下所示,需要把左边的表格变成右上角的表格,行转列再聚合汇总。类似场景的聚合还是很多的,涉及到分类聚合的都可以用 pivot 实现 reshape and aggregate。

为方便测试,以下数据可以复制使用:
月份 水果(价格) 数量
一月 山楂(5) 10
一月 山楂(5.5) 8
一月 西瓜(5.5) 20
一月 梨(5) 10
一月 梨(6) 6
一月 苹果(5) 10
一月 苹果(4.51) 20
二月 西瓜(5) 30
二月 山楂(5) 10
二月 西瓜(6) 10
二月 菠萝(5) 10
二月 苹果(6) 8
二月 苹果(8) 20
这样的 reshape & aggregate 需求,似乎没有比 spl 的 pivot@s 更方便快捷的方法了,VBA 字典套字典,需要一定的基础和想象力,Power Query 虽然可以在 UI 界面点击,小白可以不写代码完成操作,无奈步骤太多,pandas 的 dataframe 结构对我而言有点不友好,在 pivot_table 之前需要对源数据重构(以下写法来自某学习群的一位 Python 佬):
df.iloc[:,[0,2]].join(df[[*df][1]].str.extract('(?P<水果>\D+)((?P<b>[\d.]+)').astype({'b':float})).eval('c=数量*b').pivot_table('c','月份','水果',sum).fillna(0)
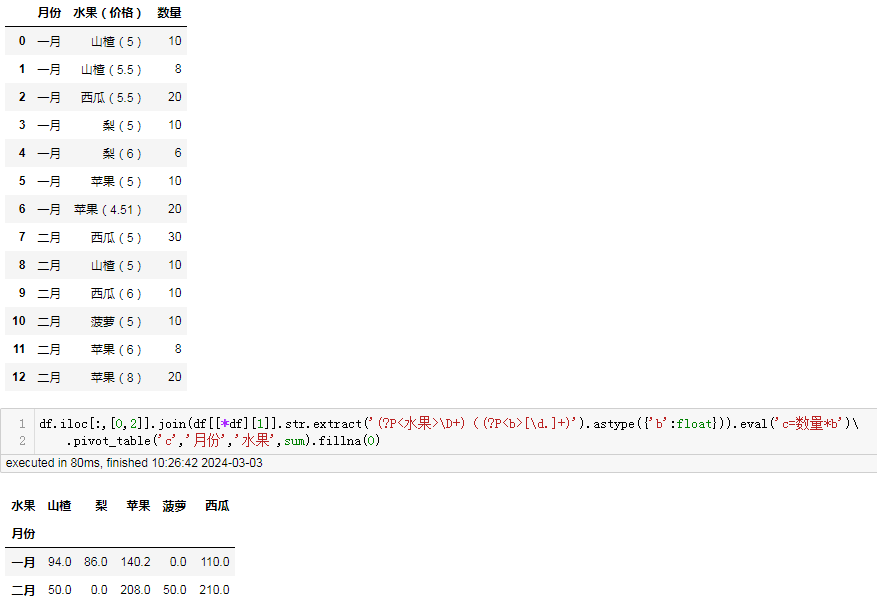
目前来看,spl 中的 pivot@s 是最简洁的,可以用以下语句实现 (此帖用 EXCEL 插件,IDE 一样的效果):
=spl("=E(?).pivot@s(月份;#2.split@rp(""(|)"")(1),(~.(#2.split@rp(""(|)"")(2))**~.(#3)).sum())",B2:D15)

此时,pivot@s()的第 3 参数用 ~.fx() 这种写法,其中的波浪线 ~ 表示引用当前组,可以看到语句简洁,"一行流" 风格 (Python 佬常说的一行代码解决问题,说着玩😄)。
当然,我求助绝不是为了吹牛好玩,我想的是上述语句能不能更简洁。请注意观察上图语句中标有颜色的部分,#2.split@rp(““(|)””),2 参 3 参都涉及到了这部分,且重复写了。所以,我就琢磨,能不能在 2 参的位置引入变量名,令 x=#2.split@rp(““(|)””),供 3 参调用。再一个,pivot@s 的第 3 参数不仅支持 ~.fx() 还支持聚合函数,于是就有了以下写法:
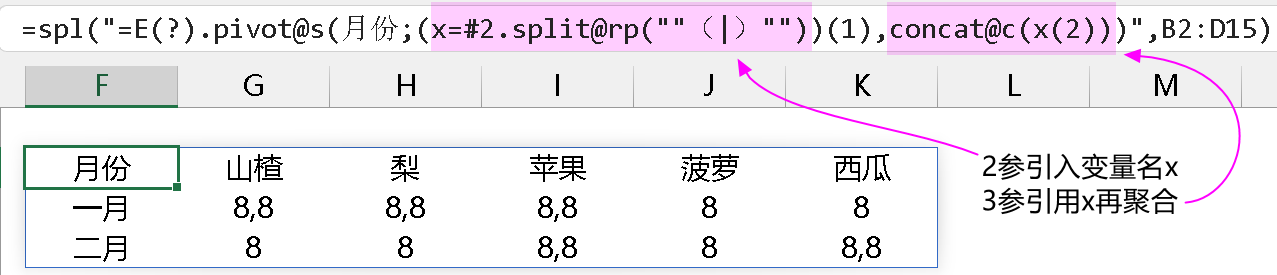
可以看到,3 参虽然能引用 2 参中的变量名,但结果跟预期的不一样,3 参聚合时显示的都是源数据最后一行的价格,但 3 参能聚合原本存在的列,比如聚合第 3 列的数量,结果是符合预期的:

那 pivot@s 中的 3 参是不是只支持简单聚合,还能否对聚合值进行进一步计算呢,尝试了一下,结果不符合预期,如下所示:

所以,初步得出 pivot@s 中的 3 参只支持简单聚合,引用变量时结果会不符合预期。无意中还发现一个问题,3 参聚合时不能用 #n 表示某列,会抛出索引越界的错误,只能用字段名表示,如下截图:

spl 中,涉及到聚合的除了 pivot@s 之外,还有 groups,group@s,这两个函数在聚合时,可以引用变量名且支持复杂聚合表达式,结果都是符合预期的。为了简单起见,还是拿本帖数据源中一月份的数据用 groups 和 group@s 举例如下:

group@s 时也是一样的操作,结果符合预期:
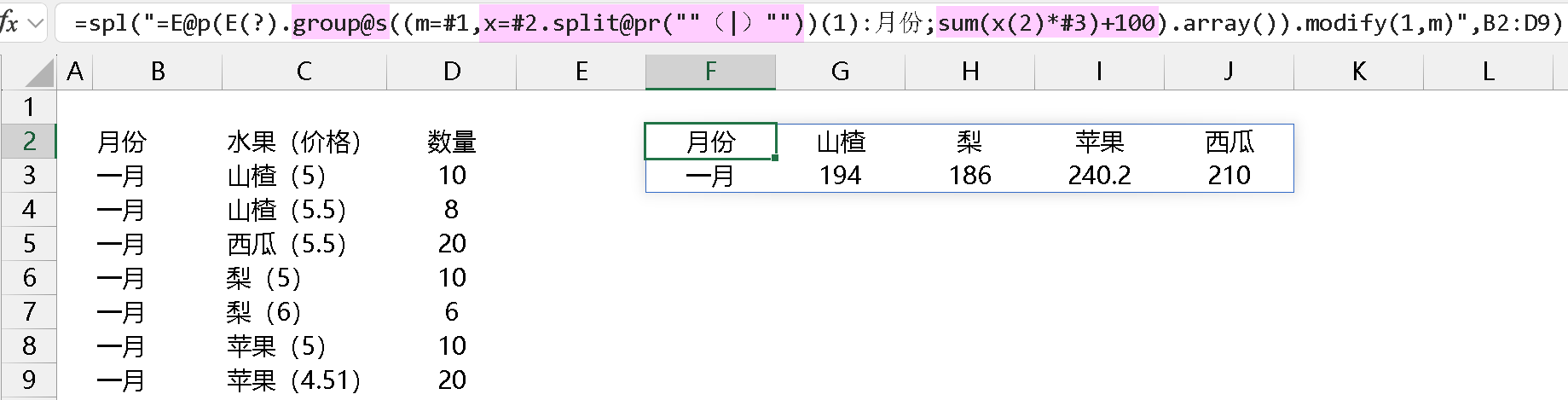
我的想法是这样的,在 spl 中分组聚合函数就这几个 groups,group@s,pivot@s,常用且实用。就拿 pivot 这个函数来说,以我目前所了解到的能用 pivot 的编程语言,没有比 spl 的 pivot 更简洁好用的了,所以,恳请大佬们考虑一下帖子开头的 3 个小问题,看看能否把 pivot@s 的 3 参优化一下,跟 groups 和 group@s 函数保持语法统一?我想要的写法是这样的 (目前结果不符合预期):
=spl("=E(?).pivot@s(月份;(x=#2.split@rp(""(|)""))(1),sum(x(2)*数量))",B2:D15)
或者
=spl("=E(?).pivot@s(月份;(x=#2.split@rp(""(|)""))(1),sum(x(2)*#3))",B2:D15)
关于 pivot@s 目前想到的就这些,具体还得恳请大佬们得闲时出手指点为盼。
期待好消息……🙏 🙏


pivot@s 第三个聚合表达式参数可以用两种方式:
1 f(…) 这里的 f 只能是聚合函数 sum、count、max 等,这种方式当有的组的数据为空时会抛异常(比如二月梨没有数据),这个 bug 已经修改,代码上传到 github 上了。
2 ~.f(…) 这里的 ~ 表示当前组的记录构成的序列。文中提到的临时变量无法支持,因为第二个参数和第三个参数不在一个计算步骤完成计算的。pivot 的计算过程是先按前两个参数对数据分组,再循环分组计算汇总表达式,所以当第二个参数使用临时变量时最终 x 算出来的值是针对最后一条记录的,第三个参数引用的 x 总是针对最后一条记录算出来的那个值。
这个运算可以先 derive 一下再算 pivot:A.derive((x=#2.split@rp(“(|)”))(1): 水果,x(2): 价格 ).pivot@s( 月份; 水果,sum( 数量 * 价格))
谢谢大佬😄 🙏
等了一天,等了这么个消息😄 😄 😄 …
这下吹出去的牛牵不回来了,我台词都准备好了 "全网最简洁,没有之一"😄 😄 😄
其实写成这样也可以,就是多写一遍,看着变扭。
你说的方法先 derive 需要的列,再 pivot,这个比较正规,我想的那种比较偏门,可读性也不高。
这两种写法效率上应该不会有太大的差别吧?
哈哈,不纠结了,等更新完后,我再试试。
还是 A.derive().pivot 这种写法可读性高,几万几十万级别的数据量根本看不出性能区别
谢谢大佬🙏 …最终还是回归朴素写法。
以下写法均可,但你说的 derive().pivot@s() 更具可读性。
recap:
1、pivot@s()里三参支持聚合函数, 比如 sum( 字段) 和 ~.fx() 这两种写法;
2、3 参写成聚合函数形式时不支持聚合值的进一步计算,~.fx() 这种形式可以进一步计算;
3、pivot@s() 里三参支持 #n 表示某个字段;
3、三参不支持调用临时变量。