老贼在性能优化多路游标中提到过这么一句话,摘录如下: “对于 CPU 强和硬盘弱的场景,我们还可以单路游标转换成多路游标,也就是游标取数时使用单路,避免硬盘的并行,但计算时再使用多路,利用多 CPU 来提高性能,适合于文本文件这类需要较多 CPU 来解析的情况” 举的例子就是用 mcursor。我就迷惑了: 1、mcursor 是不是有特定的使用场景?我用下来整体的感觉是,mcursor 的提速似乎没有我想象中的那样直观; 2、CPU 强是啥样的强,硬盘弱是什么样的弱,有没有一个直观的参数?从没有去关注过硬件的配置,因为不懂,买电脑时也常常被卖电脑的忽悠😄






一:内存溢出问题,要看下 jvm 设置的多大,如果设计器下内存溢出,安装目录的 report\bin 这个下边 config.txt,startupreport.bat,startdemo.bat,还有个 config 下的 config.ini 这几个文件里都有个 xmx 参数,这个数值要调大些。
二:看下 A2select 里加了 m,做了并行,那要看报表里并行数量设置的多少,设计器下 工具 选项 集算器选项
如果应用部署,那么 raqsoftConfig.xml 中有个设置 ,在 esproc 节点下有个
这个并行数检查下设置的多少
好的,感谢,我去试试
两百万行要 4 秒,是不是慢了😄
A2 的 select 条件是不是也可以合并到第一步中的 iselect 里去?
select@m 应该搞不过 iselect(主观臆测)
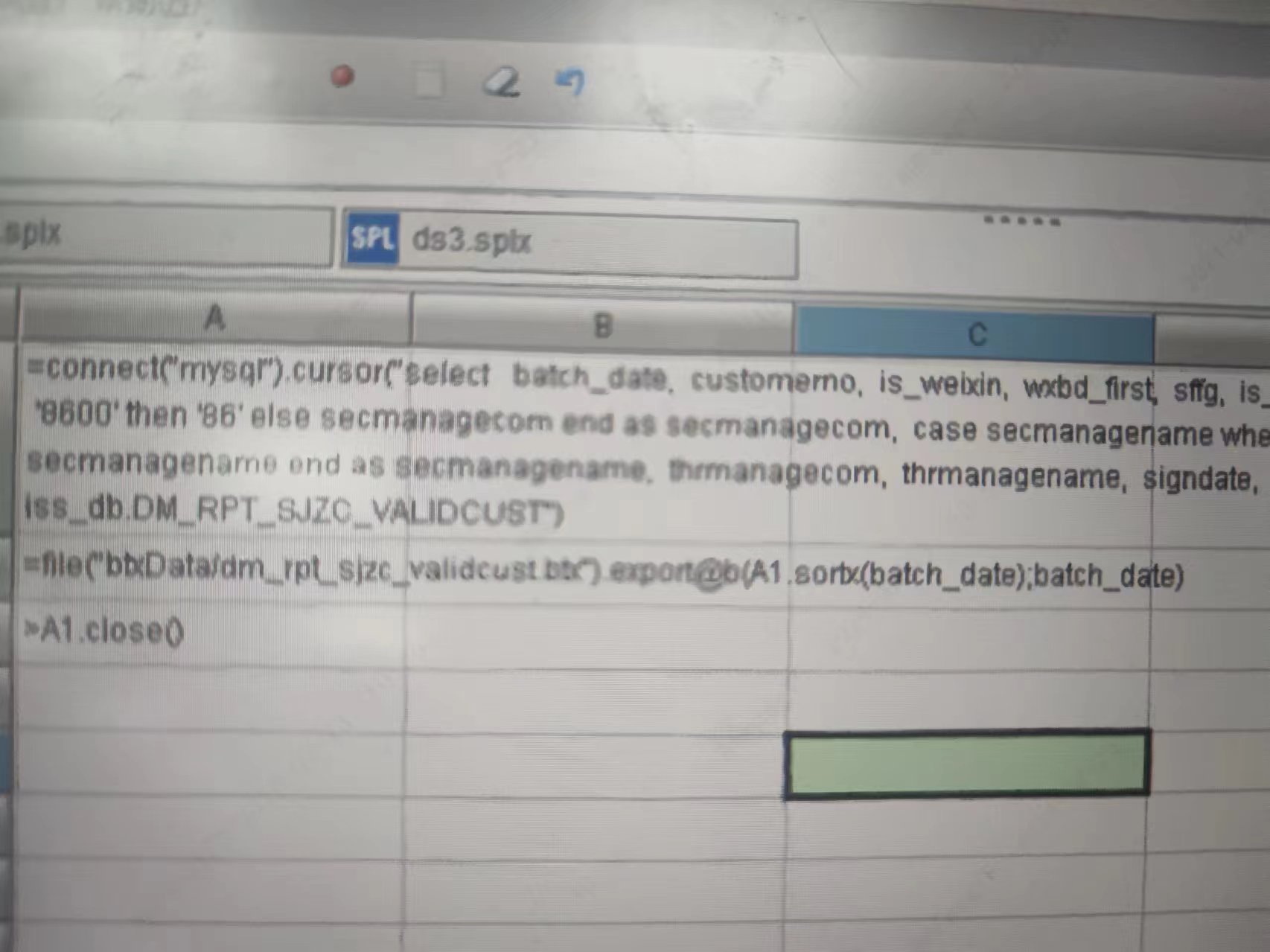
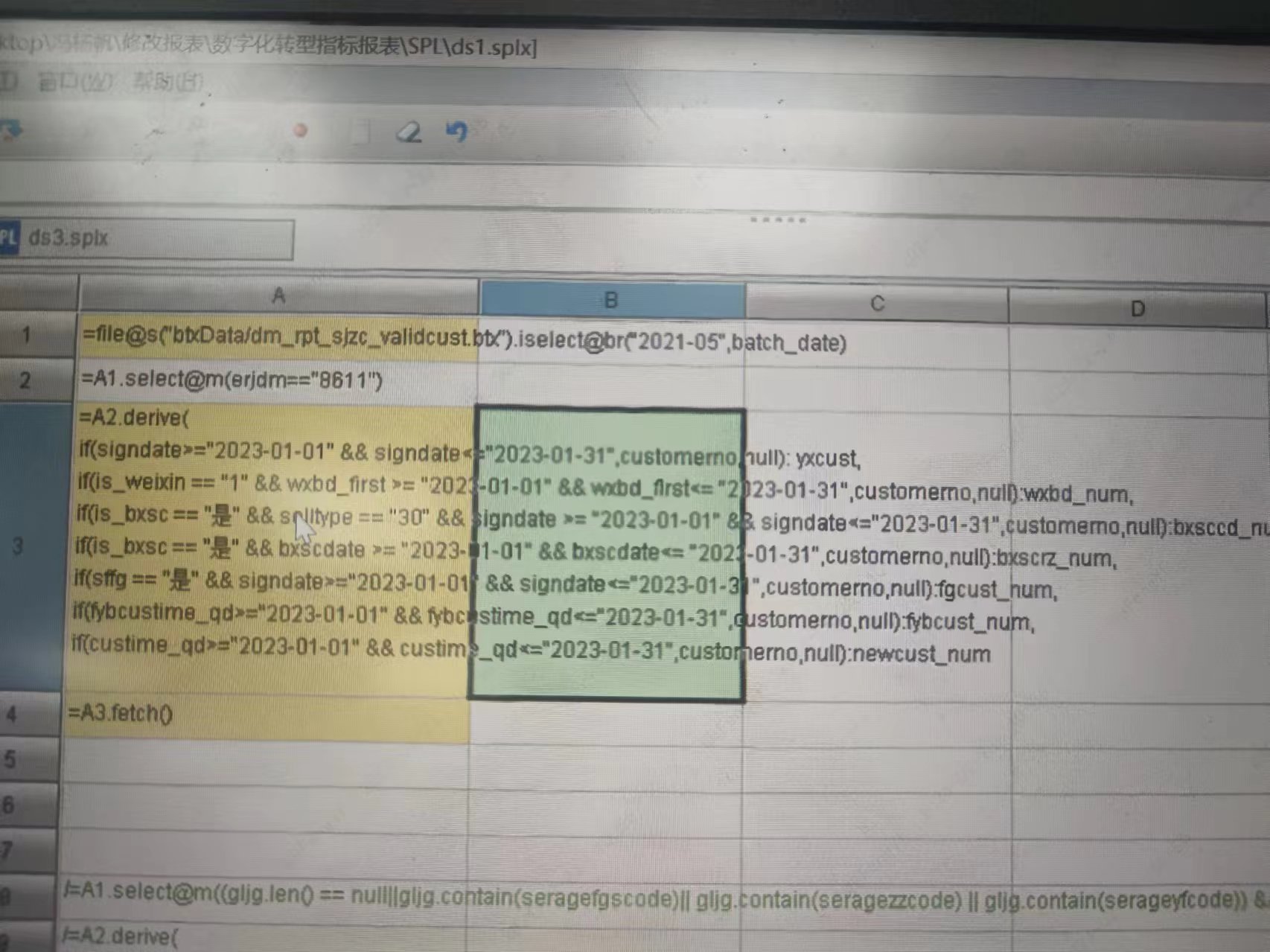
第一步取数转存 btx 的时候已经 sortx 了,能不能先 sortx(fld1,fld2,fld3…)?
先把 A2 fetch 出来统记一下 A1、A2 所花的时间,如果这个时间比较少则可以给 derive 加上 @m 选项。iselect 返回的是单路游标,后续要进行并行计算也可以调用 cs.mcursor(n) 函数把单路游标转成多路游标,n 是并行数,如果省略则会使用缺陷值。
如果大部分时间耗费在 iselect 和取数上则算法上没有太大优化余地,需要对源数据进行优化。看代码日期用的是字符串类型,这个效率比较低
A1.select@m(gljg.len()==null || gljg.contain(erjgdm)) 这儿的参数是字符串组,而且可传可不传,可以并入 iselect 中吗?
sortx(fld1,fld2,fld3…) 这个是什么意思?不太懂!
大佬,我总觉得 mcursor() 多路的时候不是很匀称,比如一个 24120 行的 txt:
file(txt).cursor@tm(4) 会分成比较均匀的 4 路,每一路 6000 行左右(6048,6028,6008,6036)
file(txt).cursor@t ().mcursor(4)分的就不怎么均匀,两路是9999行,一路是4122行,剩下一路是null
这样的 4 路 mcursor 耗时跟不用 mcursor 时耗时相差无几。
不知道是不是用法欠妥?
老贼在性能优化多路游标中提到过这么一句话,摘录如下:
“对于 CPU 强和硬盘弱的场景,我们还可以单路游标转换成多路游标,也就是游标取数时使用单路,避免硬盘的并行,但计算时再使用多路,利用多 CPU 来提高性能,适合于文本文件这类需要较多 CPU 来解析的情况”
举的例子就是用 mcursor。我就迷惑了:
1、mcursor 是不是有特定的使用场景?我用下来整体的感觉是,mcursor 的提速似乎没有我想象中的那样直观;
2、CPU 强是啥样的强,硬盘弱是什么样的弱,有没有一个直观的参数?从没有去关注过硬件的配置,因为不懂,买电脑时也常常被卖电脑的忽悠😄
你还是参考 leavedy 大佬的优化方法吧😄
我想着从数据库取数后,反正要对某些字段排序,干脆在数据准备阶段把你后续需要用到的字段一起排序得了,所以会有 sortx(字段 1, 字段 2…)
转存为 btx 后是一个对某些用得到的字段有序的文件,这样的话 btx.iselect@br(多字段条件) 可以用外存 2 分法查找,是这个意思。
当然数据源的数据类型也很关键,在转存为集文件之前可以处理一下的,这个 leavedy 大佬已经说了,你按他的方法来。
(1) file(txt).cursor@tm(4)
(2) file(txt).cursor@t ().mcursor(4)
这两种写法是有本质区别的,第一种是会产生 4 个读数游标,每个游标对应 1/4 的数据,并行读数计算。
第二种只产生一个读数游标,然后在这个读数游标基础上生成 4 个计算线程,这 4 个线程都是跟同一个读数游标要数据(读数动作会做同步),每次要的数据量是 9999,所以数据量少的时候最后的线程要到的数据量会相对小一些。不过这种情况基本不会发生,因为这种规模的数据没必要用多线程,大数据量的时候还是分配比较均匀的。
好的,谢谢您
这个 9999 跟工具 - 选项 - 环境设置里的 "每次从游标取的记录数" 是不是有关系?
我这种外行的想法是,既然向同一个游标强制指定 4 路 mcursor(4),那均匀是不是最理想的状态?
以下供参考,大佬有空有心情的时候可以测试一下,有几路会突然变大:
506 万 5200 行 txt.cursor().mcursor(4) 时行数是这样的 [849916,849915,1689831,1685538]
1013 万 0400 行 txt.cursor().mcursor(4) 时行数是这样的 [1689831,1689821,3371076,3379662]
比如,做以下计数统计,本机 4C16G:
1、不多路不并行 1013万0400行txt.cursor@t ().total(count(1)) 本机耗时8.4秒
2、mcursor 1013万0400行txt.cursor@t ().mcursor().total(count(1)) 本机耗时7.0秒
3、cursor@m 1013万0400行txt.cursor@tm().total(count(1)) 本机耗时1.9秒
从此例来看,cursor@m 的耗时差不多是不用多路时的 4 分之 1,这个很正常,也很容易接受;
但 mcursor 耗时 7 秒跟 8.4 秒没多少优势,有时甚至比不用时还要慢,这个就很困惑了。
外行人的预期是 mcursor4 个线程计算,即使达不到理想的 4 分之一,也不至于优势那么小。
是用的配置里设置的数量。
这样测试是不准确的,算 total(count(1)) 根本不花时间,瓶颈都在读取数据上,所以并行计算没有效果。
😂 mcursor 不会玩了。
一直对 mcursor 有困惑,心里没谱也不好意思问。我再看看文章,琢磨操练一下。
谢谢大佬🙏
@1f2y3f 兄弟,不好意思哈,把你楼整歪了,见谅🙏 😄