


集算器执行 GC 造成系统假死
tomcat 内存占用不高,tomcat 分了 8 个 G 内存,系统中有缓存对象,缓存对象大概占用 2 个 G。
集算器这个脚本总的处理数据源是 800 条。
当执行集算器脚本的时候,发现系统的 CPU 不是很高,内存也没有太大的突变。
通过 skywalking 发现 OLD Gc 次数执行了 8 次。根据这个异常指标怀疑系统有显示调用 gc 动作,tomcat 增加上 gc 打印日志,集算器 dfx 增加各种打印信息,发现 groupx 执行语句的时候会打印 full gc 信息,明显有显示调用 gc 语法。
集算器 dfx 文件如下:
reportdb2keys2v3levelzip
tomcat 执行此 dfx 文件,控制台打印的信息如下:
A00
Afor
Aends
Atodays
Astarts
AACC00
AACC
手工执行垃圾回收,执行 4 次。
2024-02-20T18:18:46.970+0800: [Full GC (System.gc())2024-02-20T18:18:46.970+0800: [CMS: 2114340K->2231301K(3590980K), 2.2208823 secs] 2469949K->2231301K(4204420K), [Metaspace: 98222K->98222K(1140736K)], 2.2219221 secs] [Times: user=2.17 sys=0.05, real=2.22 secs]
2024-02-20T18:18:49.193+0800: [Full GC (System.gc())2024-02-20T18:18:49.193+0800: [CMS: 2231301K->2155273K(3718840K), 2.1092369 secs] 2234145K->2155273K(4332280K), [Metaspace: 98222K->98222K(1140736K)], 2.1094791 secs] [Times: user=2.11 sys=0.00, real=2.11 secs]
2024-02-20T18:18:51.304+0800: [Full GC (System.gc())2024-02-20T18:18:51.304+0800: [CMS: 2155273K->2155274K(3718840K), 1.5618582 secs] 2159149K->2155274K(4332280K), [Metaspace: 98222K->98222K(1140736K)], 1.5620906 secs] [Times: user=1.56 sys=0.00, real=1.56 secs]
2024-02-20T18:18:52.867+0800: [Full GC (System.gc())2024-02-20T18:18:52.867+0800: [CMS: 2155274K->2155288K(3718840K), 1.7847399 secs] 2167302K->2155288K(4332280K), [Metaspace: 98224K->98224K(1140736K)], 1.7851512 secs] [Times: user=1.80 sys=0.00, real=1.78 secs]
ABB
AA
AA
BB
DD001
手工执行垃圾回收,执行 4 次。
2024-02-20T18:18:55.380+0800: [Full GC (System.gc())2024-02-20T18:18:55.380+0800: [CMS: 2155288K->2115297K(3718840K), 1.6344587 secs] 2449289K->2115297K(4332280K), [Metaspace: 98246K->98246K(1140736K)], 1.6347846 secs] [Times: user=1.69 sys=0.01, real=1.63 secs]
2024-02-20T18:18:57.016+0800: [Full GC (System.gc())2024-02-20T18:18:57.016+0800: [CMS: 2115297K->2115105K(3718840K), 1.5423653 secs] 2120481K->2115105K(4332280K), [Metaspace: 98246K->98246K(1140736K)], 1.5427078 secs] [Times: user=1.55 sys=0.00, real=1.54 secs]
2024-02-20T18:18:58.559+0800: [Full GC (System.gc())2024-02-20T18:18:58.559+0800: [CMS: 2115105K->2115107K(3718840K), 1.5868425 secs] 2119642K->2115107K(4332280K), [Metaspace: 98247K->98247K(1140736K)], 1.5870634 secs] [Times: user=1.58 sys=0.00, real=1.59 secs]
2024-02-20T18:19:00.147+0800: [Full GC (System.gc())2024-02-20T18:19:00.147+0800: [CMS: 2115107K->2115115K(3718840K), 1.1949620 secs] 2119783K->2115115K(4332280K), [Metaspace: 98248K->98248K(1140736K)], 1.1951571 secs] [Times: user=1.22 sys=0.00, real=1.20 secs]
DD00
DD
DD109
dfx 中有两个 groupx 方法,每次执行完毕 groupx 方法,都会跟着打印 4 次 full gc。每次 gc 时间是:2.17s,2.11s,1.56s,1.80s,1.69s,1.55s,1.58s,1.22s。8 次共耗时13.68s。13.68s 的时候系统好像死掉一样,整个 tomcat 不执行用户动作,用户感觉系统很卡,无法开展实际业务。
通过集算器源代码 com.scudata.util.EnvUtil 发现显示调用了 gc 动作:
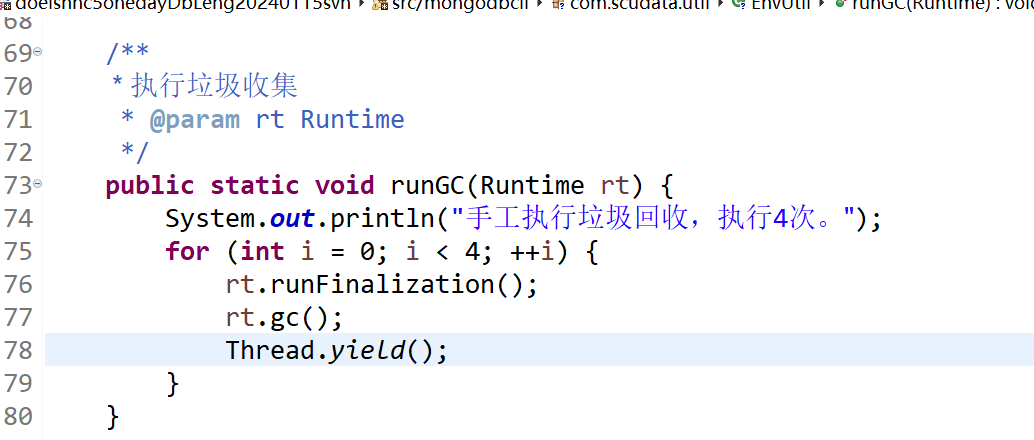
这里有个疑问为什么要执行 4 次 gc 呢?


数据量才 800 条怎么调用 groupx 来计算分组?
groupx 是外存分组,会调用 gc 释放内存来确定内存能够缓存的分组数量。此函数最后一个参数为缓冲区容量,如果指定了容量则不会调用 gc。
分组结果内存能放的下的话应该调用 groups 函数来计算分组。
这个脚本是某个计算逻辑公用的,用户根据不同的业务传递过来不同的表名和分组字段,因为有些业务数据比较多,分组后 600w 记录,所以我把 group 修改成了 groupx,用户点击了 600w 条业务计算任务,调用此 groupx 函数,同样会把 tomcat 搞成假死啊。
还有一个问题,gc 为什么是 4 次 不是 1 次呢?
gc 不是执行一次就能释放的了内存的
那给 groupx 加上 n 参数吧,cs.groupx(x:F,…;y:G…;n),有了 n 则不会调用 gc
是不是带 x 的函数都会有这个问题啊?比如:sortx
是的,sortx 也这样