


(已解决) iselect 函数与有序文件
大佬们,过年好😄 Kung Hey Fat Choy 🙏
关于有序文本文件,有几个问题还得麻烦大佬们指导解惑。
实际场景是有 4500 个 txt 文件,都是 6 列,行数从几千行 (大于 1024 行) 到两万多行不等,需要从每一个 txt 文件中获取满足条件的某一行或者某几行,但这些 txt 文件格式并不规范,从以下截图中可以看到,第一行并不是传统的表头,最后一行也不是需要的数据。但有一个好处是,所有文件都是对第 1 列第 2 列分段有序的,第 1 列按每一天 (除了节假日) 升序,第 2 列从 9 点 30 分开始,每一分钟生成一行数据(上午从 0930-1130,下午从 1300-1500),也就是每天 240 行数据,具体数据请看本帖附件。
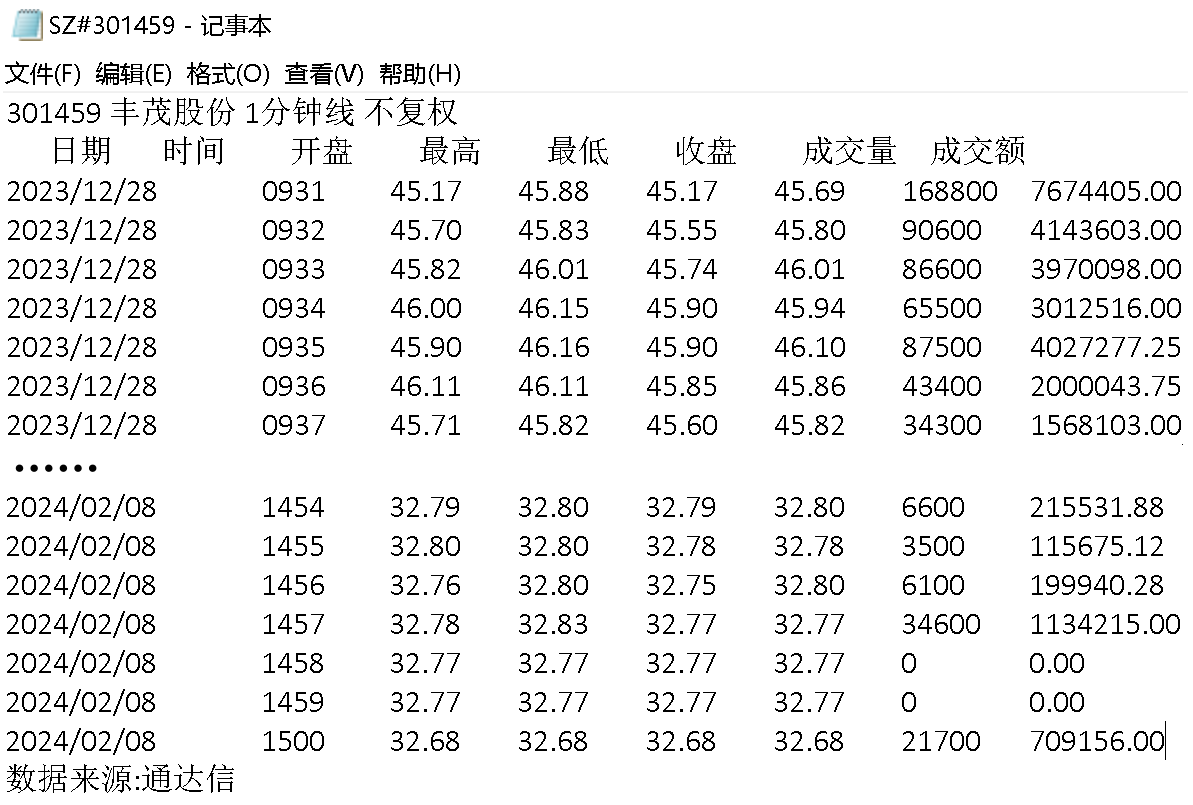
这个查找需求已经解决了,相比较于 VBA 中传统的 OpenTextFile 方法 (耗时 56 秒),或者用 Open Binary Access 方法 (耗时 10 秒左右,运行不稳定,首次运行耗时很长,第二次运行会快很多,猜测也是缓存的影响,这里不追究),SPL 处理 4500 个 txt 耗时 6 秒左右,效率还是很高的。我的问题是在解决过程中发现的。
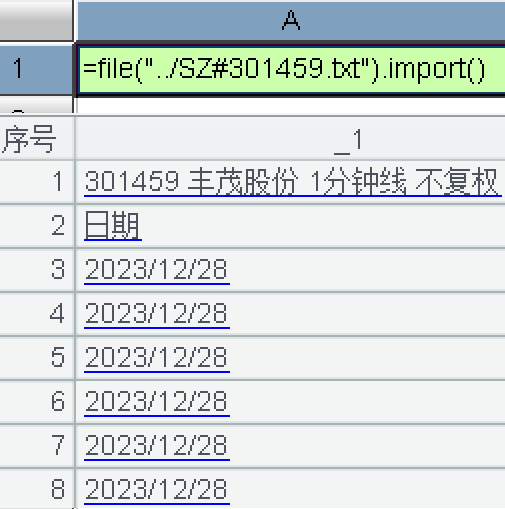
问题 1:像这种首行不是表头的 txt 文件,能否实现按最大列数导入成表格?
目前像这种 txt 用 file(txt).import()或者 import@t() 导入时,只能生成 1 列,如下截图:
除非用 import@w()读成序列的序列,才能把所有有效的列完整的读出来,但读成序列的序列,总有一些用法上的限制。如果是 csv 格式,用 import@c() 或者 import@tc() 时,可以按最大列数读出,如下图所示:
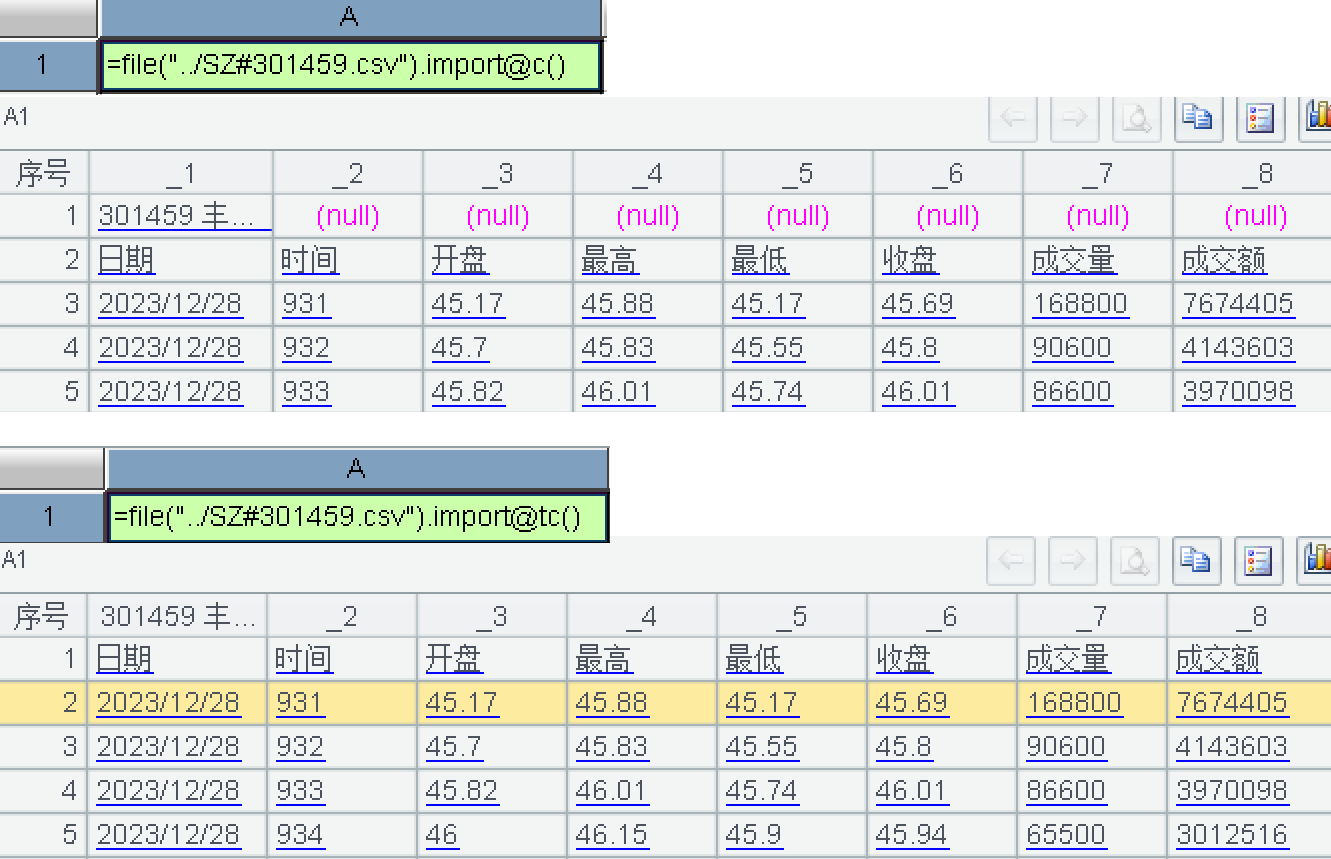
所以,txt 文件在 import 时可否实现跟 csv 文件 import 时一样按最大列数导入成序表?
问题 2:文本文件 (txt,csv) 在用 file().iselect@r 时会出现问题。
如果文本文件对其中的某一字段有序就可以使用 iselect 进行外存二分法查找,结果返回游标。因为 iselect 对有序文件的查找效率很高,所以我把上述 txt 文件掐头去尾后转存成了标准的 txt,csv 和 btx 格式,代码如下:
| A | B | |
| 1 | =file("SZ#301459TXT.txt") | |
| 2 | =file("SZ#301459CSV.csv") | |
| 3 | =file("SZ#301459BTX.btx") | |
| 4 | =file("SZ#301459.txt").import@fw() | |
| 5 | =A4.delete@n([1,-1])(1)(1).split(" ")(2) | |
| 6 | =A1.export@t(E(A4)) | =A1.import@tf() |
| 7 | =A2.export@tc(E(A4)) | =A2.import@tcf() |
| 8 | =A3.export@b(E(A4)) | =A3.import@b() |
然后用 iselect 进行查找,比如,以下语句只要能保证查找值的唯一性,均能正常出结果:
| A | |
| 1 | =file("SZ#301459TXT.txt") |
| 2 | =file("SZ#301459CSV.csv") |
| 3 | =file("SZ#301459BTX.btx") |
| 4 | [2023/12/28,2024/01/11,2024/01/12,2024/01/15,2024/02/06,2024/02/07,2024/02/08] |
| 5 | |
| 6 | 以下 3 种两个字段的单值查找均能出结果 |
| 7 | =A1.iselect@ft("2024/02/080931",#1+#2).fetch() |
| 8 | =A2.iselect@ftc("2024/02/080931",#1+#2).fetch() |
| 9 | =A3.iselect@b("2024/02/080931",#1+#2).fetch() |
| 10 | |
| 11 | 以下 3 种两个字段区间形式多个结果时,都能正常出结果 |
| 12 | =A1.iselect@ft("2023/02/061300":"2024/02/080945",#1+#2).fetch() |
| 13 | =A2.iselect@ftc("2023/02/061300":"2024/02/080945",#1+#2).fetch() |
| 14 | =A3.iselect@b("2023/02/061300":"2024/02/080945",#1+#2).fetch() |
但是 iselect 还有 @r 选项,用于查找值不是唯一值时的场景。此例中因为第 1 列虽然有序,但值不唯一,所以用 @r 选项,此时,不管是单值查找还是区间查找或者序列查找,只有 btx 格式能正常出结果(但 btx 也会有其它问题,行数不够时会报错,请看下文),txt 和 csv 在用 iselect@r 选项时会报错,如下所示:
| A | B | |
| 1 | =file("SZ#301459TXT.txt") | |
| 2 | =file("SZ#301459CSV.csv") | |
| 3 | =file("SZ#301459BTX.btx") | |
| 4 | [2023/12/28,2024/01/11,2024/01/12,2024/01/15,2024/02/06,2024/02/07,2024/02/08] | |
| 5 | ||
| 6 | 以下 3 种单字段的单值查找 @r 时,txt/csv 会报错,btx 正常 | |
| 7 | =A1.iselect@ftr("2024/02/08",#1).fetch() | 报错 |
| 8 | =A2.iselect@ftcr("2024/02/08",#1).fetch() | 报错 |
| 9 | =A3.iselect@br("2024/02/08",#1).fetch() | 结果正常 |
| 10 | ||
| 11 | 以下 3 种单字段区间形式多个结果 @r 选项时,txt/csv 出来的结果不全,btx 正常出结果 | |
| 12 | =A1.iselect@ftr("2023/02/06":"2024/02/08",#1).fetch() | 结果不全 |
| 13 | =A2.iselect@ftcr("2023/02/06":"2024/02/08",#1).fetch() | 结果不全 |
| 14 | =A3.iselect@br("2023/02/06":"2024/02/08",#1).fetch() | 结果正常 |
| 15 | ||
| 16 | 以下 3 种单字段序列形式多个结果 @r 选项时时,txt/csv 会报错,btx 正常 | |
| 17 | =A1.iselect@ftr(A4,#1).fetch() | 报错 |
| 18 | =A2.iselect@ftcr(A4,#1).fetch() | 报错 |
| 19 | =A3.iselect@br(A4,#1).fetch() | 结果正常 |
报错时的截图如下:
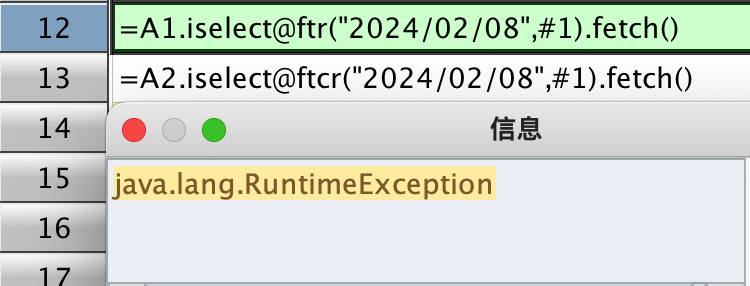
我以为 txt/csv 之所以会报错,有可能是 txt 文件本身来源有问题,于是模拟生成文件测试如下,结果跟上述是一样的,txt、csv 格式在用 iselect@r 时会有问题,猜测可能是 txt、csv 格式不能随意分段或者是分段没有做好?
| A | B | C | |
| 1 | =file(“test1.txt”) | ||
| 2 | =file(“test2.csv”) | ||
| 3 | =file(“test3.btx”) | ||
| 4 | =file(“test4.ctx”) | =A4.create@y(#ID1,#ID2,Amt) | |
| 5 | =8.news(128;get(1):ID1,~:ID2,rand(100):Amt) | ||
| 6 | =A1.export@t(A5) | =A1.import@t() | |
| 7 | =A2.export@tc(A5) | =A2.import@tc() | |
| 8 | =A3.export@b(A5) | =A3.import@b() | |
| 9 | =B4.append@i(A5) | =A4.open() | =B4.import() |
| 10 | =A1.iselect@tr(1:2,#1).fetch() | ||
| 11 | =A1.iselect@tr([1,2],#1).fetch() | ||
| 12 | =A2.iselect@trc(1:2,#1).fetch() | ||
| 13 | =A2.iselect@trc([1,2],#1).fetch() | ||
| 14 | =A3.iselect@br(1:2,#1).fetch() | ||
| 15 | =A3.iselect@br([1,2],#1).fetch() | ||
| 16 | =B4.cursor(;#1>=1&<=2).fetch() |
上述模拟语句中,txt 和 csv 格式在用 iselect@r 时问题一样存在,要么结果不全,要么报错。但发现了另一个问题:
问题 3:btx.iselect() 时,如果 btx 文件的行数小于等于 1024 行就会报错
请注意上述代码格 A5 中,news 之所以写成 8×128=1024 行,就是为了引出 btx 报错的问题,代码格 A14、A15 报错如下,说是 btx 文件格式错误:

只要文件行数大于 1024 行,btx 就不会报错,且能正常出结果,比如变成 1025 行,此时 btx 没有问题,但 txt 和 csv 在用区间形式的参数时 (1:2) 结果不全,请看以下代码格中的 A10 和 A12,但用序列形式的参数时([1,2]),txt 和 csv 出来的结果倒是正常的,请看以下代码格中的 A11 和 A13:
| A | B | C | |
| 1 | =file("test1.txt") | ||
| 2 | =file("test2.csv") | ||
| 3 | =file("test3.btx") | ||
| 4 | =file("test4.ctx") | =A4.create@y(#ID1,#ID2,Amt) | |
| 5 | =5.news(205;get(1):ID1,~:ID2,rand(100):Amt) | ||
| 6 | =A1.export@t(A5) | =A1.import@t() | |
| 7 | =A2.export@tc(A5) | =A2.import@tc() | |
| 8 | =A3.export@b(A5) | =A3.import@b() | |
| 9 | =B4.append@i(A5) | =A4.open() | =B4.import() |
| 10 | =A1.iselect@tr(1:2,#1).fetch() | 结果不全 | |
| 11 | =A1.iselect@tr([1,2],#1).fetch() | 结果正常 | |
| 12 | =A2.iselect@trc(1:2,#1).fetch() | 结果不全 | |
| 13 | =A2.iselect@trc([1,2],#1).fetch() | 结果正常 | |
| 14 | =A3.iselect@br(1:2,#1).fetch() | 结果正常 | |
| 15 | =A3.iselect@br([1,2],#1).fetch() | 结果正常 | |
| 16 | =B4.cursor(;#1>=1 && #1<=2).fetch() | 结果正常 |
以上 3 个问题恳请大佬们得闲时给予帮助,谢谢!
附件如下:


文本和 csv 文件的 iselect 的 bug 已修复。
集文件如果数据量少于 1024 则不会采用分段存储,这时无法用二分法查找,只有有分段信息的集文件才会跳着读,才能利用有序属性进行二分查找。
大佬,开工大吉🙏 啥也不说了,等更新,谢谢!!😄 😄
祝新年进步,工资大涨🙏 😄
不分段集文件不再抛出异常,改成按顺序查找
程序已更新,请前往下载贴中下载最新的 esproc-bin.jar 文件。
感谢 leavedy 大佬,感谢 ddszm 大佬🙏 🙏
帖子中问题 2 和问题 3 关于 iselect 对有序文本文件 (txt,csv,btx) 的二分查找已完美解决,it works like charm,真特么 666👍 👍 👍
另外,帖子中的问题 1,对非规范格式的 txt 文件的读取有没可能整一下😄 恳请老贼、leavedy 大佬再看看🙏 🙏
问题 1:首行不是表头的 txt 文件在 import 时可不可以跟 csv 读取时一样,自动识别最大有效列数?