


求助: 非常规分类统计
大佬们,下午好,我有一个非常规分类汇总问题想请大佬们指点一下,看有没有提速的可能?
这种统计需求是我在最近三年内第三次碰到,以前都是用递归分组解决,但效率奇慢无比。我尝试用 spl 写了一下,模拟数据和结果如下所示,可复制使用:
| A | B | |
| 1 | 编号 | 金额 |
| 2 | AAA | 1 |
| 3 | AAA/BBB | 2 |
| 4 | BBB/CCC | 5 |
| 5 | CCC | 5 |
| 6 | DDD/FFF | 10 |
| 7 | EEE | 10 |
| 8 | FFF | 4 |
| 9 | EEE/AAA | 3 |
| 10 | ||
| 11 | ||
| 12 | =[A1:B9].record(2) | =R=create(# 编号, 金额) |
| 13 | for A12 | =t=A13. 编号.split("/") |
| 14 | >R.delete(s=R.select(t.cor(pos( 编号,~)))) | |
| 15 | =a=s.conj(编号.split("/")).insert(0,t).id().concat("/") | |
| 16 | =b=s.sum(金额)+A13. 金额 | |
| 17 | >R.insert(,a,b) |
数据中的编号实际上是一些收款编号,因为每一次收款时都是一笔总数包含不同的收款编号用于描述某一项对应的清账事项,要求所有的编号只要有交集就要汇总在一起,包括对应的金额也要汇总。上述代码中 B12 就是当前数据的最终汇总结果,如下所示:
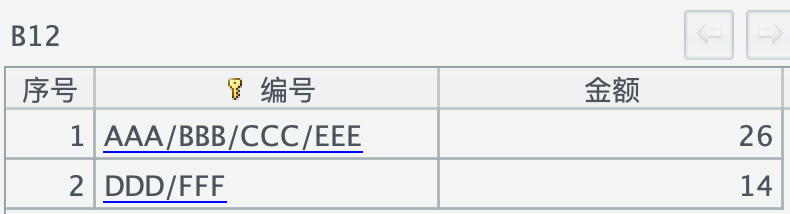
描述一下合并的逻辑 (有点啰嗦哈),比如,AAA 和 AAA/BBB 有交集,所以要合并成 AAA/BBB,然后这个结果和 A4 格子中的 BBB/CCC 有交集,合并成 AAA/BBB/CCC,同理合并完 A5 中的 CCC,继续遍历…,特别地 A7 中的 EEE,当遍历至 A7 时,此时的 EEE 跟任何已遍历的都没有交集,在结果中单独呈现,但当遍历到最后的 EEE/AAA 时,就有交集了,此时所有跟 EEE/AAA 有交集的都要合并,得到 AAA/BBB/CCC/EEE,其它的编号跟此逻辑一样,如果源数据中最后增加一条 FFF/AAA,那此时的最终结果就会只剩一条,所有的都有交集,合并后变成 AAA/BBB/CCC/DDD/EEE/FFF。
我的想法是,事先创建一个结果表,也就是 B12 代码格中的 R,然后遍历源数据中的每一个编号,用当前编号去结果表中选出跟其有交集的结果,再合并汇总。这样的话,如果结果集 R 不大,也就是源数据中能形成交集的行很多,那在 R 中 select 时,也就是 B14 代码格的速度不至于很慢。但是,有一种极端情况,如果源数据几乎没有交集,此时结果集很大,那 B14 处的 select 全表遍历的次数很大,速度就会明显减慢,比如 1 万行源数据,那这样的遍历次数可能会倍数级增大(n/2*n),时间复杂度会很高。我曾想在 B14 处用 select@b,所以把结果集 R 用 insert(,a,b) 省略一参使其按主键有序插入,但像这样的文本包含查找又用不上二分法,很是纠结。
所以,恳请大佬们得闲时指点一下,
1、有没有其他算法或者思路来解决这个问题?
2、select 时如果碰到文本包含或者 like() 这种返回 true/false 的不能使用二分法时要如何避免全表遍历?
谢谢!


若不能进行二分,建议通过聚合、剔除等,尽量减少遍历数,如:将编号字段 split、sort 后,按照第一个元素或最后一个元素进行 group 分组聚合