


(已解决) 关于函数 group@s 和 groups
大佬们,周末好🙏 关于函数 group@s 我有点疑问,因为纠结不过,还是发帖求助一下。
group@s 我目前了解到的有以下作用:
1、对序列进行内存排序,比如,序列.group@s(),括号里不用带参数。可以代替 sort 函数实现内存排序,在序列重复值较多时,可以得到较好的排序性能;
2、对序表中的某个字段进行去重和排序,比如,序表.group@s(字段名;),此时括号里有分号,且分号后面不带参数,就可以得到该字段下的经去重排序后的只有一列的序表。如果写成序表.group@s(字段),此时括号里没有分号,得到的就是按该字段排序后的序表;
3、实现前半有序的排序,比如,游标.group@sq(字段 1; 字段 2),此时括号里的两个参数用分号隔开,表示在字段 1 有序的前提下,按字段 2 排序,且不用聚合计算。
上述 3 项功能其实都是排序,且在某些使用场景下会有较好的性能,这很好用。
但 group 函数在带有 @s 选项时,有一个主要的用途是累计聚合,官方函数文档里说的是 "以累计方式计算",这样一来,group@s 和 groups 具有了相同的功能,我纠结的点是在聚合计算后,还能不能再对这个聚合值进行进一步处理?在函数 groups 里,聚合之后的值是可以进一步计算的,但是,在 group@s 中,聚合后的值不能进一步处理。实际上,group 函数可以用波浪线 ~ 来引用每一个分组,且可以使用 ~.fx() 来处理,但加了 @s 选项后就不能引用波浪线来作为每一个分组,此时只能用聚合函数,且只能聚合一次。举个简单的例子如下,要统计某学校一年级 7 个班的成绩,计算每一个班级的参考人数,及格人数,及格率,优秀人数和优秀率,模拟数据可以通过如下语句获取:
| A | |
| 1 | =7.news(52+rand(10);left(uuid(),5): 姓名,format("一 (%s) 班",get(1)): 班级,rand(100): 成绩) |
模拟数据的部分截图如下,就 3 个字段,姓名、班级和成绩,共 7 个班级:
这种统计问题用 groups 可以很方便实现,效果如下:
| A | |
| 1 | =7.news(52+rand(10);left(uuid(),5): 姓名,format("一 (%s) 班",get(1)): 班级,rand(100): 成绩) |
| 2 | =A1.groups(班级;sum(1): 参考人数,count(成绩 >=60): 及格人数,format("%.2f%%", 及格人数 /sum(1)*100): 及格率) |
代码格 A2 运行结果如下所示:
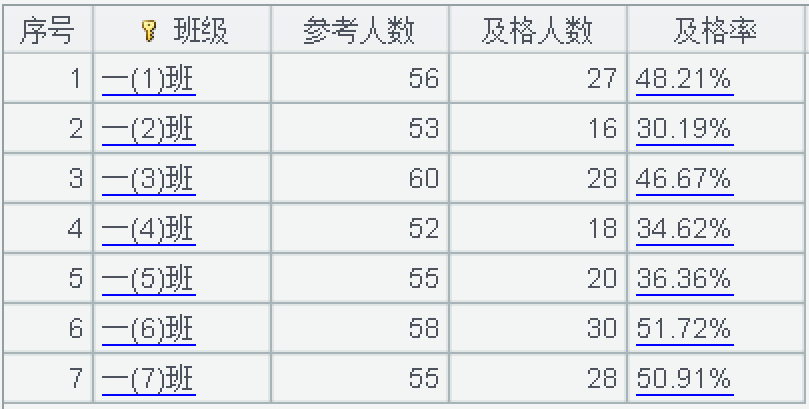
观察代码格 A2 中的写法,第三个聚合值及格率是经过 5 次处理得到的,首先是用 sum(1) 聚合总人数,然后引用了第 2 个计算结果及格人数,注意这里可以引用前面计算好的结果,相除后再乘以 100,然后再用 format 函数把相除后的值变成百分比显示,之所以把这个过程描述的那么啰嗦,是为了说明在 groups 里,是可以对聚合结果作进一步处理的。
既然在 groups 里可以引用前面计算好的聚合结果,我就想偷懒,不想每次都写聚合函数,假如有几十个聚合指标,是不是要写几十次的聚合函数?于是我想到了变量名,上述写法加上变量名,令 t=sum(1),q=count(成绩 >=60),然后,在计算及格率时就引用成 t/q,如下:
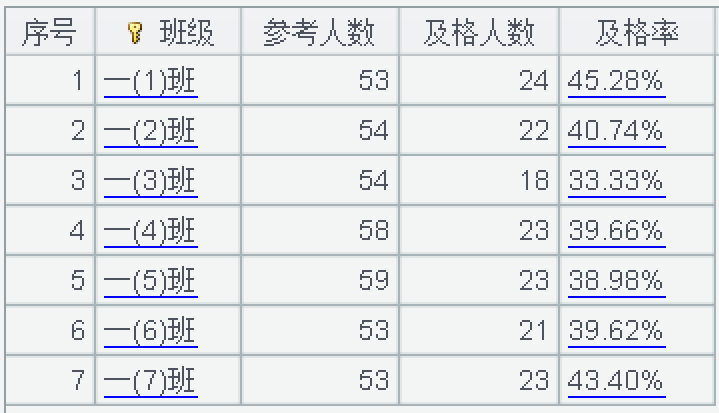
=A1.groups(班级;t=sum(1):参考人数,q=count(成绩>=60):及格人数,format("%.2f%%",q/t*100):及格率)
但是语句这样写结果跑不出来,说是不能识别表达式 q,我又改成了 "及格人数 / 参考人数",同样也是报错,说不能识别表达式及格人数。我琢磨了一下,因为 groups 里需要用聚合函数,而引用的 t/q,只是一个单值,并不存在聚合,报错是正常的。那为啥上述代码格 A2 引用了及格人数却没有报错,原因是一起绑定了一个聚合值 sum(1),同样是对聚合值 sum(1) 作进一步处理计算,所以没抛出异常。这样的话,只要存在聚合表达式就可以正常使用变量名或者前面已经计算好的字段名,于是,换成 (q+sum(0))/t,这样就可以出结果了:
| A | |
| 1 | =7.news(52+rand(10);left(uuid(),5): 姓名,format("一 (%s) 班",get(1)): 班级,rand(100): 成绩) |
| 2 | =A1.groups(班级;t=sum(1): 参考人数,q=count(成绩 >=60): 及格人数,format("%.2f%%",(q+sum(0))/t*100): 及格率) |
(以下结果是随机数生成的,所以每次运行结果都会不同)
疑问 1:这个疑问有点异想天开了,我想 groups 里能不能在不带聚合函数的情况下引用计算好的字段或者变量,比如上面提到的,写成 q/t,或者 及格人数 / 参考人数,而不是 (q+sum(0))/t 必须带上聚合函数。但这明显不符合 groups 分组聚合的定义。
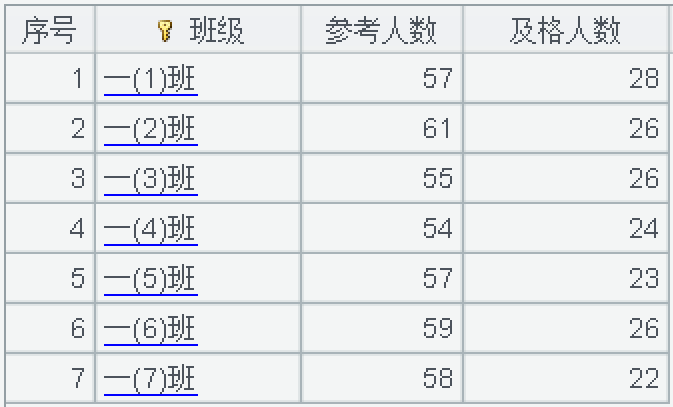
前面写那么多,目的是跟 group@s 作对比,既然 group@s 带有聚合功能,那是不是可以把上述语句中的 groups 换成 group@s,测试结果是不行的,因为在 group@s 里,不能对聚合值进行进一步计算。比如,写成单个聚合表达式是没有问题的,跟 groups 没有两样:
| A | |
| 1 | =7.news(52+rand(10);left(uuid(),5): 姓名,format("一 (%s) 班",get(1)): 班级,rand(100): 成绩) |
| 2 | =A1.group@s(班级;sum(1): 参考人数,count(成绩 >=60): 及格人数 ) |
但是,只要对聚合值进一步计算就会出错,也不能引用前面计算好的字段。比如,把上述 sum(1)+100,及格人数聚合表达式中除以 60,能出结果,但这个结果是错的,聚合表达式返回的是某一行的值,或者只是某个单值,并未聚合:
| A | |
| 1 | =7.news(52+rand(10);left(uuid(),5): 姓名,format("一 (%s) 班",get(1)): 班级,rand(100): 成绩) |
| 2 | =A1.group@s(班级;sum(1)+100: 参考人数,count(成绩 >=60)/60: 及格人数 ) |
以下结果是有问题的:
如果此时引用成 "count(成绩 >=60)/ 参考人数",就会抛出错误,即使包含了聚合表达式,也不能识别表达式 "参考人数"。
另外,group 时不加 @s 选项,直接 group,用波浪线引用每一个分组,如下:
| A | |
| 1 | =7.news(52+rand(10);left(uuid(),5): 姓名,format("一 (%s) 班",get(1)): 班级,rand(100): 成绩) |
| 2 | =A1.group(班级;t=~.sum(1): 参考人数,q=~.count(成绩 >=60): 及格人数,format("%.2f%%",q/t*100): 及格率 ) |
| 3 | =A1.group(班级;t=~.sum(1): 参考人数,q=~.count(成绩 >=60): 及格人数,format("%.2f%%", 及格人数 / 参考人数 *100): 及格率 ) |
上述代码格中 A2 是能出正确结果的,也就是说在 group 中,可以引用变量名称。
但 A3 是会抛出错误 "不能识别的表达式及格人数",也就是说此时不可以引用前面计算好的字段。
所以,疑问 2:
group 时,group() 括号里可否引用计算好的字段名?
group@s 里的聚合功能可否跟 groups 函数里的聚合功能一致,实现对聚合值的进一步处理?
上述写法和疑问难免偏颇,恳请大佬们得闲时给予帮助指导,谢谢!


groups 就是 group+summary,分组同时聚合。group 则只是分组,没有 s 的动作。
本来并不需要 group@s。
对于内存小数据确实是这样,但面对游标大数据时,就会有些麻烦事了。
groups 会立即计算,会把结果算全算出来。有序游标再分组的结果集有可能很大,常常希望逐步算出来,这就要写成 cs.group(…).new(用 ~ 的写法) 来算,这样种要保持分组子集的计算速度比较慢,有些常见运算可以用累积方法计算没必要保持分组子集。
所以增加了 cs.group@s 应对这种情况,它是在游标 group 上附加的功能,所以加到 cs.group 的选项上。
对于内存表,group@s 是多余的,没有必要。但对于游标来讲,cs.group@s 和 cs.groups 是不一样的,两者都有必要。
而之所以对内存表也提供 group@s,是为了调试方便而兼容游标。编写游标运算时常常会先用小数据调试,只要前面的游标上多加一个.fetch()就可以读成内存表,调试时可以看到数据(游标本身无法观察),调试通了换回大数据时,把.fetch() 去掉,其它代码基本上可以不变。
分组运算时还看不到目标结果集,group 时不能引用目标字段。groups 能对聚合值的进一步处理,是刻意拆解了表达式后多做了一步 new,而且 groups 只有简单聚合式,拆解也容易,group 里用 ~ 写的表达式五花八门,很难说能不能正确拆出来。至于 group@s,约定只有简单聚合,可以拆解和加做 new,但相对没那么常用了,目前没有费劲做这个了(所以当它不是简单聚合式时也会有问题),必要时可以自己去 new/derive。本来,group@s 也是为了游标上简单聚合运算的提速而补充的,复杂动作还是自己用 group+~ 去对付了。
对于内存运算,就不要用 group@s。
至于 group@sq,应该是 @qs,@s 是 @q 的子选项,这时候它表示排序 (sort)。和前面说的 @s 没有关系。它也是针对游标的,如果是内存数据,直接 sort 就行了,没必要这么麻烦,前半是不是有序对于快速排序算法来讲区别很小。
感谢老贼的悉心指导和解惑🙏 您的回复读了好几遍,对分组有了新的认识和收获。我再捋捋消化一下。
刚开始有点学会 spl 的时候,因为好玩新奇,上手很快,学了点皮毛就能平趟日常工作,路子有点野,到处吹牛逼😄 ,
现在的感觉是越学越不懂了,spl 的知识点很多,博大精深,如果不花点心思在上面,很难掌握精华部分。
就像最后提及的 group@sq,正确写法应该是 group@qs,要不是您说,还不知道 s 是 q 的子选项。
我看函数文档里写的是 @sq,也没太在意,但您写的性能优化系列里写的确实是 @qs,想不到有这样的区别。
最近看得多,想得多,问题也多,感觉自己啥也不是,需要突破一层黑障才能见山是山。
可能学习的方法和思考的角度也有问题……
Thank you for your time. Peace!
选项没有次序,写成 @sq 还是 @qs 对实际执行并没有区别,只是概念理解上不同
cs.group@s 改成了也跟 groups 一样支持复杂聚合表达式。
谢谢 leavedy 大佬,谢谢老贼🙏 🙏 spl 666 👍 👍 👍
recap:
游标.group@s(字段,…; 复杂聚合表达式) 结果返回游标,保持游标
序表 / 游标.groups(字段,…; 复杂聚合表达式) 结果返回序表,进内存