


(已解决) top/ptop 有重复排名时的 TopN
TopN 是很常见的一种数据统计,诸如班级、年级成绩的 TopN,月度、季度、年度销量的 TopN…等等不胜枚举。常见的数据呈现可以像以下截图一样布局,最好的几种和其它,或者每一类的 TopN 和 Others:
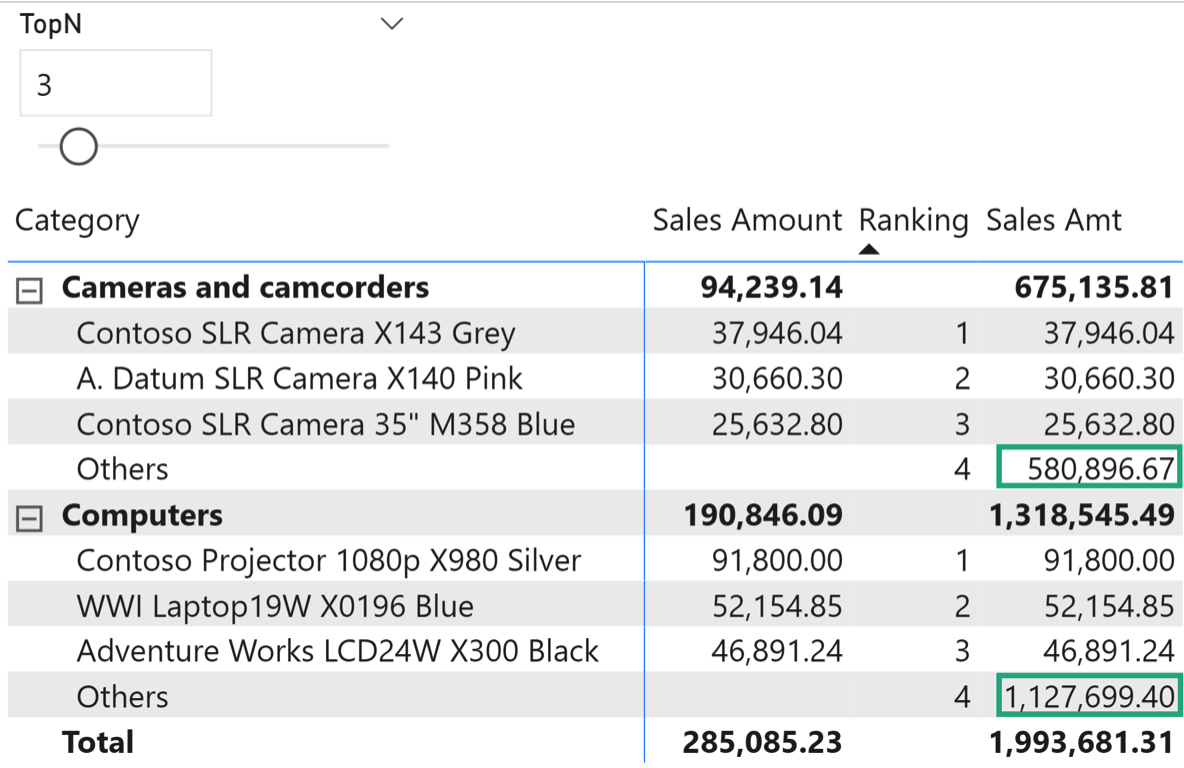
这种数据呈现的关键是筛选出 TopN,市面上的编程语言几乎都有类似的语法或者函数,比如 SQL 里的 select top n *,或者像 DAX 里的 TopN 函数,这些语句或者函数在统计对象没有重复值时都能很正常地工作,得到预期的结果,但当统计对象有重复值出现时,这类 TopN 只是获取了前 N 条记录,是前 n 条,并不是前 n 名,包括 SPL 里的 top 函数,其结果获取跟市面上的其它编程语言几乎没有两样。那成绩总归会有一样,销冠也不可能永远只有一个,就像鸡蛋也有可能出现双黄蛋,举个简单的例子如下,获取每一个类别的按金额排名的前两名:
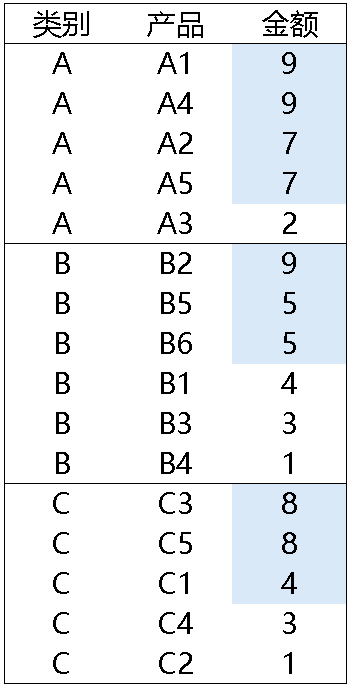
从上图中可以发现,前几名的金额都是有重复的,比如类别 A,按中国式排名,排名前两名的金额会有 4 条记录,而用 top 函数获取到的 TOP2 结果,只是排序后靠前的两条记录:
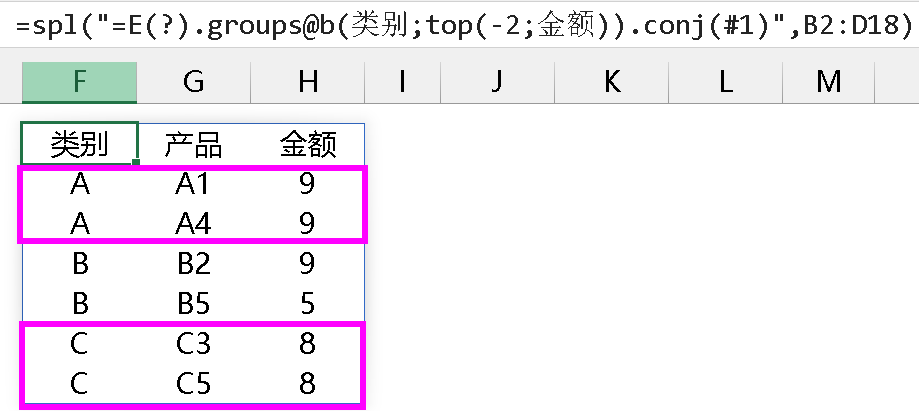
如果要获取到每一类排名前两名的记录,必须要换写法,我能想到的有以下两种写法:
第一种写法:先按金额用 rank@zi() 中式排名,再筛选出名次 <3 的记录:
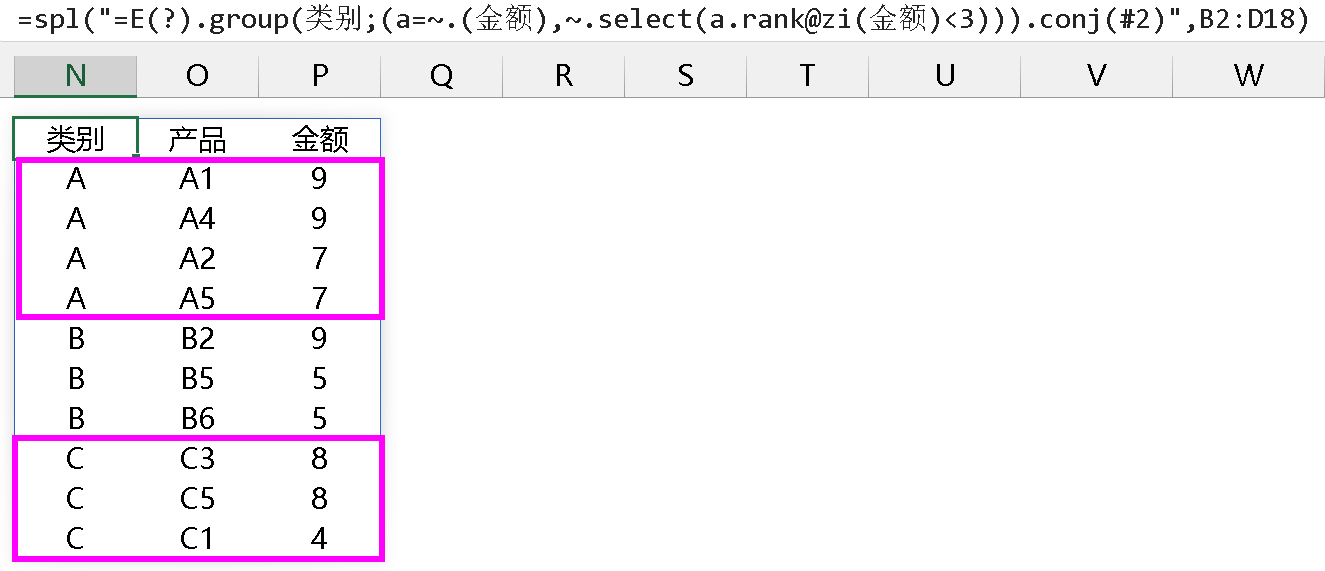
第二种方法:先按金额 group 一次,相当于实现了去重,再用 top 函数:
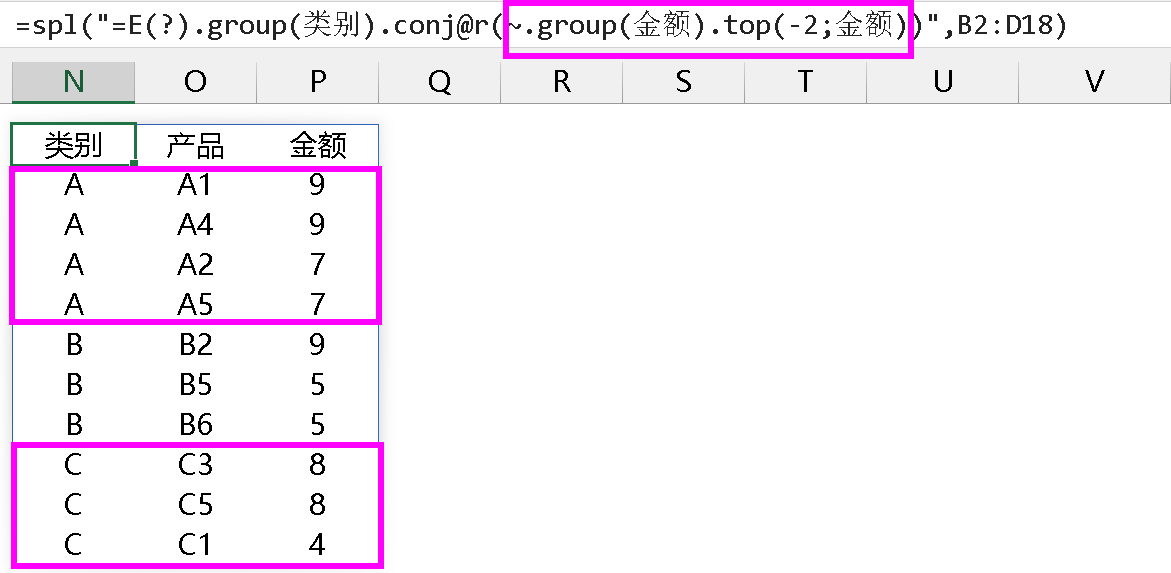
就实现本帖中的需求来说,以上两种写法分不出孰好孰坏,如果值的重复度高,group 会比 rank@i 要高效,如果值的重复度很低或者几乎没有重复,那 rank@i 会比 group 略快,这个结论或许有点草率,我只做了一次测试,结论不免武断。先不管运行效率,光从写法上来说,这两种写法都是多了一步,没有直接用 top 来的简洁,但直接用 top 并不能达到预期的结果,这也是比较纠结的一个点,且市面上几乎所有的编程语言对 topn 的处理都是同样的逻辑,获取的是前 n 条记录。
所以,我在想,spl 的 top 函数能否跟 rank 函数一样实现中式排名和美式排名的两种效果,比如 rank 时碰见相同的排名会跳跃,变成 11335(美式排名),而 rank@i 去重后排名,就不会跳跃,变成 11223(中式排名),同理,top 时,只获取前 n 条记录,而 top@n 时,获取排名前 n 的记录。如果能实现这样的用法,那在处理这一类统计时,语法、写法、用法都会简约不少。我只是从一个使用者的角度想到了这样的函数需求,很可能是我想多了(哈哈,言外之意…就我屁事多,这需求那选项…),但平时类似这样的数据统计需求倒是挺常见的。
同样,还有一个 ptop 函数,函数文档大概是这样说的,“返回序列中最值成员所处的位置,当最值有重复时,列出最值所在的全部位置”,这里跟预想的也有出入,也涉及到一个并列排名时的问题。
恳请大佬们得闲时给予帮助,如何获取这种重复排名时符合要求的所有 TopN,谢谢!
无意中发现了 top 函数的另一种用法,若不是这篇文章 3.7 组内第一条 / 最后一条 中说 top 函数的第二参数可以是常数,还不知道有这样的写法,官方函数文档中并未提及 top 函数的 2 参可以是常数,常数表示不排序,然后看 1 参的正负,正数表示前 n 个记录 firstN,负数表示后 n 个记录 lastN,这个用法挺好。但需要注意两点,第 1 点,2 参作为常数时,只能用 >=0 的数,才能返回预期结果,如果用负数,结果会比较凌乱,难以猜测,所以帖子中所说的常数应该是非负数。第 2 点,top 函数第 2 参写成常数在 group 分组聚合中使用时,参数中间用逗号或者分号隔开,即 top(±1,0) 或者 top(±1;0) 都是有效的,如果在序列或者序表中单独使用时只能写成用分号隔开的写法,即 序列.top(±1;0) 或者序表.top(±1;0)。这是逛论坛看帖子的意外收获。


谢谢给出的建议,top 将增加相应的选项实现按排名方式取前几名的功能。
谢谢大佬,谢谢 SPL🙏 建议能被采纳是我的荣幸。
用 win-win 这个词似乎不合适,更多的是成全了我的方便。
当然,免不了给大佬们带去额外的工作量,见谅🙏
希望没给你们添乱(有点过于热情了😄 )
A.ptop(n,x)/A.top() 中分别增加了以下选项:
@ r, 美式排名后取前 n 名;
@ i, 中式排名后取前 n 名。
请前往下载贴中下载最新的 jar 文件
谢谢 SPL!
diao 炸天,遥遥领先👍 👍 👍 😄 😄 😄