


程序设计习题 第 11 章 大数据
11.1 大数据和游标
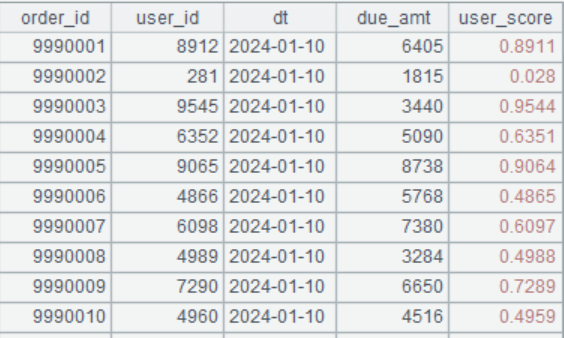
1. 用程序生成一份大文件,形如下图。要求order_id有序且唯一,user_id随机且有重复,dt有序,due_amt随机,user_scoer取0-1之间的随机值。同一个user对应相同的user_score。
文件命名为”order_data.csv”
2. 对上一题生成的文件”order_data.csv”创建游标
(1)从游标中获取100条记录
(2)继续从游标中获取100条记录,观察order_id的变化
(3)继续从游标中取数,直至dt值有变化时停止,观察数据变化
3. ”order_data.csv”读成游标,统计文件中有多少条记录并对due_amt求和
11.2 游标上的函数
本节习题所用数据为”order_data.csv”
1. 用文件”order_data.csv”创建游标
(1)获取100条记录
(2)跳过10000记录
(3)再获取100条记录
(4)关闭游标
2. 统计数据中due_amt的平均值和最大值
3. 统计有多少个用户
4. 查询所有的用户编号
5. 统计数据中每个用户的订单数和汇总金额(due_amt)
6. 筛选出due_amt在8000以上的订单,然后按用户统计订单数和汇总金额(due_amt)
7. 用derive()添加字段user_level,根据分数将用户划分为不同等级,写入”order_data.csv”。user_score超过0.8为A级,0.6-0.8为B级,低于0.6的为C级。
8. 对于不同等级的用户,给予不同的优惠,A,B,C级依次的优惠率为0.1,0.05,0.02,按月份统计优惠金额超过500的订单总金额和订单数量。
9. 把金额在 5000 以上订单上增加一个优惠金额字段后写入另一个文件
11.3 有序游标
本节习题所用数据为”order_data.csv”
1. 将订单按照日期分组,取前3组记录
2. 统计每天中订单金额最多的那个用户的订单额和订单数
11.4 大游标
本节习题所用数据为”order_data.csv”
1. 将数据按照user_score从高到低排序,取前100条
2. 查看订单金额(due_amt)最高的3个订单
3. 对user_id和due_amt分组,统计每组的订单数,再筛选出订单数大于3的分组统计总金额
4. 有员工信息表employee.xlsx与员工工资表salary.xlsx,主键都是Eid,部分数据如下:
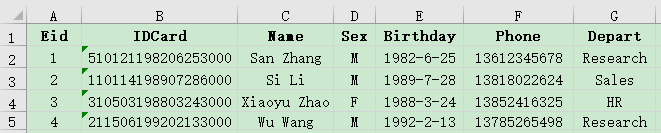
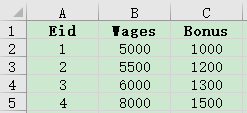
请使用大连接,将员工的基本信息和工资信息连接到一起
参考答案
11.1 大数据和游标
1.
A |
B |
|
1 |
for 0,999 |
=10000.new(A1*10000+~:order_id,1+rand(10000):user_id,date(now())-1000+A1:dt,1+rand(10000):due_amt,(user_id-1)/10000:user_score) |
2 |
=B1.select(rand()>=0.01) |
|
3 |
>file("C:/Users/29636/Desktop/tmp/order_data.csv").export@act(B2) |
2.
A |
|
1 |
=file("C:/Users/29636/Desktop/tmp/order_data.csv").cursor@tc() |
2 |
=A1.fetch(100) |
3 |
=A1.fetch(100) |
4 |
=A1.fetch(;dt) |
3.
A |
B |
C |
|
1 |
=file("order_data.csv").cursor@tc() |
0 |
0 |
2 |
for A1,10000 |
>B1+=A2.len() |
|
3 |
>C1+=A2.sum(due_amt) |
11.2 游标上的函数
1.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.fetch(100) |
3 |
=A1.skip(10000) |
4 |
=A1.fetch(100) |
5 |
>A1.close() |
2.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.total(avg(due_amt),max(due_amt)) |
3.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.total(icount(user_id)) |
4.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.groups(user_id) |
5.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.groups(user_id;count(~):order_count,sum(due_amt):sum_amt) |
6.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.select(due_amt>=8000) |
3 |
=A2.groups(user_id;count(~):order_count,sum(due_amt):sum_amt) |
7.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.derive(if(user_score>=0.8:"A",user_score<0.6:"C";"B"):user_level) |
3 |
=file("C:/Users/29636/Desktop/tmp/order_data.csv").export@tc(A2) |
8.
A |
|
1 |
[A,B,C] |
2 |
[0.1,0.05,0.02] |
3 |
=A1.new(~:user_level,A2(#):discount).keys(user_level) |
4 |
=file("order_data.csv").cursor@tc() |
5 |
=A4.switch(user_level,A3).select(user_level.discount*due_amt>500) |
6 |
=A5.groups(month@y(dt):ym;sum(due_amt):S,count(due_amt):C) |
9.
A |
|
1 |
[A,B,C] |
2 |
[0.1,0.05,0.02] |
3 |
=A1.new(~:user_level,A2(#):discount).keys(user_level) |
4 |
=file("C:/Users/29636/Desktop/tmp/order_data.csv").cursor@tc() |
5 |
=A4.select(due_amt>5000) |
6 |
=A5.join(user_level,A3,discount:dis_amt).run(dis_amt=due_amt*dis_amt) |
7 |
>file("C:/Users/29636/Desktop/tmp/data.csv").export@ct(A6) |
11.3 有序游标
1.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.group(dt) |
3 |
=A2.fetch(3) |
2.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.group(dt) |
3 |
=A2.(~.groups(user_id;sum(due_amt):S,count(due_amt):C).maxp@a(S)) |
4 |
=A3.conj().fetch() |
11.4 大游标
1.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.sortx(-user_score) |
3 |
=A2.fetch(1000) |
2.
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.total(top(3;-due_amt)) |
3.
A |
|
1 |
=file("order_data.csv").cursor@tc() |
2 |
=A1.groupx(user_id,due_amt;count(1):C) |
3 |
=A2.select(C>3).total(sum(C*due_amt)) |
4.
A |
|
1 |
=file("employee.xlsx").cursor@t().sortx(Eid) |
2 |
=file("salary.xlsx").cursor@t().sortx(Eid) |
3 |
=joinx(A1:emp,Eid;A2:salary,Eid) |
4 |
=A3.new(emp.Eid,emp.IDCard,emp.Name,emp.Sex,emp.Phone,emp.Depart,salary.Wages,salary.Bonus) |
5 |
=A4.fetch(100) |


英文版